사용할 데이터셋
Iowa Liquor Sales (출처 : kaggle)
- 2012년 1월 1일부터 2017년 10월 31일까지 아이오와 클래스 'E' 주류 면허 소지자의 제품 및 구매날짜, 구매정보 포함 (상점 수준에서 개별 제품의 판매량 분석 가능)
데이터 분석가가 인사이트를 제공하는 과정 및 사용할 tool

Apache Spark

분산 클러스터란?
시스템의 전반적인 성능을 향상시키기 위해 계산 부하량을 여러 노드에서 분담하여 병렬처리하도록 구성하는 방식
Spark의 구조
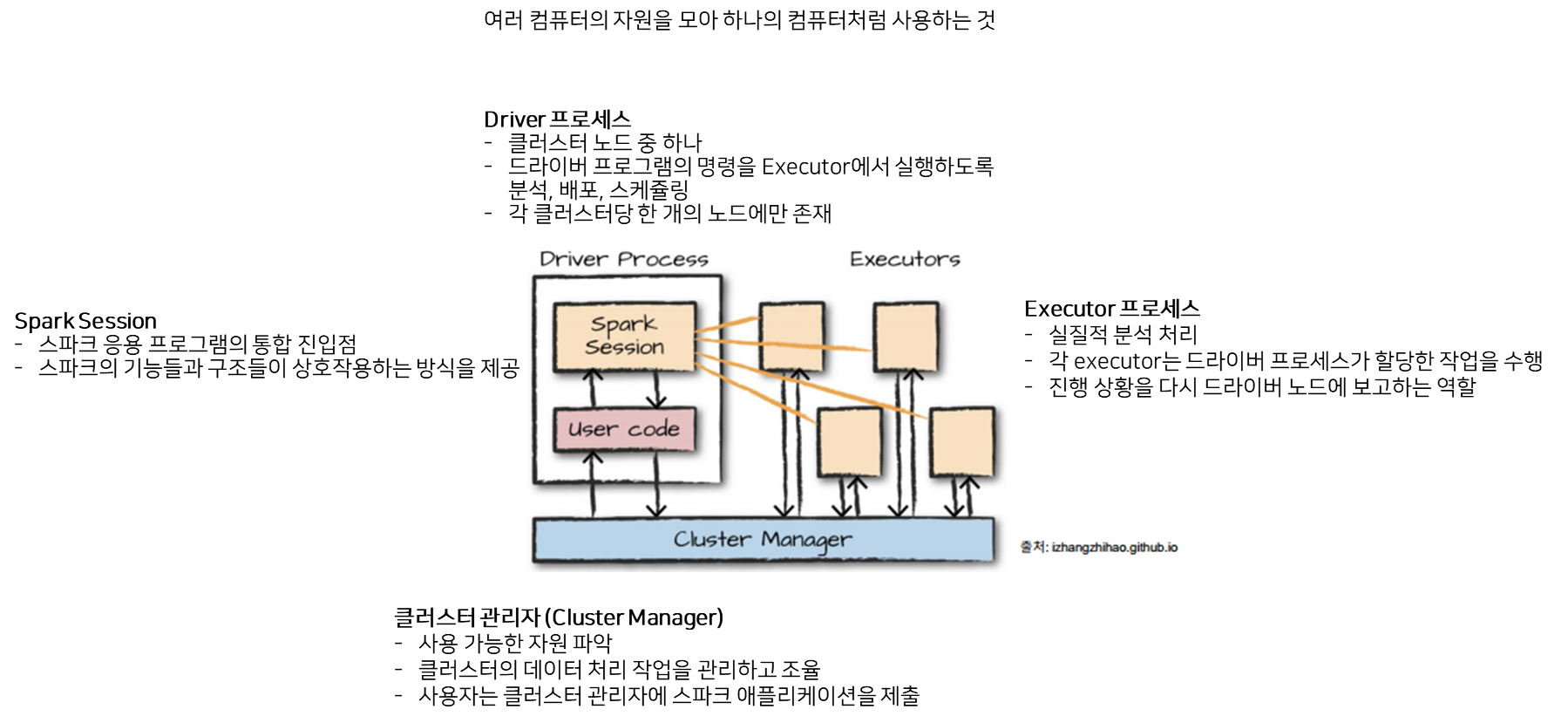
데이터 처리 방식
(1) Partition
: 모든 Executor가 병렬로 작업을 수행할 수 있도록 '파티션'이라고 불리는 청크 단위로 데이터를 분할 (클러스터의 물리적 머신에 존재하는 row의 집합)
→ Spark의 병렬성은 파티션과 익스큐터의 개수로 결정됨
(2) Transformation : Spark의 핵심 데이터 구조는 불변성을 가짐
→ 변경하고자 할 때, 변경 방법을 Spark에 알려줌 > 논리적 실행 계획 세움 (실제 연산은 no)
(3) Lazy Evaluation & Action
- Lazy Evaluation : 특정 연산 명령이 내려진 즉시 데이터를 수정하지 않고, 원시 데이터에 적용할 트랜스포메이션만 실행 (액션 전까지 전체 데이터 흐름을 최적화하는 강점)
- Action : 실제 연산을 수행하기 위한 사용자 명령 (트랜스포메이션으로부터 결과를 계산하도록 지시)
스파크의 카탈리스트
- 트랜스포메이션을 적용할 때, 스파크 SQL은 논리 계획이 담긴 트리 그래프를 생성
- 해당 Optimizaer에 의해 최적의 논리를 받아와 데이터를 반환해주기 때문에 성능이 더 좋음
- 논리 계획 4단계
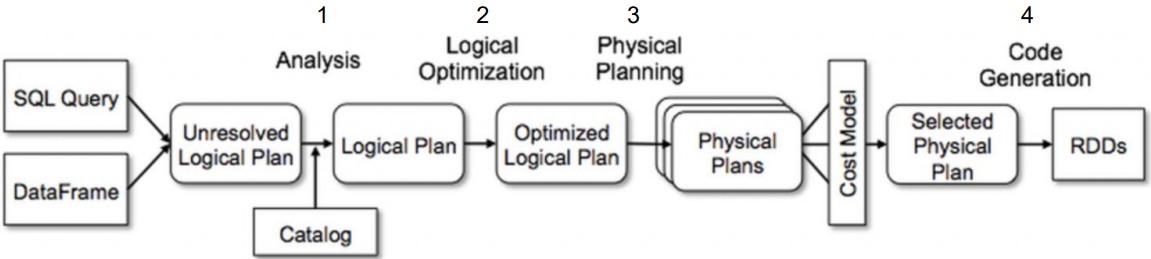
카탈리스트의 장점
- Spark에서 Partition은 부분으로 나눈다는 의미
- 데이터를 Shuffling하고 Partition하여 나뉜 데이터에서 연산을 처리하는 경우, 네트워크 연산(node들의 통신) 발생
- 연산 속도는 인메모리 >> 디스크 I/O >> 네트워크 순으로 빠름
- 그런데 shuffling은 네트워크 연산이기 때문에 앞에서 데이터가 어느 정도 정리가 된 후에 해야 함
(데이터를 어느 정도 정리하는 과정을 카랄리스트가 계획적으로 자동 최적화)
Pyspark
: Python환경에서 Apache Spark를 사용할 수 있는 인터페이스 (즉, Spark용 API)
(Spark는 원래 Java기반 인터페이스)
Pyspark의 기능 및 라이브러리
- SparkSQL and DataFrames
- Pandas API on Spark
- Pandas API를 지원하여 Pandas와 같은 문법을 사용할 수 있다는 장점
- Structured Streaming
- Spark SQL엔진에 구축된 스트리밍 처리 엔진
- 정적 데이터에 배치 계산을 하는 것과 같은 방식으로 스트리밍 계산을 표현할 수 있는 장점
- Machine Learning
- 데이터 병렬 처리 방법론을 활용하여 모델링 가능
