
8.1 Records (Structures)
: heterogeneous한 것들을 묶기 위해 사용한다.
: 클래스와 유사하다고 보지만, 상속은 불가능하다.
element copper;
const double AN = 6.022e23; /* Avogadro’s number */
...
copper.name[0] = ‘C’; copper.name[1] = ‘u’;
double atoms = mass / copper.atomic_weight * AN;- 각 필드에 접근할 수 있으며 언어마다 방식은 다르다.
- Cobol:
name of copper, Fortran 90:copper%name
- Cobol:
- 구조체 내에 구조체가 들어갈 수 있다.
8.1.2 Memory Layout and Its Impact
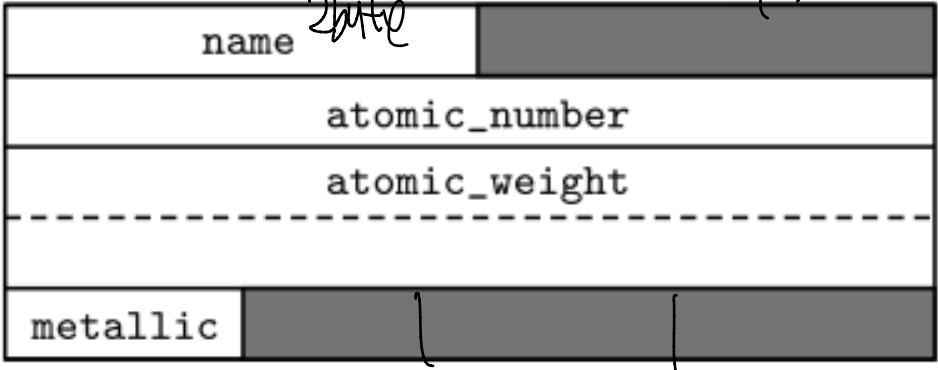
- Symbol table에서 컴파일러는 각 레코드 유형 내의 각 필드의 오프셋을 추적할 수 있다.
- 위의 경우 메모리 access 시간을 높이기 위해서 필요에 따라 공간을 버리기도 한다.
Value Model
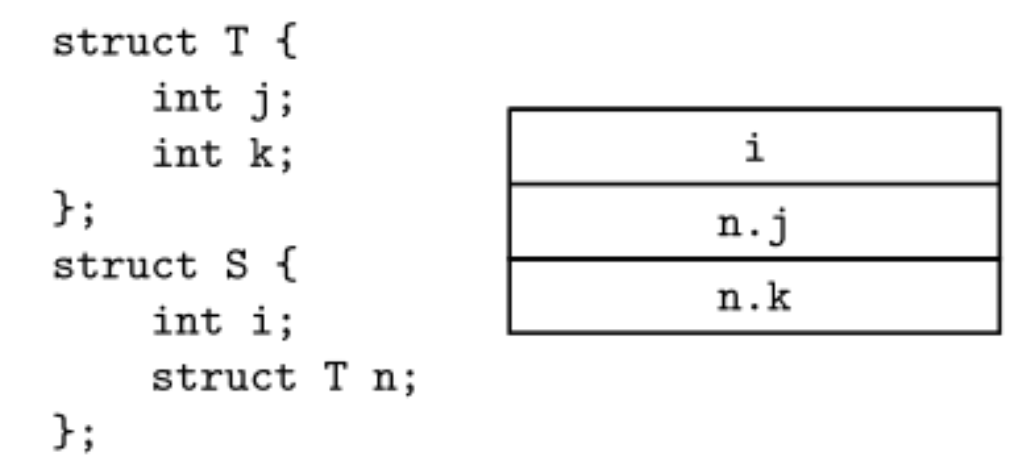
- value 모델을 따른다면, 구조체 내에 구조체를 넣는다면 위의 버린 공간과 같이 새로 공간을 차지한다.
struct S s1;
struct S s2;
s1.n.j = 0;
s2 = s1;
s2.n.j = 7;
printf("%d\n", s1.n.j); /* 0 */- s1 과 s2는 분리된다.
Reference Model
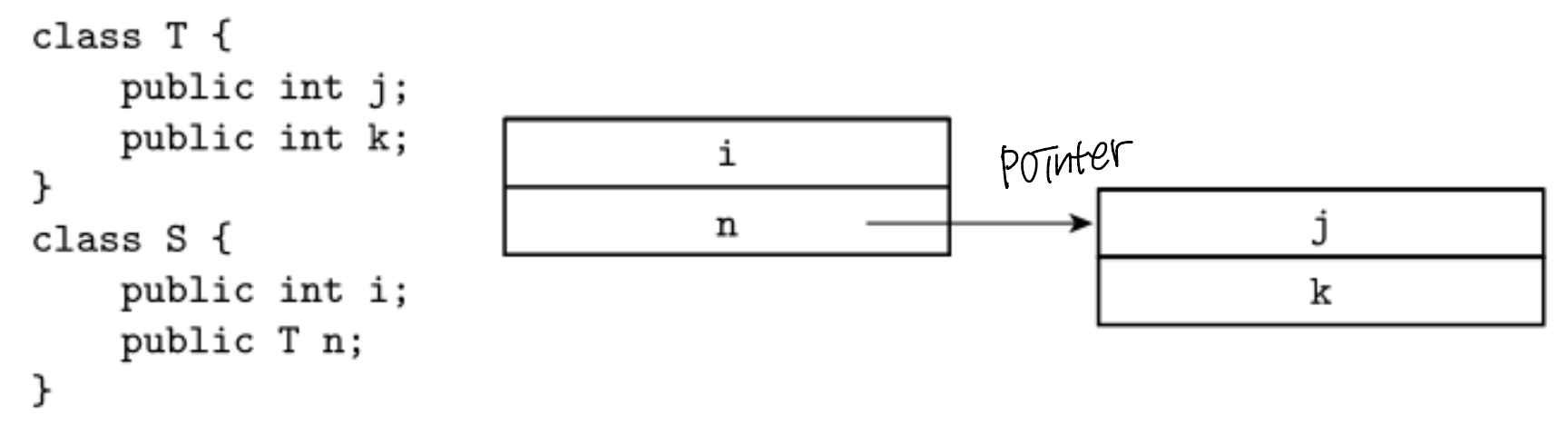
- reference 모델을 따른다면 다른 위치에 있는 data를 가리키도록 한다.
S s1 = new S();
s1.n = new T(); // fields initialized to 0
S s2 = s1;
s2.n.j = 7;
System.out.println(s1.n.j); // prints 7- reference만 가져와 사용하는 경우이므로, s2를 수정하면 s1도 수정되는 것이다 (alias)
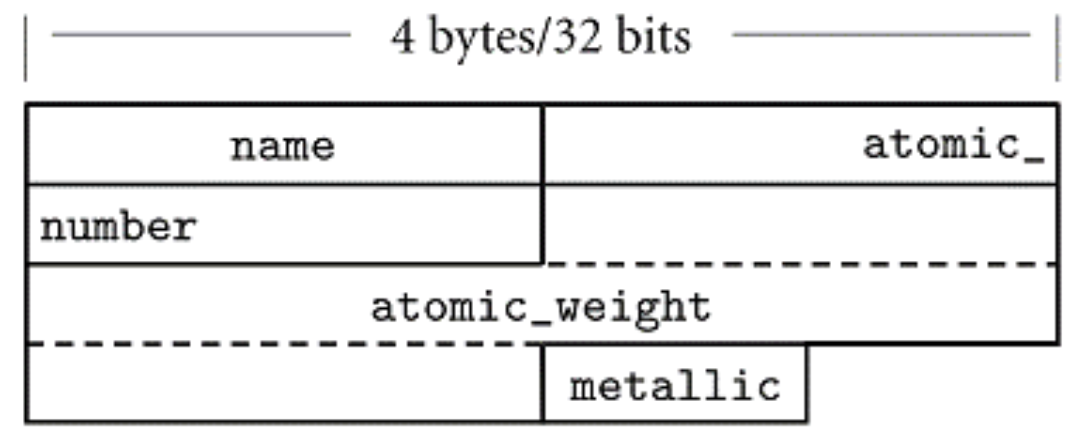
Packed
: 속도가 느려지더라도 최소한의 공간을 차지하도록 한다.
Copies and Comparisons
- record를 복사할 수 있고, 비교를 할 수도 있다.
- in-line copy
: 구조체의 필드에 접근해서 하나씩 카피하는 방식 - library routine
: 긴 경우, 라이브러리를 이용해 블럭 카피를 제공한다.memcpy() - block_compare
:memcmp()를 통해서 비교를 제공한다.
가비지 값이 들어갈 수 있다 -> fail 가능성 높여줌 -> 예측 가능한 값 넣기 or 컴파일러가 비교하는 루틴을 만든다.
-
Hole로 인해서 메모리를 낭비하고 비교를 복잡하게 한다.
- record의 field의 순서를 바꾼다.(바이트 작은 순으로 순서 지정)
- 하지만 system program에서 문제가 발생할 수 있다.
- 따라서 순서를 바꾸지 않고, 첫 번째 field의 경우 새롭게 시작하도록 한다.
-
언어에 따라서, 프로그래머가 몇 바이트를 차지할 것인지 정하는 언어가 존재한다. (Ada, C, C++)
8.1.3 Variant Records (Unions)
union {
int i;
double d;
_Bool b;
};- 동시에 사용하지 않는다는 가정하에 필드의 가장 큰 바이트의 메모리를 할당한 후, 메모리를 공유한다.
- 시스템 프로그램을 할 때 다른 방법으로 같은 데이터를 사용할 때 사용한다.
- ex) double 이라고 넣어두고 char chs[8]으로 뽑는다.
- 구조체에서 때에 따라 다르게 사용되는 덩어리되어 있는 필드가 존재할 수 있다.
- ex) 요구조건(salaried, hourly, or consulting basis)에 따라서 다른 내용(names, address, phone, department, ID number) 뽑을 때 사용
8.2 Arrays
: homogeneous 한 요소로 구성된다.
- discrete type 으로 인덱스를 지정한다.
- nondiscrete index types도 허용한다.
- hash table, search tree로 구성된다.
Ada
mat1 : array (1..10, 1..10) of long_float;
mat2 : matrix(1..10);- mat1: 2차원 배열, mat2: 1차원 배열
C
double mat[10][10];: mat[2] 인 경우, reference를 의미한다.
8.2.3 Memory Layout
: 첫 번째 요소의 다음이 오른쪽으로 갈 것인지?(row major), 아래로 갈 것인지? (column-major)
Row-Pointer Layout
- row가 메모리의 아무데나 존재하며, 각각의 row를 가리키는 배열이 존재한다.
- 대부분 많은 공간을 차지하지만 이점이 존재한다.
- 메모리 계산을 하는 것이 아니므로 쉽고 빠르게 접근할 수 있다.
- 다른 길이의 row를 가질 수 있다.
- 이미 존재하는 row를 재사용할 수 있다.
- C, C++: arrays of string에 예외적으로 허용한다.

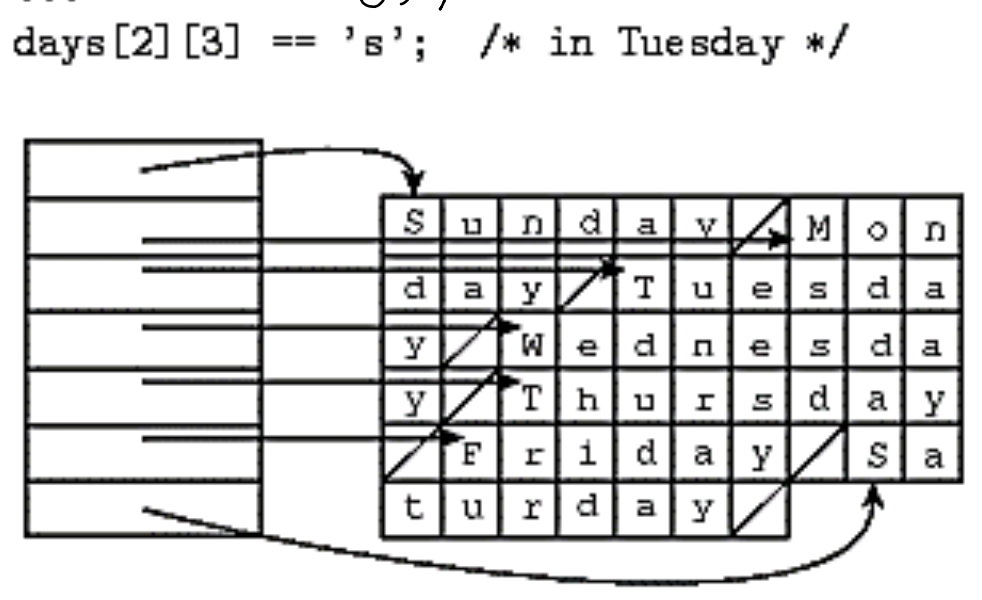
- Java: object type의 모든 arrays에 row-pointer layout을 사용한다.
8.3 Strings
: '', "" 로 둘러써여있는 형태
- C/C++: literal characters, literal strings 구별한다.
- Pascal: Character는 길이가 1인 String
- C++/Java: String은 가변적 길이를 허용해준다.
- 가변 길이 문자열의 조작은 수많은 컴퓨터 응용 프로그램의 기본적인 기능이다.
- 1차원적이고 1바이트 요소를 가지며 다른 reference를 포함되어 있지 않기 때문에 구현이 쉽다.
- C언어는 Character의 집합을 String으로 취급한다.

💻 ☕️ 🏝 🍑 🍹 🏊♀️