
1. 매핑 종류
- 객체와 테이블 매핑 : @Entity, @Table
- 필드와 컬럼 매핑 : @Column
- 기폰 키 매핑 : @Id
- 연관관계 매핑 : @ManyToOne, @JoinColumn
2. 데이터베이스 스키마 자동생성
DDL 생성 기능은 DDL을 자동 생성할 때만 사용되고 JPA의 실행로직에는 영향을 주지 않는다.
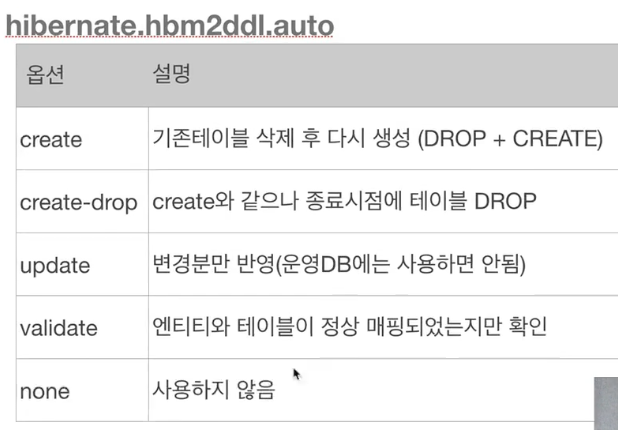
주의점
- 운영장비에는 절대 create, create-drop, update 사용금지
- 개발 초기에는 create 또는 update
- 테스트 서버에는 update 또는 validate
- 스테이징과 운영 서버는 validate 또는 none
3. 객체와 테이블 매핑
@Entity
- JPA가 관리
- 주의
- 기본 생성자 필수
- final, enum, interface, inner 클래스 사용X
- 저장할 필드에 final 사용
4. 매핑 어노테이션
@Column : 컬럼 매핑
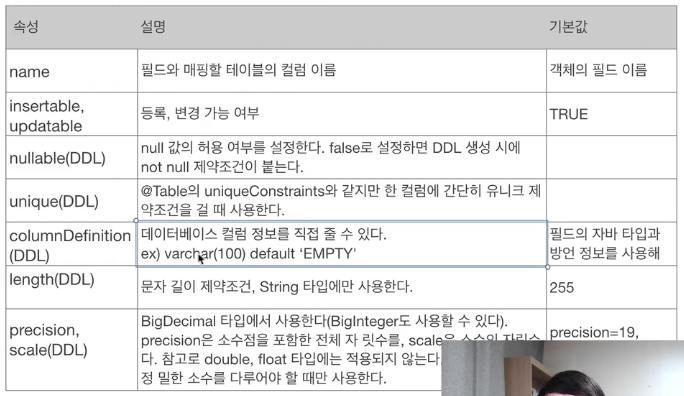
@Temporal : 날짜 타입 매핑
@Enumerated : enum 타입 매핑
- EnumType.ORDINAL: enum 순서를 데이터베이스에 저장 (기본값)
- EnumType.String: enum 이름을 데이터베이스에 저장
@Lob : BLOB, CLOB 매핑
- @Lob에는 지정할 수 있는 속성이 없다
- 문자면 CLOB 매핑, 나머지는 BLOB 매핑
- CLOB : String, char[], java.sql.CLOB
- BLOB : byte[], java.sql.BLOB
@Transient : 특정 필드를 컬럼과 매핑하지 않음
5. 기본키 매핑
- db에서 권장하는 것 쓰기
@Id : 직접 할당
@GeneratedValue : 자동 할당
- AUTO : 기본값
- 방언에 따라 (TABLE, IDENTITY, SEQUENCE) 세 개 중 하나가 자동으로 지정됨
- 그렇기 때문에 쿼리가 나가기도, 안나가기도 하는듯 (확실히 알아봐야 됨)
- IDENTITY : db야 알아서해줘 (mysql auto_increment)
- db한테 권한을 위임하기 때문에 바로 commit 날라가서 이 시점에 바로 db에 저장
- db저장 후에야 id값을 알 수 있음
- 실제 성능에는 큰 차이 없음
- SEQUENCE : 하이버네이트가 만드는 기본 sequence
- 지연로딩(버퍼링) 가능
- allocationSize로 미리 db에서 몇개 땡겨놓고 사용 (default=1) -> 이거 기가맥힘, 동시성 문제도 없이 잘됨
- TABLE : 키생성 전용 테이블을 만들어서 db 시퀀스를 흉내냄
- 장점: 모든 데이터베이스에 적용 가능
- 단점: 성능
권장하는 식별자 전략
- 기본키 제약조건 : null 아님, 변하면 안됨
- business와 관련있는 keyname을 사용하기 힘듦
- 대체키(id)로 auto increment를 쓰는걸 권장
- 권장 : Long형 + 대체키 + 키 생성전략 사용

why error?