Introduction
이 글은 20-2학기 머신러닝 수업에서 진행한 term project에 관해 정리한 글이다. 나는 Parkinsons telemonitoring에 관한 dataset을 선택하여 프로젝트를 진행하였다. 옥스포드 대학교의 Atanasios Tsanas와 Max Little, 그리고 10개의 미국 메디컬센터, 인텔 기업이 함께 이 dataset을 만들었다. 원래 이 연구는 다양한 선형 및 비선형 회귀 방법을 사용하여 통합 파킨슨병 등급 척도(UPDRS)로 임상의사의 파킨슨병 증상 점수를 예측했으며, 나는 여기서 딥러닝 DNN 모델을 통해 UPDRS 점수를 예측하는 프로젝트를 진행하였다.
Information of data
이 dataset은 초기 파킨슨병을 앓고 있는 42명의 생체 의학 음성 측정 범위로 구성되어 있다. 다음은 dataset에 포함된 모든 변수의 이름과 해당 사용에 대한 설명이다. 'parkinsons_updrs.data'에는 22개의 특성과 5875개의 인스턴스가 있다. 그 중 motor_UPDRS 및 total_UPDRS는 target variables이다. motor_UPDRS는 환자들의 motor UPDRS 점수이고, total_UPDRS는 환자들의 total UPDRS 점수이다.
subject# 는 각 주체를 고유하게 식별하는 정수이다. 한 마디로 각 개인마다 고유 번호가 있다.
나이는 각 주체의 연령이며, 성별은 각 주체의 성별입니다. ('0'은 남성, '1'은 여성)
test_time은(는) 평가판에 채용된 이후 시간이고 정수 부분은 채용 후 일수입니다. Jitter(%), Jitter(Abs), Jitter:RAP, Jitter:PPQ5, Jitter:DDP는 기본 주파수의 변동에 대한 몇 가지 측정값이다.
Shimmer, Shimmer(dB), Shimmer:APQ3, Shimmer:APQ5, Shimmer:APQ11, Shimmer:DDA는 진폭의 변동에 대한 몇 가지 측정치이다.
NHR, HNR은 음성의 톤 성분에 대한 소음 비율 측정치이다.
PRDE는 비선형 동적 복잡도 측정이다.
DFA는 신호 프랙탈 스케일링의 지수이다.
PPE는 기본 주파수 변동에 대한 비선형 측정이다.
전체 데이터를 훈련 데이터(70%)와 테스트 데이터(30%)로 분할하였고, 데이터의 스케일이 크게 다를 경우 문제가 발생하지 않도록 데이터를 정규화하였다.
파이토치의 Dataset과 Dataloader를 통해 대량의 학습을 batch 단위로 처리하여 손실을 줄일 수 있다. 따라서 dataset을 훈련(train) dataset과 테스트(test) dataset으로 나누는 두 가지 클래스를 만들었다: ParkinsonsTrainDataset, ParkinsonsTestDataset. 만들어진 Dataloader는 크게 세 부분으로 나뉜다.
-
init(self) 는 데이터를 읽거나 다운로드 하는 부분이다.
-
getitem(self, index) 는 인덱스에 해당하는 항목을 넘기는 부분이다.
-
len(self) 는 데이터의 크기를 전달하는 부분이다.
class ParkinsonsTrainDataset(Dataset):
def __init__(self):
xy = np.loadtxt('./parkinsons_updrs.data',
delimiter=',', skiprows=1, dtype=np.float32)
train_len = int(xy.shape[0] * 0.7)
train_xy = xy[:train_len]
self.len = train_xy.shape[0]
y_label_indx = [5, 6]
self.train_x = np.delete(train_xy, y_label_indx, axis=1)
self.train_x = torch.from_numpy(self.train_x)
self.train_y = torch.from_numpy(train_xy[:, y_label_indx[0]: y_label_indx
[1] + 1])
self.train_x, mu, sigma = normalize(self.train_x)
self.train_y, mu, sigma = normalize(self.train_y)
def __getitem__(self, index):
return self.train_x[index], self.train_y[index]
def __len__(self):
return self.len훈련할 dataloader와 테스트할 dataloader를 만들 때 각 dataset으로 만든 클래스를 넘겨준다.
train_dataset = ParkinsonsTrainDataset()
test_dataset = ParkinsonsTestDataset()
train_loader = DataLoader(dataset=train_dataset,
batch_size=32,
shuffle=True,
num_workers=0, drop_last=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=32,
num_workers=0)Approach
나는 회귀와 함께 여러 FC(Full Connected) 계층으로 구성된 심층 신경망(DNN) 모델에서 학습한 후 UPDRS 점수를 예측했다.
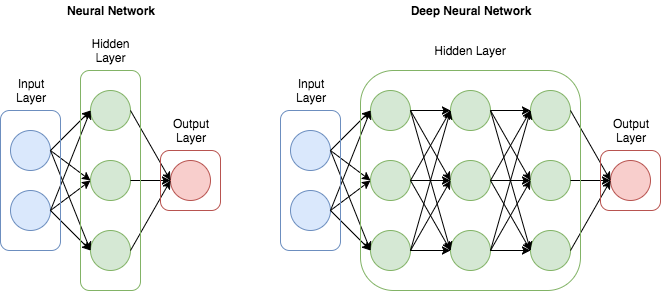
심층 신경망(DNN)은 입력 계층과 출력 계층 사이의 여러 숨겨진 계층으로 구성된 인공 신경망으로, 학습 결과를 개선하기 위해 숨겨진 계층을 크게 증가시킨다. DNN은 dropout, Rectified Linear Unit(ReLU)과 같은 방법이 적용됨에 따라 딥 러닝의 핵심 모델로 사용되고 있다. DNN은 더 적은 수의 장치만이 복잡한 데이터를 모델링할 수 있도록 한다.
나는 hidden nodes를 300, input nodes는 20, output nodes는 2로 정하였다. 또한 평균 제곱 오차(MSE)와 optimizer를 사용하기 위해 손실 함수를 정하였다. model.parameters()를 호출하여 SGD를 사용하면 모델의 계층이 학습할 파라미터를 넘겨준다. 여기서 러닝레이트는 0.0001 정하였다.
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.l1 = nn.Linear(20, 300)
self.relu = nn.ReLU()
self.l2 = nn.Linear(300, 2)
def forward(self, x):
out1 = self.l1(x)
out2 = self.relu(out1)
out = self.l2(out2)
return out
model = Model()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.0001)Training
이제 예측하기 전에 모델을 훈련시키는 과정이 필요하다. 그런데 total_UPDRS 손실과 motor_UPDRS 손실 사이에 큰 스케일 차이가 있었다. 따라서 motor_UPDRS 손실에 가중치(3)를 곱해주었다.
for epoch in range(30):
for i, data in enumerate(train_loader):
inputs, labels = data
y_pred = model(inputs)
motor_updrs_mse = criterion(y_pred[:, 0], labels[:, 0])
total_updrs_mse= criterion(y_pred[:, 1], labels[:, 1])
total_loss = 3 * motor_updrs_mse + total_updrs_mse
print(f'Epoch {epoch + 1} | Step: {i+1} | Loss: {total_loss.item():.4f}')
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
Prediction
After training, the result of average of all UPDRS mse, Motor_UPDRS mse and Total_UPDRS mse is below.
훈련 후 모든 UPDRS mse, motor_UPDRS의 mse, total_UPDRS의 mse는 아래와 같다.

모델링할 때마다 모든 UPDRS mse 값이 계속 많이 바뀌어서 초기 값을 고정해주었다.
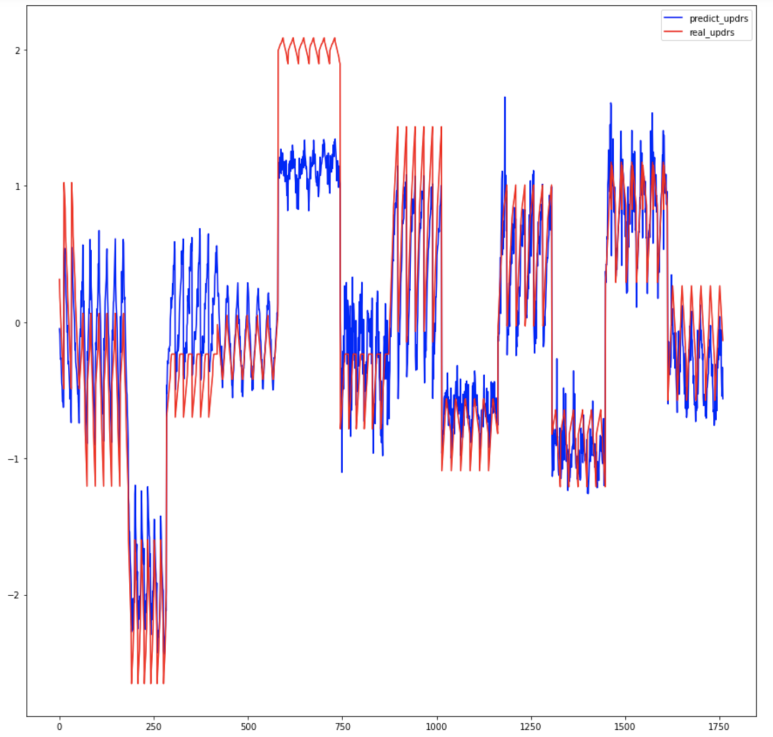
torch.manual_seed(1234)첫번째 그래프는 motor_UPDRS를 예측한 결과를 나타내는 그래프이고, 두번째 그래프는 toal_UPDRS를 예측한 결과를 나타내는 그래프이다. 그래프를 보면 total_UPDRS는 매우 잘 예측이 되지만, motor_UPDRS는 살짝 불완전하게 예측이 잘 안되는 부분이 있는 것을 확인할 수 있다. 나중에 결론 부분에서 다시 언급을 할 예정이지만, 나는 이러한 motor_UPDRS의 예측 성능을 높이기 위해 여러가지 노력을 하였다.
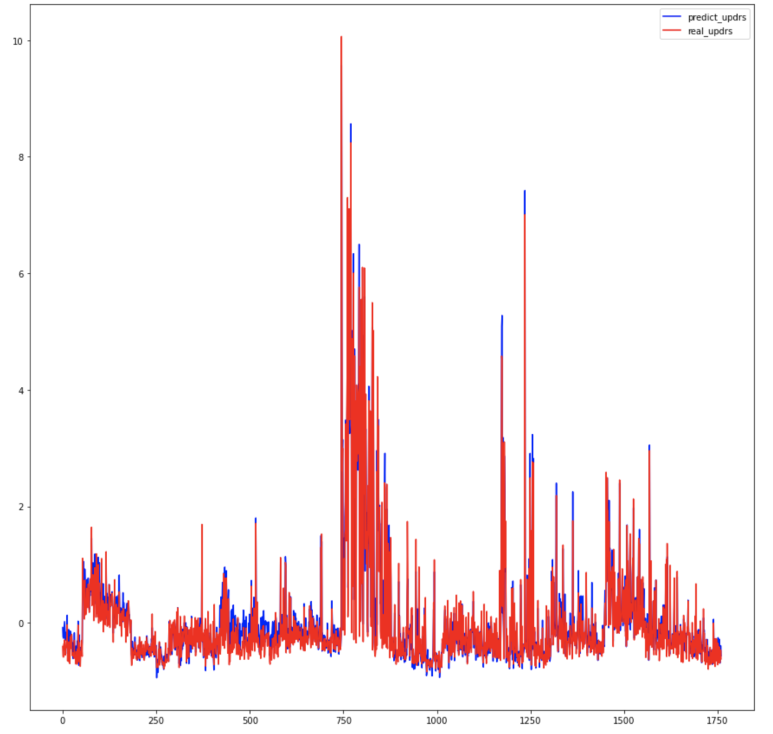
Conclusion
솔직히 이 프로젝트를 하는 과정이 쉽지는 않았다. 딥러닝을 처음 접해보면서 혼자서 이렇게 프로젝트를 진행하는 것도 처음이었기 때문에, 이러한 결과들을 도출해내기까지 나에게는 많은 시간과 노력이 필요했다. 처음에는 데이터 정규화 과정을 거치지 않고 모델링 한 후 예측을 시도했더니 스케일이 너무 크고 차이가 심해서 제대로 예측이 안되었다. 특히 total_UPDRS의 손실이 motor_UPDRS의 손실보다 심하게 작았기 때문에 total_UPDRS를 잘 예측하기가 힘들었다. 이 과정을 통해 데이터 정규화의 중요성을 깨달았다.
(아래 그래프는 정규화하지 않은 채 예측한 total_UPDRS이다)
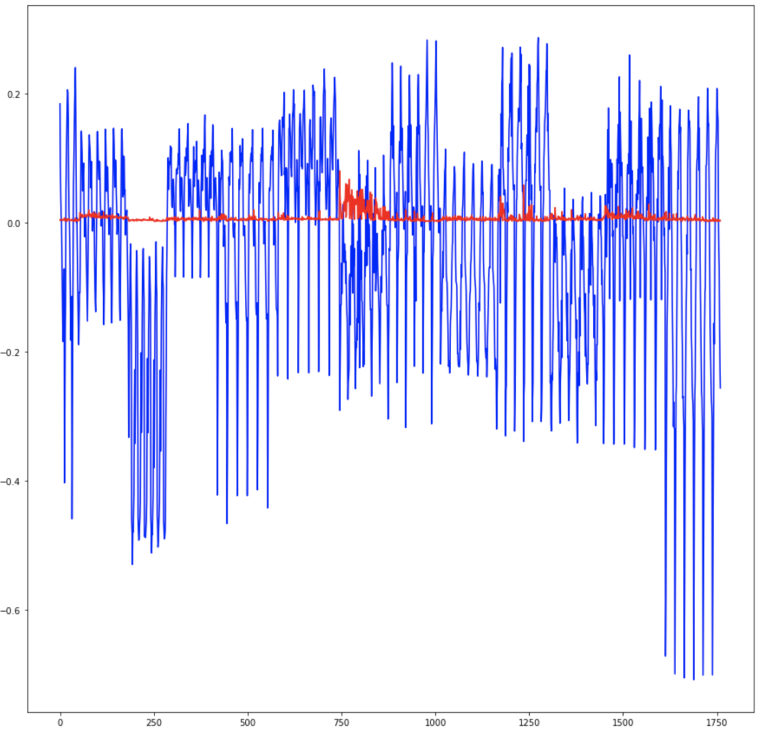
데이터를 정규화한 후 어느 정도 예측이 가능한 것처럼 보였지만, motor_UPDRS와 total_UPDRS 둘 다 잘 예측하기 위한 적절한 기준점을 찾기가 어려웠다. 정규화를 통해 값이 어느 정도 매끄러워졌지만, motor_UPDRS의 스케일에서 예측이 필요했기 때문에(?) motor_UPDRS의 손실에 가중치를 곱할 수 밖에 없었고, 그제서야 예측이 잘 되었다.
Entire Code
Reference
Telemonitoring of Parkinson's disease progression by non-invasive speech tests. (n.d.). Retrieved December 26, 2020, from https://www.neuraldesigner.com/learning/examples/parkinsons-disease-telemonitoring
