커넥션 풀 등장 배경
JDBC 드라이브가 DB와 커넥션 획득하는 과정
- DB 드라이버는 DB에 TCP/IP 커넥션 연결 요청
- DB 드라이버는 ID, PW, 기타 부가 정보를 DB에 전달
- DB는 내부 인증 완료, 내부에 DB 세션 생성
- DB는 커넥션 생성 완료되었다는 응답 보냄
- DB 드라이버는 Connection 객체 생성해서 반환
❗️ 문제
이와 같이 커넥션을 새로 만드는 것은 과정이 복잡하고 시간도 많이 소모되는 일이다.
고객이 애플리케이션을 사용할 때, SQL 실행하는 시간 뿐만 아니라, 커넥션을 새로 만드는 시간도 추가됨 -> 결과적으로 응답 속도에 영향을 준다.
(참고로, DB마다 커넥션 생성하는 시간은 다른데, 시스템 상황마다 다르지만 MySQL 계열은 수 ms 정도로, 커넥션을 매우 빨리 획득할 수 있음)
✔️ 해결: 커넥션 풀 즉, 커넥션을 미리 생성해두고 사용한다.
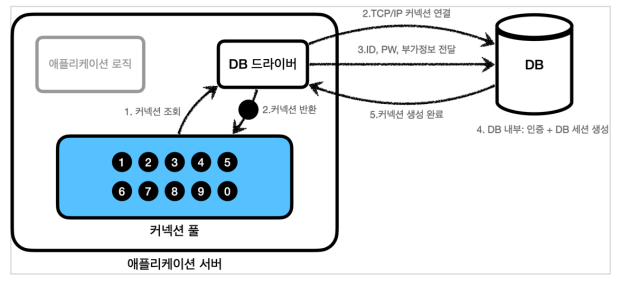
- 애플리케이션 시작 시점에 커넥션 풀은 필요한 만큼 커넥션을 미리 확보해서 풀에 보관해놓는다.
- 커넥션 개수는 서비스 특징, 서버 스펙에 따라 다르지만 보통 기본값은 10개
- 커넥션 풀에 있는 커넥션은 DB와 TCP/IP 연결되어 있는 상태 -> 언제든지 DB에 SQL 전달 가능
커넥션 풀 사용


- 이제 커넥션을 획득할 때, DB 드라이버를 통해서 커넥션을 획득하는 것이 아니라 커넥션 풀에 이미 존재하는 커넥션을 가져다 사용한다. (from. JDBC 드라이버 -> 커넥션 풀)
- 커넥션 풀에 커넥션 요청하면, 커넥션 풀은 자신이 가지고 있는 커넥션 중 하나를 반환한다.
- 커넥션을 사용하고 나면, 이제는 커넥션을 종료(= Connection 객체 소멸)하는 것이 아니라 커넥션을 커넥션 풀에 반납한다. (커넥션 풀에 있는 커넥션에 대해 conn.close()하는 경우, 해당 커넥션을 커넥션 풀에 반납)
- 정확히 말하면 다음과 같다. 커넥션 풀에서 커넥션 조회할 때, HikariProxyConnection 객체 생성한 후 이 객체에 실제 커넥션을 wrapping해서 반환한다. 그리고 conn.close()할 때, HikariProxyConnection 객체는 소멸되고 커넥션은 커넥션 풀에 들어오는 것이다.
객체 생성하는데 비용이 많이 들지 않냐고 할 수 있지만, 객체 생성은 비용이 거의 들지 않고, 게다가 오히려 객체 생성보다 커넥션 생성하는 비용이 훨씬 많이 든다.
- 적절한 커넥션 풀 숫자는 서비스 특징, 애플리케이션 서버 스펙, DB 서버 스펙에 따라 다르기 때문에, 성능 테스트를 통해서 정해야 한다. 기본값은 10개
- 커넥션 풀은 서버 당 최대 커넥션 수 제한 -> DB에 무한정 커넥션이 생성되는 것을 막아줘 DB를 보호
- 실무에서 커넥션 풀은 기본! 커넥션 획득은 JDBC 드라이버가 아닌 커넥션 풀로부터!
- 커넥션 풀 오픈소스 hikariCP
스프링부트 2.0부터는 기본 커넥션 풀로 hikariCP를 제공
DataSource
❗️ 문제
DriverManager 통해 커넥션 획득 -> 커넥션 풀에서 커넥션 획득으로 커넥션 획득 방법을 변경하려면, 커넥션을 획득하는 애플리케이션 코드도 함께 변경해야 한다.
✔️ 해결
DataSource 도입 - 커넥션 획득하는 방법을 추상화
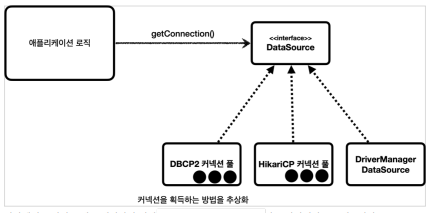
- 자바는 이러한 문제를 해결하기 위해 javax.sql.DataSource 인터페이스 제공
- DataSource는 커넥션 획득하는 방법을 추상화한 인터페이스
- 핵심 기능은 커넥션 조회
public interface DataSource {
Connection getConnection() throws SQLException;
}- 대부분의 커넥션 풀은 이미 DataSource 인터페이스를 구현해두었다. 따라서 개발자는 DataSource 인터페이스에만 의존하도록 애플리케이션 코드를 작성하면 된다.
- DriverManager는 DataSource 인터페이스 구현 x. 따라서 커넥션 획득하는 방법을 DrvierManger -> 커넥션 풀로 변경하면 관련 코드를 변경해야 하는데, 이러한 문제를 해결하기 위해 스프링은 DriverManagerDataSource(DataSource 구현 클래스) 를 제공한다. 내부적으로 DriverManager를 사용해서 커넥션을 요청할 때마다 새로운 Connection 객체를 반환한다.
설정과 사용의 분리
- DriverManager 통해서 커넥션 획득
Connection conn1 = DriverManager.getConnection(URL, USERNAME, PASSWORD);
Connection conn2 = DriverManager.getConnection(URL, USERNAME, PASSWORD);- 커넥션 획득할 때마다 URL, USERNAME, PASSWORD 파라미터 전달
- 한 줄의 코드에서 (1) DB와 커넥션 맺기 위한 설정 정보 전달, (2) 커넥션 요청을 둘 다 수행하고 있다.
- 설정 정보가 애플리케이션 전반에 퍼져있다.
(모든 repository에서 커넥션 획득할 때마다 위 코드를 사용할 것이므로)
- DataSource 통해서 커넥션 획득
DataSource dataSource = new DriverManagerDataSource(URL, USERNAME, PASSWORD);
Connection conn1 = dataSource.getConnection();
Connection conn2 = dataSource.getConnection();- DataSource 객체를 생성할 때만 파라미터 전달, 커넥션을 획득할때는 파라미터를 전달하지 않는다. 단순히 dataSource.getConnection()만 호출
- 설정 정보 전달하는 부분, 커넥션 요청하는 부분이 분리되었다. 이제 커넥션 요청할 때는 설정 정보에 신경쓰지 않아도 된다.
- 설정과 관련된 속성들이 1곳에 있으면, 향후 변경에 더 유연하게 대처할 수 있다.
HikariDataSource 사용하기
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl(URL);
dataSource.setUsername(USERNAME);
dataSource.setPassword(PASSWORD);
dataSource.setMaximumPoolSize(10); //기본값
dataSource.setPoolName("MyPool");
Connection conn1 = dataSource.getConnection();
Connection conn2 = dataSource.getConnection();- 스프링에서 JDBC를 사용하면 자동으로 라이브러리가 추가된다.
- setJdbcUrl() ~ setPoolName()는 DataSource가 아닌 HikariDataSource에 존재함
- 커넥션 풀 최대 사이즈는 10, 커넥션 풀 이름은 MyPool
- 커넥션 풀에서 커넥션 생성하는 작업, 애플리케이션 실행은 각각 별도의 쓰레드에서 동작하는데(MyPool connection adder thread, main thread), 커넥션 생성하는 작업이 애플리케이션 실행 시간에 영향을 주지 않기 위해서다.
