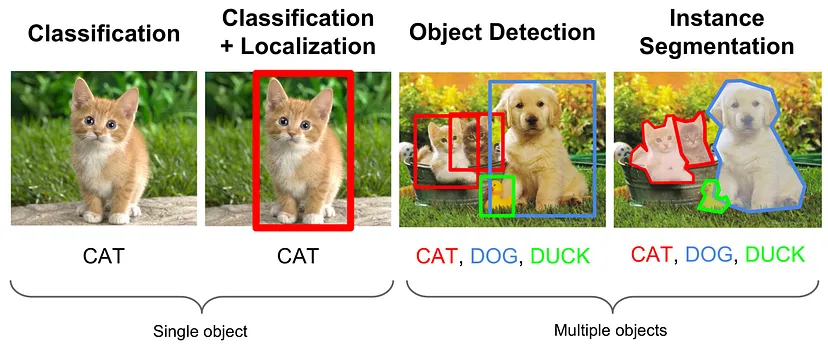
1. Object Detection (객체 탐지)
- 이미지 내의 객체를 배경과 구분해 식별하는 것(Classification)뿐만 아니라, 이미지 내 해당 객체의 위치까지 표시하는 알고리즘
- 해당 Object라고 판단되는 곳에 bounding box가 그려진다.
(Bounding Box : 한 객체 전체를 포함하는 가장 작은 직사각형)
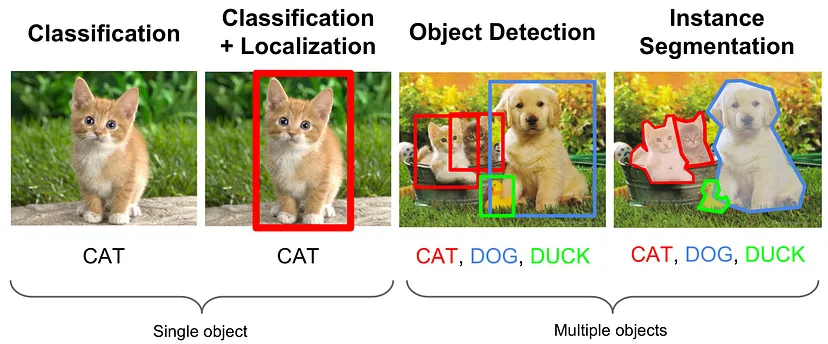
- 이미지를 input으로 받아, bounding box와 객체 클래스 리스트를 output으로 출력한다. 또한 bounding box에 대응하는 예측 클래스와 confidence(신뢰도)를 출력한다.
2. YOLO란?
YOLO는 You Only Look Once의 약자로, one step으로 모든 것을 처리하기 때문에 빠르고 정확하여 컴퓨터 비전 분야에서 객체 탐지시 표준적으로 쓰인다.
YOLO 이전
faster-RCNN 등은 파이프라인을 거치기 때문에 비교적 느린 two step 방식을 사용했다.
YOLO의 방식
- 이미지를 동일한 형태의 grid로 나눈다.
- 각 grid 중앙을 중심으로 predefined shape로 지정된 경계박스의 개수를 예측하고, 이를 기반으로 신뢰도를 계산한다.
- 높은 object 신뢰도를 가진 위치를 선택해 객체 카테고리를 파악한다.
3. 영상으로 YOLO 이해하기
1) 기본 구조
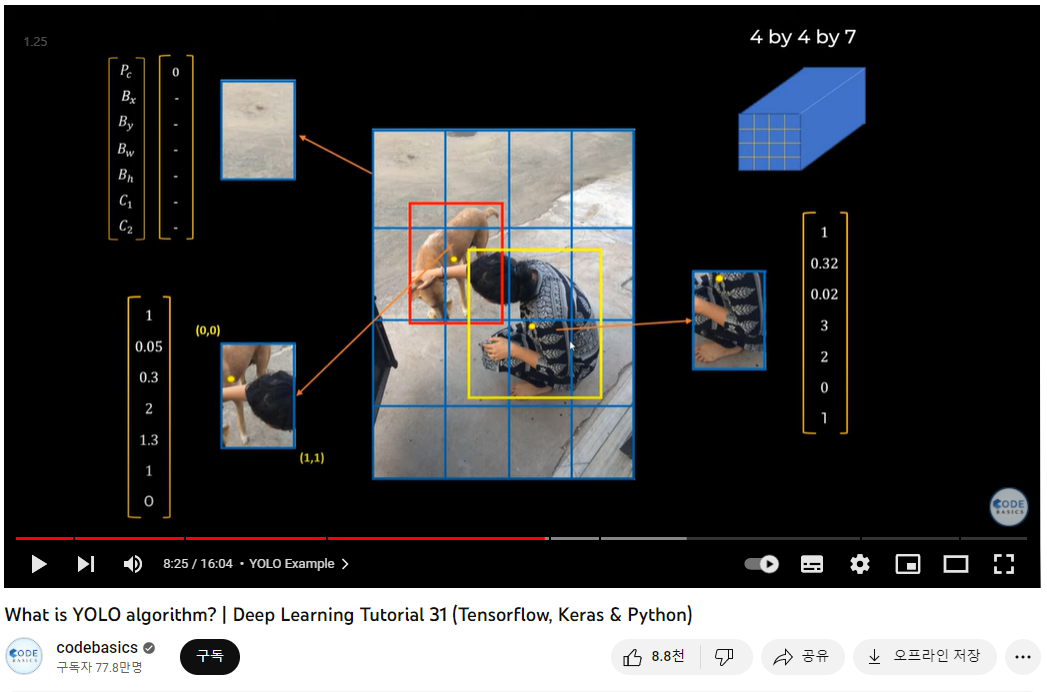 위 예시에서는 이미지를 16개의 grid로 나누었고, 각 grid는 Pc부터 C2까지 7개의 정보를 저장한다. C1==1이면 Dog Class이고, C2==1이면 Person Class이다.
위 예시에서는 이미지를 16개의 grid로 나누었고, 각 grid는 Pc부터 C2까지 7개의 정보를 저장한다. C1==1이면 Dog Class이고, C2==1이면 Person Class이다.
 위 grid에서는 객체가 아예 없으므로 Pc=0이다.
위 grid에서는 객체가 아예 없으므로 Pc=0이다.
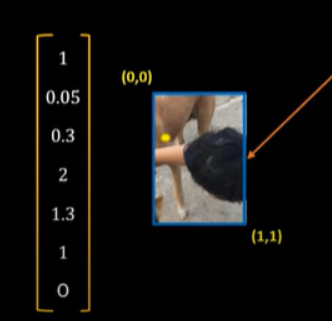 두 object가 나타나는 grid 에서는 해당 grid 내에 중심점이 있는 객체로 인식된다. 즉, 개의 중심점인 노란 점이 포함되어 C1==1, 개로 인식되었다.
두 object가 나타나는 grid 에서는 해당 grid 내에 중심점이 있는 객체로 인식된다. 즉, 개의 중심점인 노란 점이 포함되어 C1==1, 개로 인식되었다.
2) 여러 bounding box가 인식되는 경우
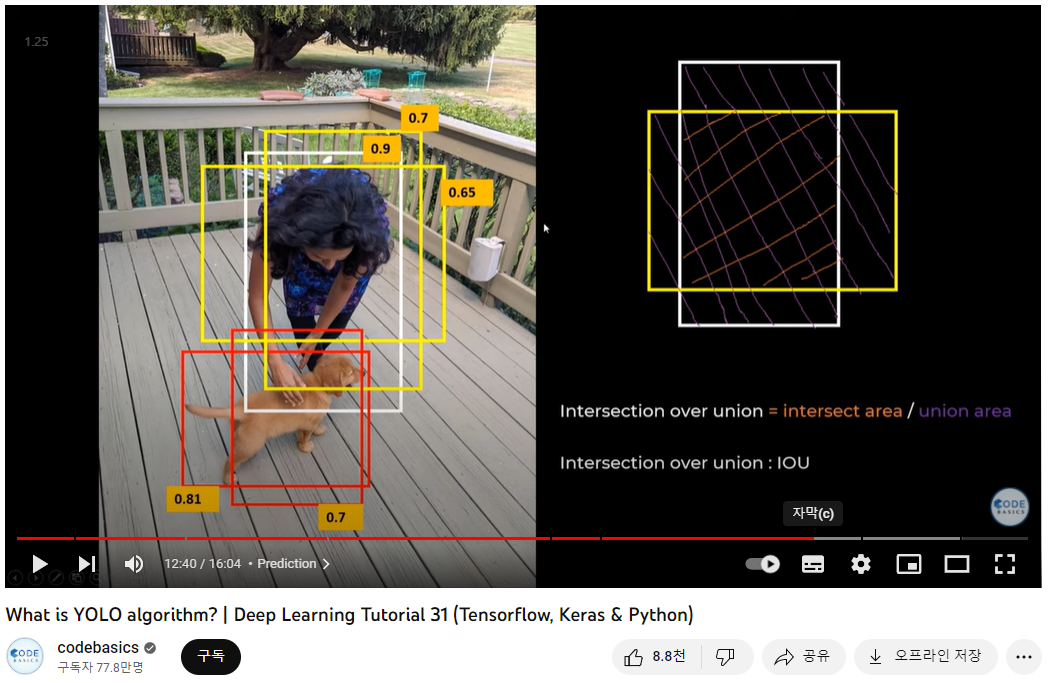
한 객체에 여러 bounding box가 중첩되어 나타날 수 있다. 단순히 더 큰 bounding box를 선택하는 것만으로는 해결할 수 없으며, 해결방법은 다음과 같다.
=> Non-max Supression(비최댓값 억제)
- 가장 확률이 높은 bounding box를 취한다.
- IOU(Intersection Over Union) 가 특정 임계치를 넘는 box는 제거한다. (예를들어, 영상에선 IOU가 0.65d이상인 boudning box를 제거)
3) 한 grid에 두 객체의 중심점이 모두 있는 경우
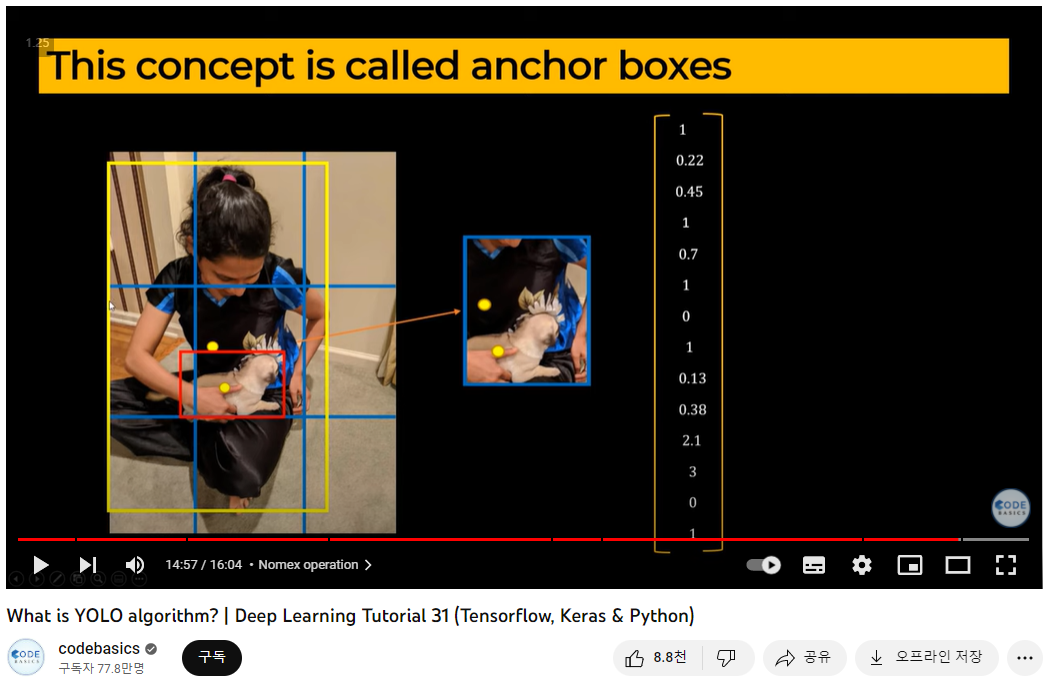
=> Anchor Box
다양한 크기의 box들 중, 내가 필요한 Data를 가장 잘 나타내는 Anchor Box의 개수와 크기를 미리 지정해 놓는다.
4. YOLO 버전 선택?
YOLO v1
2015년에 Josept Redmon이 논문과 함께 공개했다.
YOLO v2
Anchor Box가 도입되었다.
YOLO v3
YOLO를 만든 Josept Redmon이 마지막으로 개발한 버전으로, 2018년 4월에 출시되었다. Darknet-53을 기반으로 만들어졌다.
YOLO v4
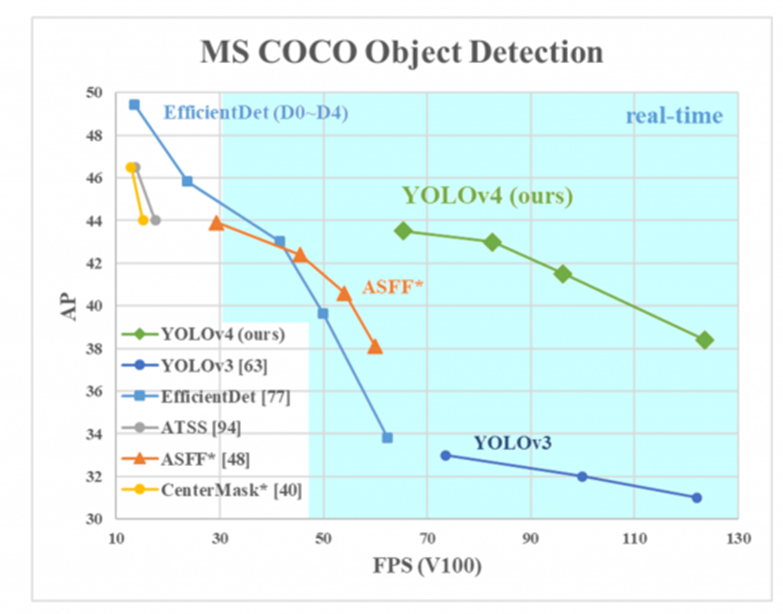
2020년 4월에 출시되었으며, CSP(Cross Stage Partial connections) 기반의 backbone 연결 등을 도입하여 성능이 향상되었다. v3와 비교하여, AP가 10%, FPS가 12% 증가하였다.
YOLO v5
2020년 6월에 논문없이 코드만으로 공개되었다. v4과 마찬가지로 CSP를 이용하지만, Darknet이 아닌 PyTorch로 구현된 점이 다르다.
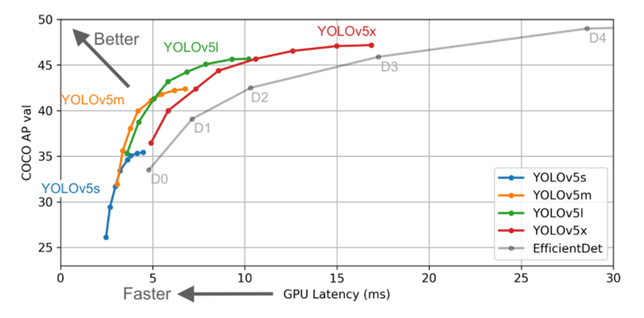
또한 s(small), m(medium), l(large), x(xlarge)로 나뉜다. s가 가장 빠르지만 정확도가 비교적 낮으며, x가 가장 느리지만 정확도가 더 높다.
더 자세한 버전 비교는 아래 블로그들에 잘 정리되어 있다.
https://velog.io/@now2466/YOLO-Series-%EB%B9%84%EA%B5%90-%EB%B6%84%EC%84%9D
https://leedakyeong.tistory.com/entry/Object-Detection-YOLO-v1v6-%EB%B9%84%EA%B5%902
참고자료
사진
https://medium.com/zylapp/review-of-deep-learning-algorithms-for-object-detection-c1f3d437b852
