이번 포스팅이 진행의 마지막이 되길 바라며... 학습을 진행해본다!
train_CNN_RNN.py
def bring_data_from_directory():
datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = datagen.flow_from_directory(
train_dir,
target_size=(224, 224),
batch_size=batch_size,
class_mode='categorical',
shuffle=True,
classes=['fine'])
validation_generator = datagen.flow_from_directory(
valid_dir,
target_size=(224, 224),
batch_size=batch_size,
class_mode='categorical',
shuffle=True,
classes=['fine'])
return train_generator,validation_generator-> 폴더 구성이 traindata/fine 형식으로 되어있는데 traindata를 train_dir로 두고 classes를 3개로 나누면 fine, hello, wait 폴더에서 각각 뽑는 것은 아닐 것 같은데 한 폴더에 다 합치면 어디부터 어디까지가 한 단어인지 어떻게 알지? 싶어서 그냥 우선 단어 하나만 진행해보기로 했다.
def load_VGG16_model():
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224,224,3))
print("Model loaded")
print(base_model.summary())
return base_model-> input_shape은 입력 데이터의 각 차원별 크기를 나타내는 정수값들이 나열된 튜플이라고 한다. 정수 대신 None을 쓸 경우 아직 정해지지 않은 양의 정수를 나타내고, (행, 열, 채널 수)로 정의하고 채널 수는 흑백인 경우에는 1, 컬러(RGB)영상인 경우에는 3으로 설정한다.
def extract_features_and_store(train_generator,validation_generator,base_model):
x_generator = None
y_lable = None
batch = 0
for x,y in train_generator:
if batch == (56021/batch_size):
break
print("predict on batch:",batch)
batch+=1
if x_generator==None:
x_generator = base_model.predict_on_batch(x)
y_lable = y
print(y)
else:
x_generator = np.append(x_generator,base_model.predict_on_batch(x),axis=0)
y_lable = np.append(y_lable,y,axis=0)
x_generator,y_lable = shuffle(x_generator,y_lable)
np.save(open('video_x_VGG16.npy', 'w'),x_generator)
np.save(open('video_y_VGG16.npy','w'),y_lable)
x_generator = None
y_lable = None
batch = 0
for x,y in validation_generator:
if batch == (3974/batch_size):
break
print("predict on batch validate:",batch)
batch+=1
if x_generator==None:
x_generator = base_model.predict_on_batch(x)
y_lable = y
else:
x_generator = np.append(x_generator,base_model.predict_on_batch(x),axis=0)
y_lable = np.append(y_lable,y,axis=0)
x_generator,y_lable = shuffle(x_generator,y_lable)
np.save(open('video_x_validate_VGG16.npy', 'w'),x_generator)
np.save(open('video_y_validate_VGG16.npy','w'),y_lable)
train_data = np.load(open('video_x_VGG16.npy'))
train_labels = np.load(open('video_y_VGG16.npy'))
train_data,train_labels = shuffle(train_data,train_labels)
validation_data = np.load(open('video_x_validate_VGG16.npy'))
validation_labels = np.load(open('video_y_validate_VGG16.npy'))
validation_data,validation_labels = shuffle(validation_data,validation_labels)
train_data = train_data.reshape(train_data.shape[0], train_data.shape[1] * train_data.shape[2], train_data.shape[3])
validation_data = validation_data.reshape(validation_data.shape[0], validation_data.shape[1] * validation_data.shape[2], validation_data.shape[3])
return train_data,train_labels,validation_data,validation_labels-> 위의 코드의 일부이다. 아래 코드를 이해할 수 없어서 빼두었다.
train_data = train_data.reshape(train_data.shape[0], train_data.shape[1] * train_data.shape[2], train_data.shape[3])
validation_data = validation_data.reshape(validation_data.shape[0], validation_data.shape[1] * validation_data.shape[2], validation_data.shape[3])-> 미서님의 코드를 참고하면 numpy.reshape()은 구조를 재배열 해주는 함수라고 한다. 그럼 인자로 넣어둔 .shape은 무엇인지 궁금했다. numpy.ndarray형에 .shape을 하게 되면 배열의 크기를 알려준다고 한다.
그러면 각 data에는 어떤 값의 개수를 의미하고, 왜 곱하는 것인지 궁금해졌다.
이 외에는 추가적인 수정 없이 바로 main 코드를 실행시켜보았다.
if __name__ == '__main__':
train_generator,validation_generator = bring_data_from_directory()
base_model = load_VGG16_model()
train_data,train_labels,validation_data,validation_labels = extract_features_and_store(train_generator,validation_generator,base_model)
train_model(train_data,train_labels,validation_data,validation_labels)
test_on_whole_videos(train_data,train_labels,validation_data,validation_labels)->train_data,train_labels,validation_data,validation_labels = extract_features_and_store(train_generator,validation_generator,base_model) 이 코드를 실행하고 결과가 predict on batch: 9xxxxx을 넘어 끝도 없이 진행되었다. (predict on batch는 한 batch의 샘플에 대해 예측값을 반환하는 메소드라고 한다.)
-> 한시간을 해도 안끝났다. 이건 무한루프 아닐까?
-> 이건 도저히 아니다 싶어서 뭘까... 고민을 했다. 미서님의 벨로그 글을 보고 오류가 생기는 지점이 존재한다는 것을 깨닫고 수정하였다. 나는 에러코드도 없고 그냥 끝없이 진행되는게 에러였던 걸까 추측이 된다.
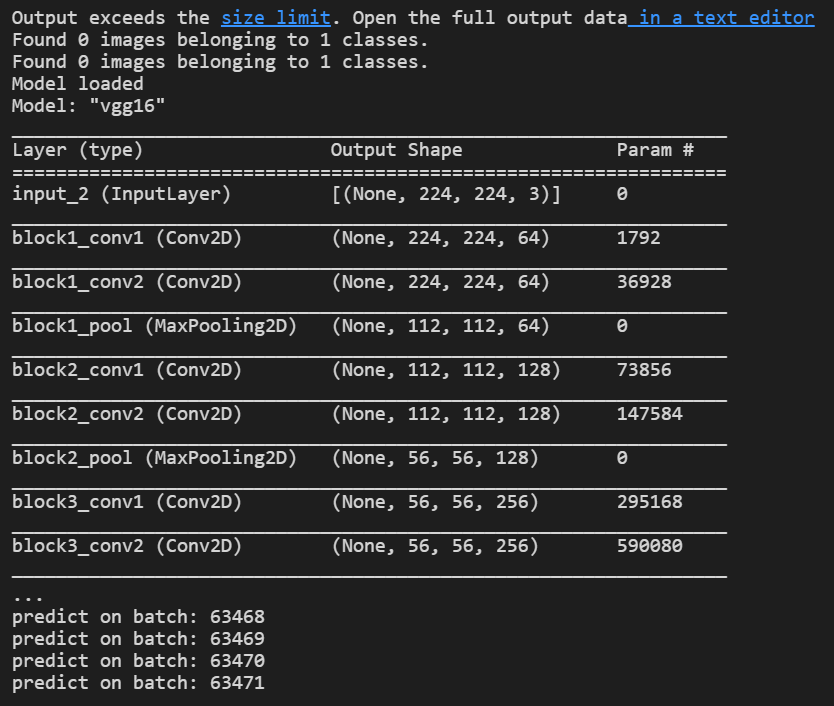 -> 실행중인 모습이다. 그런데 Found 0 images belonging to 1 classes.는 무엇일까 found 0 images... 굉장히 무섭다.
-> 실행중인 모습이다. 그런데 Found 0 images belonging to 1 classes.는 무엇일까 found 0 images... 굉장히 무섭다.
참고
컨볼루션 신경망 레이어 이야기
https://github.com/keras-team/keras-docs-ko/blob/master/sources/getting-started/sequential-model-guide.md
파이썬으로 배우는 딥러닝 교과서 (도서)
