경로 표현식
- .(점)을 찍어 객체 그래프를 탐색하는 것
- 상태 필드(state field) : 단순히 값을 저장하기 위한 필드 (m.username), 경로 탐색의 끝, 탐색이 더이상 되지 않음
- 연관 필드(association field) : 연관관계를 위한 필드
- 단일 값 연관 필드 :
- 타겟 대상이 엔티티 (m.team)
@ManyToOne@OneToOne - 묵시적 내부 조인(inner join) 발생 > 상당히 위험, 외부조인은 못함 (명시적 조인에서는 가능)
select m.team from Member m - 최대한 명시적 조인으로 짜야함 > join 키워드 직접 사용
select m from Member m join m.team t - 탐색 더 할 수 있음
- 타겟 대상이 엔티티 (m.team)
- 컬렉션 값 연관 필드 :
- 타겟 대상이 컬렉션 (m.orders)
@OneToMany@ManyToMany - 묵시적 내부 조인 발생
- 더이상 탐색이 되지 않음 > from절에서 명시적 조인하여, 별칭을 얻어 별칭을 통해서는 탐색 가능
select t.members from Team t> 더이상 탐색 X
select m.username from Team t join t.members m> 탐색 가능
- 타겟 대상이 컬렉션 (m.orders)
- 단일 값 연관 필드 :
- 제일 권장하는 방법은 묵시적 조인을 사용하지 않는 것, 명시적 조인을 사용!!!!
JPQL - 페치 조인(fetch join)
- JPQL에서 성능 최적화를 위해 제공하는 기능 (SQL 조인 종류 X)
- 연관된 엔티티나 컬렉션을 SQL 한 번에 함께 조회하는 기능
- 실무에서 많이 사용
- 어떤 객체 그래프를 한번에 조회할 것인지 직접 명시적으로 동적인 타이밍에 정할 수 있음
엔티티 페치 조인 (ManyToOne)
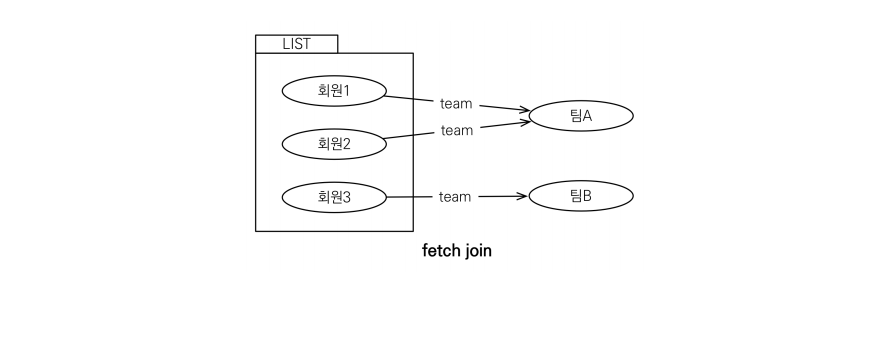
- fetch join이 아니고 지연로딩으로 세팅이 되어 있었을 때
- 회원1에서 팀A에 대한 정보에 접근할 때 SQL 쿼리로 가져옴
- 회원2에서 팀A에 대한 정보에 접근할 때 1차 캐시로 가져옴
- 회원 3에서 팀B에 대한 정보에 접근할 때 SQL 쿼리로 가져옴
- SQL 쿼리가 너무 많이 나갈 수 있음 > fetch join 사용해서 관련된 것들 한번에 조회
- fetch join으로 조회하면 프록시가 아니라 실제 데이터가 담김
join해서 다 들고오기 때문에 영속성 컨텍스트에 처음부터 데이터가 다 채워져있음 - 지연로딩으로 세팅을 했어도 페치 조인이 항상 우선
String query= "select m from Member m join fetch m.team ";
List<Member> result = em.createQuery(query, Member.class)
.getResultList();
for (Member member : result) {
System.out.println("member = " + member.getUsername() + ", " +
member.getTeam().getName());
}컬렉션 페치 조인
- 일대다 관계, 컬렉션 페치 조인
String query= "select t from Team t join fetch t.members ";
List<Team> result = em.createQuery(query, Team.class)
.getResultList();
for (Team team : result) {
System.out.println("team = "+ team.getName() +
"|members=" + team.getMembers().size());
}
- 일대다 관계는 데이터가 뻥튀기 될 수 있음 (중복 출력) > DISTINCT로 중복 해결!
- 참고 : 다대일 관계는 뻥튀기 되지 않음
JPQL의 DISTINCT
1. SQL에 DISTINCT를 추가하는 기능 제공
2. 애플리케이션 레벨에서(DB 아님) 엔티티 중복 제거하는 기능 제공
- SQL에 DISTINCT를 추가하면 데이터가 모두 같아야 중복 제거 가능 > 여기서 데이터가 달라 SQL 결과에서 중복제거 실패한것들은 애플리케이션 레벨에서 한번 더 중복 제거 시도
페치 조인과 일반 조인의 차이
- 일반 조인 실행시 연관된 엔티티를 함께 조회하지 않음
- JPQL은 결과를 반환할 때 연관관계 고려 X > 단지 SELECT 절에 지정한 엔티티만 조회
- 페치 조인을 사용할 때만 연관된 엔티티도 함께 조회 (즉시 로딩)
페치 조인의 한계
- 페치 조인 대상에는 별칭을 주지 않는것이 좋음
select t from Team t join fetch t.members (as m where m.age > 10)가급적 사용 X - 둘 이상의 컬렉션은 페치 조인 할 수 없음 > 페치 조인의 컬렉션은 하나만 지정 가능
- 컬렉션(일대다)을 페치 조인하면 페이징 API(setFirstResult, setMaxResults)를 사용할 수 없음 > 데이터 뻥튀기가 있어서
- 일대일, 다대일 같은 단일 값 연관 필드들은 페치 조인해도 페이징 가능
정리
- 페치 조인은 매우매우 중요
- 연관된 엔티티들을 SQL 한 번으로 조회 - 성능 최적화
- 엔티티에 직접 적용하는 글로벌 로딩 전략(보통 지연로딩을 사용)보다 우선함
- 페치 조인은 객체 그래프를 유지할 때 사용하면 효과적
- 여러 테이블을 조인해서 엔티티가 가진 모양이 아닌 전혀 다른 결과를 내야 하면, 페치 조인 보다는 일반 조인을 사용하고 필요한 데이터들만 조회해서 DTO로 반환하는 것이 효과적
세가지 방법
1. 페치조인을 사용해서 엔티티를 조회
2. 페치 조인을 해서 애플리케이션에서 DTO로 바꿔서 화면에 반환
3. JPQL을 짤 때 부터 DTO로 스위칭 해서 가져옴
엔티티 직접 사용
- JPQL에서 엔티티를 직접 사용하면 SQL에서 해당 엔티티의 기본 키 값을 사용
- 함수, 파라미터, 외래키 등에서 다 가능함
select count(m) from Member m //엔티티를 함수에서 직접 사용
// select count(m.id) from Member m 와 같음
String jpql = “select m from Member m where m = :member”; // 엔티티를 파라미터로 전달
// select m from Member m where m.id = :memberId 와 같음
List resultList = em.createQuery(jpql)
.setParameter("member", member)
.getResultList();
String qlString = “select m from Member m where m.team = :team”; // 외래키값으로 사용
// select m from Member m where m.team.id = :teamId 와 같음
List resultList = em.createQuery(qlString)
.setParameter("team", team)
.getResultList(); Named 쿼리
- 쿼리에 이름을 부여해서 사용 (쿼리 재활용)
- 미리 정의해서 이름을 부여해두고 사용하는 JPQL
- 정적 쿼리
- 애플리케이션 로딩 시점에 초기화 후 재사용 (정적 쿼리이기 때문에 SQL로 파싱해놓고 캐시하고 있음)
- 애플리케이션 로딩 시점에 쿼리를 검증 > 문법 오류를 미리 잡을 수 있음
@Entity
@NamedQuery(
name = "Member.findByUsername",
query="select m from Member m where m.username = :username")
public class Member {
...
}List<Member> resultList =
em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username", "회원1")
.getResultList();벌크 연산
- 쿼리 한 번으로 여러 테이블 로우 변경(엔티티)
- executeUpdate()의 결과는 영향받은 엔티티 수 반환
- UPDATE, DELETE 지원
주의
- 벌크 연산은 영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리 > 영속성 컨텍스트에 있는 것에는 반영이 되지 않아 값이 꼬일 수 있음
- 해결책
- 벌크 연산을 먼저 실행
- 벌크 연산 수행 후 영속성 컨텍스트 초기화
// flush를 자동 호출함
// (flush는 commit을 하거나, 쿼리가 나가거나 할 때 자동 호출 되고 강제로 flush를 호출해도 됨)
int resultCount = em.createQuery("update Member m set m.age=20")
.executeUpdate();
em.clear();
// 아직 변경된 것이 적용되지 않은 영속성 컨텍스트의 값을 사용하지 않기 위해 초기화
// DB에서 새로 가져오기 위해