데이터베이스
데이터베이스(Database)란?
여러 사람이 공유하고 사용할 목적으로 한 곳에서 관리되는 데이터의 조직화된 집합으로, 데이터를 소프트웨어에서 효율적으로 관리하기 위한 저장소
-> 데이터의 집합 저장소
데이터베이스의 종류
- 관계형 DB(RDBMS)
- 가장 많이 사용하는 데이터베이스
- 데이터를 테이블 형태로 구조화하여 저장하고 관리하는 시스템
- 테이블 간의 관계를 이용해 데이터를 연결
ex) Oracle, MySQL, PostgreSQL, Microsoft SQL Server 등
- 비관계형 DB (NoSQL)
- 테이블이 아닌 key-value, document, graph 등의 다양한 형태로 데이터를 저장하고 관리
- 스키마가 고정되지 않고, 대규모 데이터 처리와 높은 확장성을 제공
ex) MongoDB, Cassandra, Redis 등
트랜잭션(Transaction)
데이터베이스에서 하나의 논리적인 작업 단위를 뜻하며 트랜잭션으로 묶여있는 작업들은 모두 성공적으로 완료되거나 하나라도 실패하면 전체가 취소됨
RDBMS(Relational Database Management System)
관계형 데이터베이스 RDB(Relational DataBase)를 관리할 수 있는 소프트웨어로 데이터를 테이블 형식으로 관리함.
RDBMS는 데이터 간의 관계를 정의하고, 이러한 관계를 바탕으로 복잡한 Query를 실행할 수 있는 기능을 제공
관계형 데이터베이스 특징
1. 테이블 (Table)
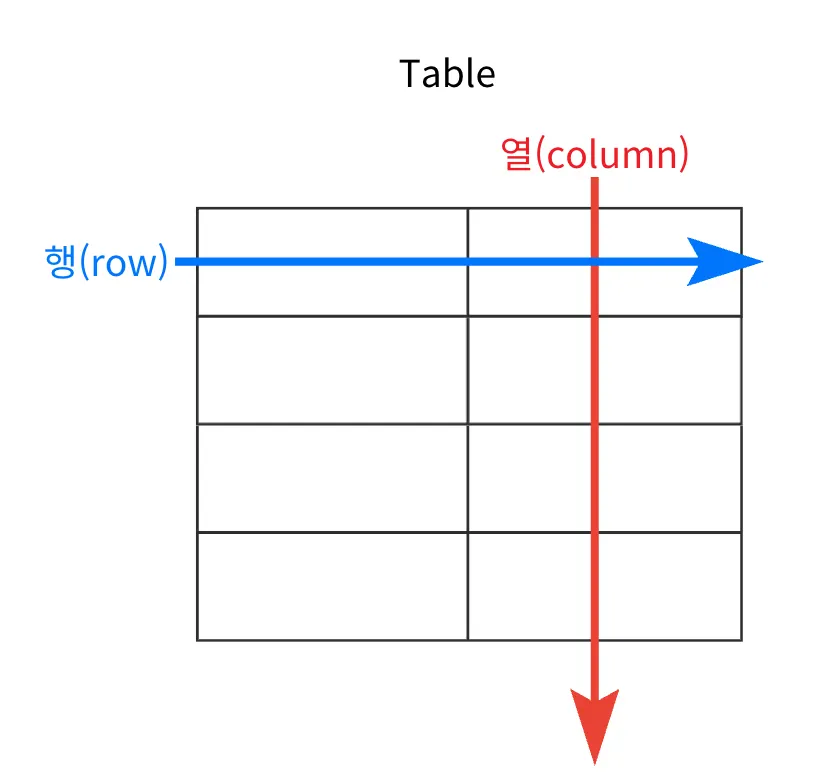
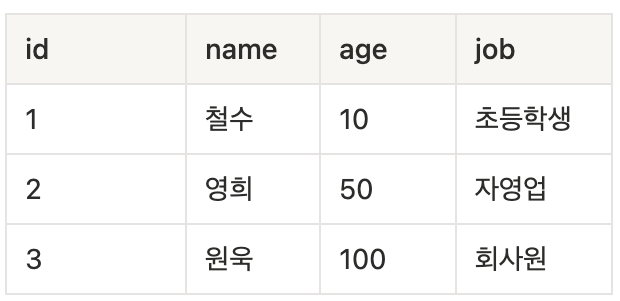
- RDBMS에서 데이터는 테이블이라는 구조에 저장되며 행(row)과 열(column)로 구성됨
- 열(column)은 데이터의 속성(유일한 이름)을 나타내고 타입(데이터 유형)을 가짐
- 행(row)은 관계된 데이터의 묶음을 의미하고 tuple 또는 record라고 함
- 데이터 무결성
- 테이블은 특정 규칙과 제약 조건(기본 키, 외래 키, 유니크 등)을 통해 데이터를 저장함으로써 데이터의 무결성(정확성, 일관성, 유효성)을 유지한다.
2. 관계(Relationships)
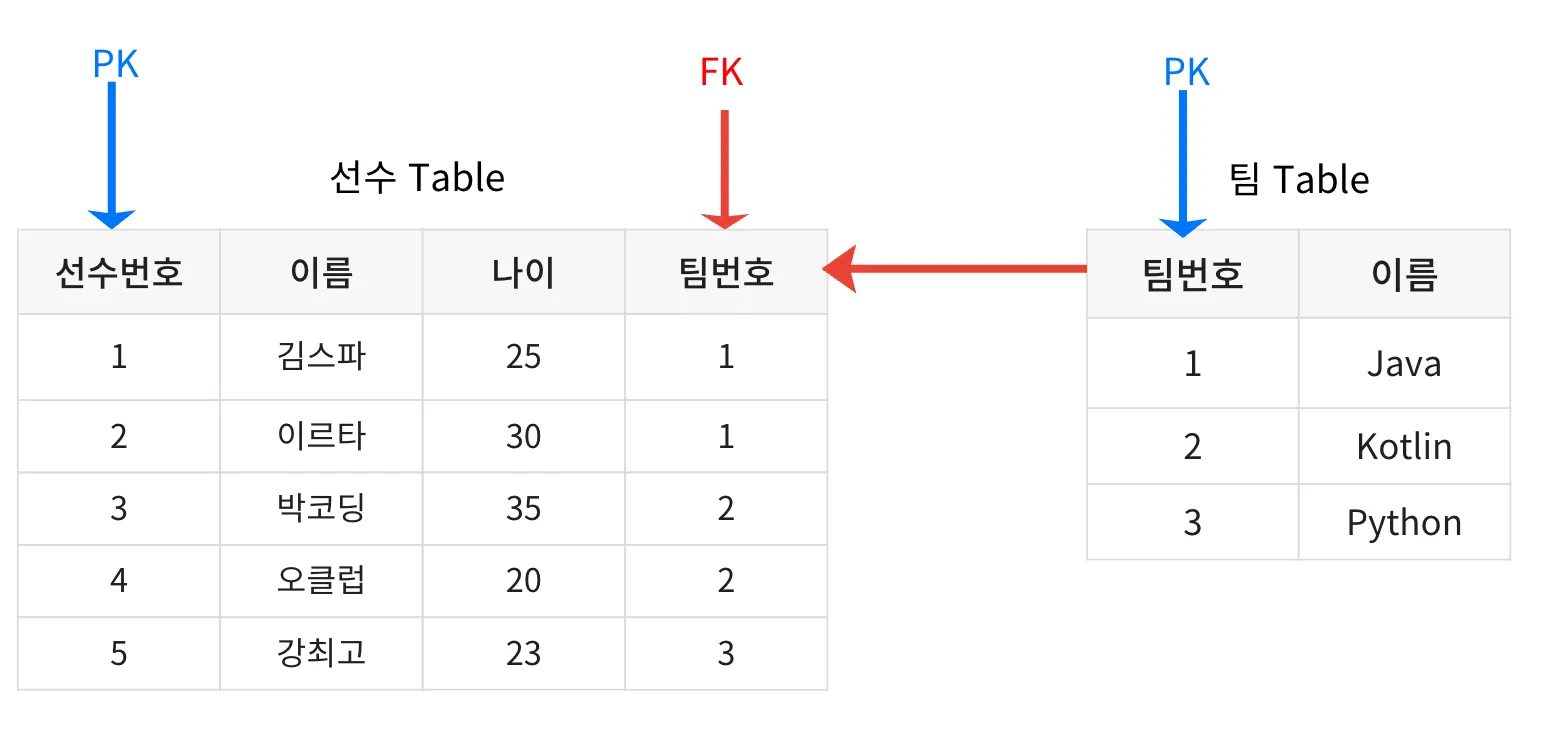
- 테이블 간의 관계는 외래 키(Foreign Key)를 통해 설정된다.
- RDBMS는 다양한 유형의 관계를 지원한다.
- 1:1 관계: 한 테이블의 한 행이 다른 테이블의 한 행과만 연결된다.
- 1:다 관계: 한 테이블의 한 행이 다른 테이블의 여러 행과 연결된다.(위 예시와 같음)
- 다:다 관계: 두 테이블의 여러 행이 서로 연결될 수 있다.
3. SQL (Structured Query Language)
- RDBMS에서 데이터를 정의하고, 관리하기 위한 표준 언어이다.
- 데이터를 생성(Create), 읽기(Read), 갱신(Update), 삭제(Delete)하는 작업을 수행한다.
4. 키(Keys)
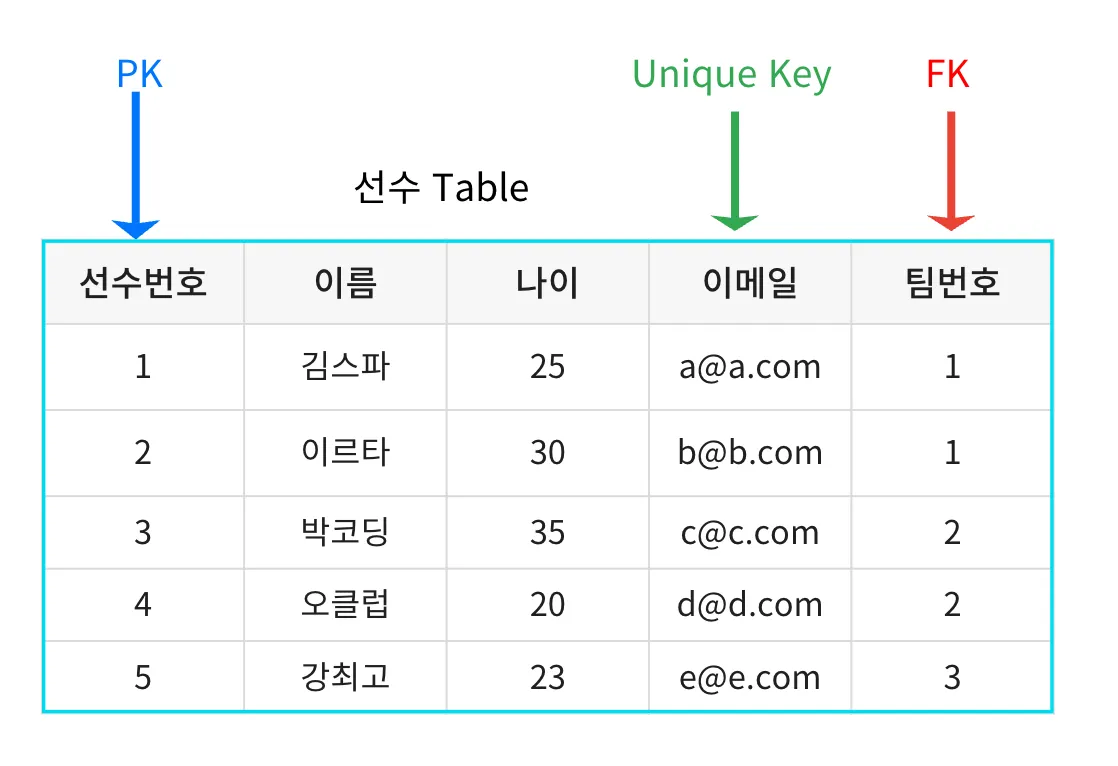
- 기본 키(Primary Key)
- 테이블 내에서 각 행을 고유하게 식별하는 열 또는 열의 조합
- 기본 키는 중복되지 않으며, NULL 값을 가질 수 없음
- 외래 키(Foreign Key)
- 한 테이블의 열이 다른 테이블의 기본 키를 참조하여 두 테이블 간의 관계를 설정하는 데 사용
- 테이블 간의 데이터 무결성을 유지할 수 있음
- 유일 키(Unique Key)
- 기본 키와 유사하지만, 하나의 테이블에서 여러 개가 존재할 수 있음
- 중복된 값을 허용하지 않지만, NULL 값은 허용할 수 있음
5. 트랜잭션(Transaction)
- RDBMS는 트랜잭션이라는 단위를 통해 데이터베이스 작업을 처리하며, 이를 통해 데이터의 일관성과 무결성을 유지함
- 트랜잭션은 원자성(Atomicity), 일관성(Consistency), 고립성(Isolation), 지속성(Durability)이라는 ACID 속성을 따름
- Atomicity: 트랜잭션의 모든 작업이 성공적으로 완료되거나, 실패 시 모든 작업이 롤백
- Consistency: 트랜잭션이 데이터베이스를 일관된 상태로 유지
- Isolation: 동시에 실행되는 트랜잭션 간의 영향을 최소화
- Durability: 트랜잭션이 완료된 후 데이터의 변경 사항은 영구적으로 저장
6. 정규화(Normalization)

- 데이터의 중복을 줄이고, 일관성과 무결성을 유지하기 위해 데이터를 구조화하는 프로세스
- 여러가지 정규화 단계가 있으며, 각 단계는 데이터 중복을 줄이고 이상 현상을 방지하는 데 목적이 있음
7. 데이터 무결성 (Data Integrity)
- 엔터티 무결성
- 각 테이블의 기본 키(PK)가 중복되지 않고 NULL 값이 아닌 상태를 유지 - 참조 무결성
- 외래 키(FK)를 통해 참조되는 데이터가 유효성을 유지하도록 보장 - 도메인 무결성
- 각 열이 정의된 데이터 타입과 제약 조건에 따라 유효한 값을 유지하도록 함
8. 인덱스 (Index)
- 특정 열의 검색 성능을 향상시키기 위해 사용
- 인덱스는 테이블의 데이터를 정렬하고, 효율적으로 접근할 수 있도록 지원
- 인덱스가 많아지면 삽입 및 수정 작업의 성능에 영향을 미칠 수 있음
대표적인 RDBMS
-
MySQL
- 오픈소스 기반의 RDBMS로 무료로 제공된다.
- 빠른 속도와 높은 성능, 다양한 기능을 제공한다.
- 광범위한 운영체제와 플랫폼에서 사용할 수 있다.
- 전 세계적으로 널리 사용되며, 방대한 문서와 커뮤니티가 있어 학습 및 문제 해결이 용이하다.
- 트래픽에 따라 확장할 수 있다. -
PostgreSQL
-
Oracle Database
-
Microsoft SQL Server
SQL(Structed Query Language)
DDL(Data Definition Language)
DDL은 데이터베이스의 구조를 정의
-
CREATE: 새로운 데이터베이스 및 테이블을 생성
-
ALTER: 기존 데이터베이스 및 테이블 구조를 수정
-
DROP: 데이터베이스 및 테이블을 삭제
DML(Data Manipulation Language)
DML은 테이블의 데이터를 조작(추가, 수정, 삭제)
-
INSERT: 테이블에 새로운 데이터를 삽입
-
UPDATE: 테이블의 기존 데이터를 수정
-
DELETE: 테이블에서 특정 데이터를 삭제
DQL(Data Query Language)
DQL은 테이블에서 원하는 데이터를 조회(검색)
-
SELECT: 데이터를 조회
