자료구조
( Data Structure )
컴퓨터 프로그램에서 데이터를 처리하기 위해 만든 구조
데이터 값의 모임, 또 데이터 간의 관계, 그리고 데이터에 적용할 수 있는 함수나 명령의 집합
자료구조를 잘 선택하면 사용하는 메모리를 최소화 할 수 있으며 효율성을 확보할 수 있음
형태에 따른 종류
■ 선형
선형(한 줄)으로 이루어진 자료구조
- Array
- 동일한 데이터 타입을 순서에 따라 관리하는 자료구조
- 정해진 크기가 있음 (정적배열)
- 인덱싱 되어 있어 인덱스 번호로 데이터에 접근할 수 있음
- LinkedList
- 동일한 데이터 타입을 순서에 따라 관리하는 자료구조
- 정해진 크기가 없음 (동적배열)
- Stack : FILO (First In Last Out)
- 맨 마지막 위치에서만 자료를 추가, 삭제, 꺼내올 수 있음
- Queue : FIFO (First In First Out)
- 순차적으로 입력된 자료를 순서대로 처리하는데 많이 사용되는 자료구조
- 맨 앞에서 자료를 꺼내거나 삭제하고, 맨 뒤에서 자료를 추가함
■ 트리 (Tree)
부모 노드와 자식 노드간의 연결로 이루어진 자료구조 (계층적 구조)
TreeSet, TreeMap
- 이진 트리
- 자식 노드가 최대 2개인 트리
- 완전 이진 트리
- 마지막 레벨을 제외하고 모든 레벨이 완전히 채워져 있는 이진 트리
▲ 힙 (Heap)
- 완전 이진 트리의 일종
- 여러 값 중 최대값과 최소값을 빠르게 찾아내도록 만들어진 자료구조
- 최대 힙 (max heap) : 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진 트리
- 최소 힙 (min heap) : 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진 트리
- 전 이진 트리
- 모든 노드가 0개 또는 2개의 자식 노드를 갖는 이진 트리
- 포화 이진 트리
- 모든 레벨이 노드로 꽉 차 있는 이진 트리
- 이진 탐색 트리
- 기존 이진 트리보다 탐색이 빠름
■ 그래프 (Graph)
여러 특성을 가지는 객체와 이 객체들의 연결 관계를 가지고 있는 자료구조
연결할 객체를 나타내는 정점(Vertext)과 객체를 연결하는 간선(Edge)의 집합
- 무방향 그래프
- 두 정점을 연결하는 간선에 방향이 없는 그래프
- 방향 그래프
- 간선에 방향이 있는 그래프
- 완전 그래프
- 한 정점에서 다른 모든 정점과 연결되서 최대 간선 수를 갖는 그래프
- 부분 그래프
- 기존의 그래프에서 일부 정점이나 간선을 제외하여 만든 그래프
- 가중 그래프
- 정점을 연결하는 간선에 가중치를 할당한 그래프
- 유향 비순환 그래프
- 방향 그래프에서 사이클이 없는 그래프
- 연결 그래프
- 떨어져 있는 정점이 없는 그래프
- 단절 그래프
- 연결되지 않은 정점이 있는 그래프
■ 해시 (Hash)
ArrayList가 데이터 추가/삭제 시 많은 시간이 소요되는 점이나, LinkedList가 조회 시 효율이 떨어지는 점을 극복하기 위해서 제시된 방법
Key-Value(Hash Table) 형태의 자료구조로서 검색과 저장을 위한 자료구조
특정 데이터가 저장되는 인덱스를 그 데이터만의 고유한 위치로 정하여서 데이터 추가/삭제 시 데이터의 이동이 없도록 만들어진 구조
JCF
(Java Collection Framework)
Java에서 데이터를 저장하는 자료구조들을 한 곳에 모아 편리하게 관리하고 사용하기 위해 제공하는 것
크게 List, Set, Map 으로 구분할 수 있음
이 모든건 import가 되어있어야 사용할 수 있음
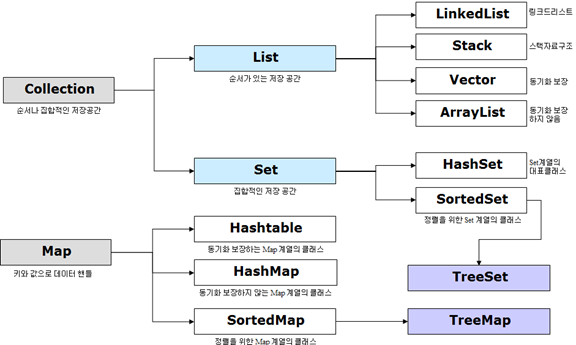
Collection
데이터의 그룹 집합체
- 기능 : 크기 자동조정 / 추가 / 수정 / 삭제 / 반복 / 순회 / 필터 / 포함확인 등
기본형 데이터가 아닌 참조형 데이터만 저장이 가능함
(기본형 데이터는 Wrapper class를 이용하여 Boxing 시켜주거나 autoBoxing으로 저장할 수 있음)
List와 Set, Queue 인터페이스의 많은 공통된 부분을 Collection 인터페이스에서 정의하고, 그것을 상속받음
(Collection 인터페이스를 상속받는 클래스들을 Collections라고 함)
Map은 Key-Value 라는 다른 구조를 가지기 때문에 독립적인 인터페이스가 구현되어있음
■ List
index 라는 식별자로 순서를 가짐
데이터 중복 허용
- ArrayList
- 각 데이터에 대한 인덱스를 가지고 있어서 조회 기능에 성능이 뛰어남
- Array와 달리 초기크기를 지정하지 않아도 되므로, 추가 삭제가 자유로움 (동적배열)
- 하지만 데이터의 추가, 삭제 시 많은 데이터가 밀리거나 당겨지기 때문에 많은 시간이 소요됨
ArrayList<Integer> intList = new ArrayList<Integer>(); // 선언 + 생성
// 추가
intList.add(1);
intList.add(2);
intList.add(3);
// 조회
System.out.println(intList.get(1)); // 2 (1번째 인덱스)
System.out.println(intList.toString()); // [1, 2, 3] (전체 배열 조회)
// 수정
intList.set(1, 10); // 1번째 인덱스 수정
System.out.println(intList.get(1)); // 10
// 삭제
intList.remove(0); // 0번째 인덱스 삭제
System.out.println(intList.get(0)); // 10
// 전체 삭제
intList.clear();
System.out.println(intList.toString()); // []- LinkedList
- 데이터 삽입, 삭제가 빈번할 경우 데이터의 위치정보만 수정하면 됨
- 메모리에 남는 공간을 요청해서 실제 값을 여기저기 나누어서 담아놓음
- 실제 값이 있는 주소값으로 목록을 구성하고 저장하는 자료구조
- 기본적 기능은 ArrayList 와 동일
- 값을 여기저기 나눠놓았으므로 조회 속도는 느리고 값을 추가하거나 삭제할 때는 빠름
- 조회할 때 처음부터 순회 검색을 해야하기 때문에 데이터의 수가 많아질수록 효율이 떨어지는 구조
LinkedList<Integer> linkedList = new LinkedList<Integer>(); // 선언 + 생성
// 추가
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
// 조회
System.out.println(linkedList.get(1)); // 2 (1번째 인덱스)
System.out.println(linkedList.toString()); // [1, 2, 3] (전체 배열 조회)
// 중간에 값 추가
linkedList.add(2, 4); // 2번째 인덱스 자리에 값 4 추가
System.out.println(linkedList.toString()); // [1, 2, 4, 3]
// 수정
linkedList.set(1, 30); // 1번째 인덱스 수정
System.out.println(linkedList.get(1)); // 30 (1번째 인덱스)
// 삭제
linkedList.remove(1); // 1번째 인덱스 삭제
System.out.println(linkedList.toString()); // [1, 4, 3]
// 전체 삭제
linkedList.clear();
System.out.println(linkedList.toString()); // []- Stack
- 수직으로 값을 쌓아놓고 넣었다가 뺌 (FILO)
Stack<Integer> intStack = new Stack<Integer>(); // 선언 + 생성
// 추가
intStack.push(1);
intStack.push(2);
intStack.push(3);
// 조회
System.out.println(intStack.get(1)); // 2 (1번째 인덱스)
System.out.println(intStack.toString()); // [1, 2, 3] (전체 배열 조회)
System.out.println(intStack.peek()); // 3 (제일 마지막 추가 값 조회)
System.out.println(intStack.size()); // 3 (배열의 크기(사이즈) 조회)
// 다 지워질 때 까지 출력 (나중에 추가한 값부터 출력)
while (!intStack.isEmpty()) {
System.out.println(intStack.pop());
} // 3
2
1- Vector
- ArrayList와 동일한 내부구조를 가짐
- 과거 대용량 처리를 위해 사용했으나 내부에서 자동으로 동기화처리가 일어나 비교적 성능이 좋지 않고 무거워 잘 쓰이지 않음
■ Set
순서가 없음
데이터 중복 불가
Set은 생성자가 없는 껍데기라서 바로 생성할 수 없고 HashSet, TreeSet 등으로 응용해서 사용 가능
- HashSet
- 순서를 예측할 수 없음
- TreeSet
- 정렬 방법을 지정할 수 있음
Set<Integer> intSet = new HashSet<>(); // 선언 + 생성
// 추가
intSet.add(1);
intSet.add(12);
intSet.add(5);
intSet.add(9);
intSet.add(1);
intSet.add(12);
// 조회
System.out.println(intSet.toString()); // [1, 5, 9, 12]
for (Integer value: intSet) {
System.out.println(value);
} // 1 (중복 없음)
5
9
12
// 포함 여부
System.out.println(intSet.contains(2)); // false
System.out.println(intSet.contains(5)); // true■ Queue
- 먼저 들어간 자료가 먼저 나오는 구조 (FIFO)
- 생성자가 없는 인터페이스이므로 LinkedList를 활용해서 생성해야 함
Queue<Integer> intQueue = new LinkedList<>(); // 선언 + 생성
// 추가
intQueue.add(1);
intQueue.add(2);
intQueue.add(3);
// 조회
System.out.println(((LinkedList<Integer>) intQueue).get(1));
// 2 (1번째 인덱스)
System.out.println(intQueue.toString()); // [1, 2, 3] (전체 배열 조회)
System.out.println(intQueue.peek()); // 1 (제일 먼저 추가한 값 조회)
System.out.println(intQueue.size()); // 3 (배열의 크기(사이즈) 조회)
// 다 지워질 때까지 출력 (먼저 추가한 값부터 출력)
while (!intQueue.isEmpty()) {
System.out.println(intQueue.poll());
} // 1
2
3■ Map
Key-Value 형태 자료구조
순서가 없음
Key는 중복 불가, Value는 중복 허용
Set처럼 HashMap, TreeMap 등으로 응용해서 사용 가능
- Hashtable
- null 불가
- HashMap
- null 허용
- TreeMap
- 정렬된 순서대로 Key-Value를 저장하여 검색이 빠름
Map<String, Integer> intMap = new HashMap<>(); // 선언 + 생성
// 추가
intMap.put("일", 11);
intMap.put("이", 12);
intMap.put("삼", 13);
intMap.put("삼", 14); // 중복 key
intMap.put("삼", 15); // 중복 key (key가 중복되면 제일 나중에 입력된 value로 저장됨)
// 조회
System.out.println(intMap.toString()); // {이=12, 일=11, 삼=15}
System.out.println(intMap.get("삼")); // 15
for (String key: intMap.keySet()) {
System.out.println(key);
} // 이 (key 값 하나씩 전체 조회)
일
삼
for (Integer value: intMap.values()) {
System.out.println(value);
} // 12 (value 값 하나씩 전체 조회)
11
15