인덱스
결국, 인덱스 == 정렬
인덱스란?
- DB의 테이블에 대한 검색 속도를 향상시켜주는 자료구조
- SELECT의 성능 향상 (대신 insert, update, delete의 성능은 희생됨)
-> 기능 자체의 행위가 느린 것이고, 기능을 위한 조회 행위는 빨라짐
인덱스 사용에 적합한 경우
-
규모가 큰 테이블
-
데이터의 range가 크고 중복도가 낮은 컬럼
카디널리티(Cardinality)가 가장 높은 것을 잡아야 한다
: 중복된 수치
성별, 학년 = 카디널리티 낮음
주민등록번호, 계좌번호 = 카디널리티 높음 -
조회가 많거나 정렬된 상태가 유용한 컬럼
-
where, order by, join 이 자주 사용되는 컬럼
인덱스의 자료구조
해시 테이블 (Hash Table)
- (key, Value) = (컬럼의 값, 데이터의 위치) 로 인덱스를 구현
- O(1)의 시간
B+Tree
-
기존의 B-Tree는 어느 한 데이터의 검색은 효율적이지만, 모든 데이터를 한 번 순회하는 데에는 트리의 모든 노드를 방문해야 하므로 비효율적이다. 이러한 B-Tree의 단점을 개선시킨 자료구조가 B+Tree이다.
-
B+Tree는 오직 leaf node에만 데이터를 저장하고 leaf node가 아닌 node에서는 자식 포인터만 저장한다.
-
그리고 leaf node끼리는 Linked list로 연결되어있다.
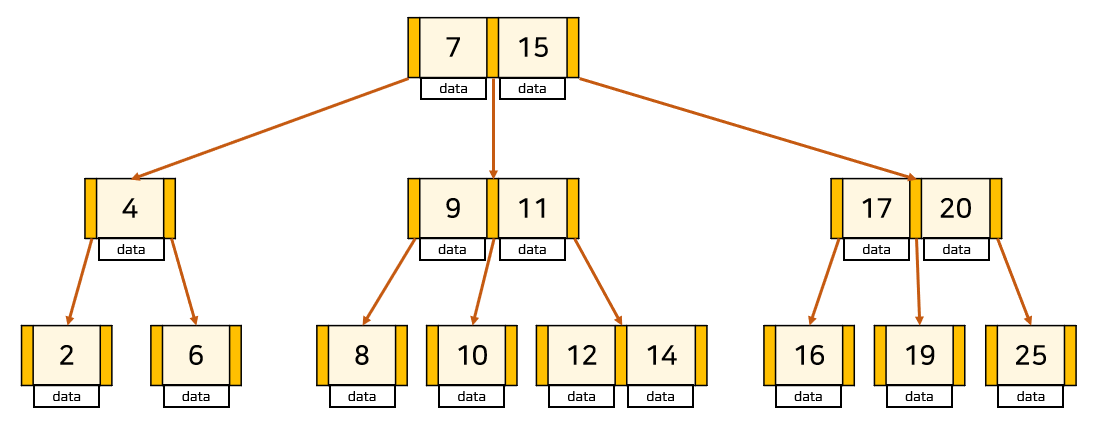
B-Tree 예시
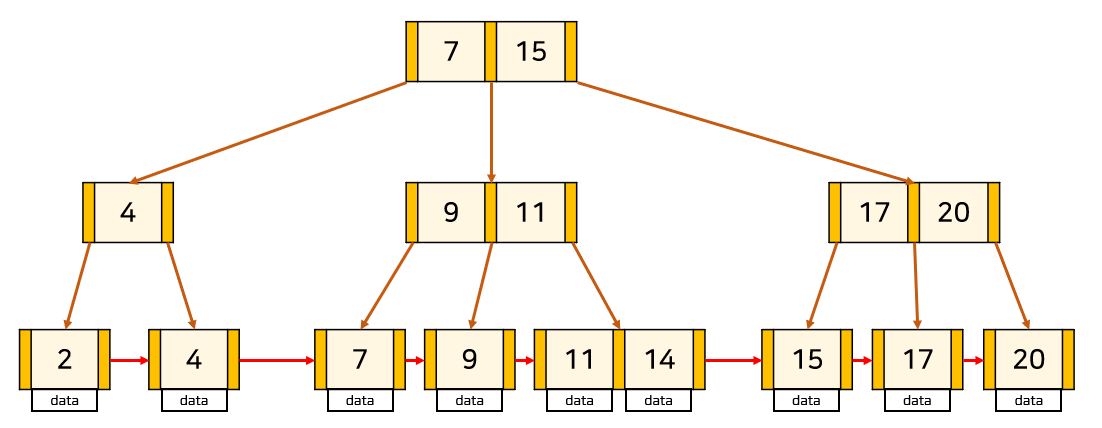
B+Tree 예시
=> B+Tree 구조
- 인덱스의 두번째 컬럼은 첫번째 컬럼에 의존해서 정렬
- 즉, 두번째 컬럼 정렬은, 첫번째 컬럼이 같은 열에서만 의미가 있음
- Root에서 Leaft까지 오고가는 횟수를 얼마나 줄이느냐에 인덱스의 성능이 달렸음

느려도 꾸준히