화이트 박스 테스트 기법
기초 경로 검사
(Base Path Testing) - 대표적인 화이트박스 테스트 기법이다.
- 테스트 케이스 설계자가 절차적 설계의 논리적 복잡성을 측정할 수 있게 해주는 테스트 기법, 테스트 측정 결과는 실행 경로의 기초를 정의하는 데 지침으로 사용된다.
제어 구조 검사
(Control Structure Testing) - 조건 검사(Condition Testing): 프로그램 모듈 내에 있는 논리적 조건을 테스트하는 테스트 케이스 설계 기법
- 루프 검사(Loop Testing): 프로그램의 반복(Loop) 구조에 초점을 맞춰 실시하는 테스트 케이스 설계 기법
- 데이터 흐름 검사(Data Flow Testing): 프로그램에서 변수의 정의와 변수 사용의 위치에 초점을 맞춰 실시하는 테스트 케이스 설계 기법
테스트커버리지★ 시스템 및 소프트웨어에 대해 충분히 테스트가 되었는지를 나타내는 정도
구문 커버리지(statement Coverage) : 모든 명령문을 적어도 한 번 수행
결정 커버리지(Decision Coverage) : 결정 포인트 내의 전체 조건식이 적어도 한 번은 참과 거짓의 결과를 수행
조건 커버리지(Condition Coverage) : 결정 포인트 내의 각 개별 조건식이 적어도 한 번은 참과 거짓의 결과를 수행
조건/결정 커버리지(Codition/Decision Coverage) : 전체 조건식뿐만 아니라 개별 조건식도 참과 거짓의 결과를 수행
변경 조건/결정 커버리지(MCDC) : 개별 조건식이 다른 개별 조건식에 영향을 받지않고 전체 조건식에 독립적으로 영향을 주도록 향상시킨 커버리지
다중 조건 커버리지(Multiple Condition Coverage) : 모든 개별 조건식의 모든 가능한 조합을 100% 보장하는 커버리지
블랙박스 테스트 기법
동등분할기법 (Equivalence Partitioning)
입력 데이터의 영역을 유사한 도메인별로 그룹핑하여 대푯값 테스트 케이스 도출
입력 데이터에 따른 결과값을 테스트할 때 사용되는 기법으로 입출력 데이터에 따라 다르게 동작하는 기능을 테스트하는 경우에 사용된다.
소프트웨어에서 요구하는 입력 데이터를 그룹화하여 해당 그룹에 속하는 값으로 결과값을 비교한다.
Feature: 성적 관리 기능
Scenario: 점수에 따른 학점을 계산한다.
When: 90점을 입력한다.
then: A학점이 나온다.경계값 분석 테스트(Boundary Value Analy)
등가 분할 후 경곗값 분석에서 오류 발생확률이 높기 때문에 경곗값을 포함하여 테스트 케이스 도출
경계가 뚜렷한 입력 데이터에 따른 동작을 검사할 때 사용되는 기법으로 입력 조건의 경계에 해당하는 값들에서 에러가 발생할 확률이 높다는 점을 이용하여 검사를 진행한다.
Feature: 오전/오후 도출 기능
Scenario: 시간에 따른 오전/오후를 구한다.
When: 1시를 입력한다.
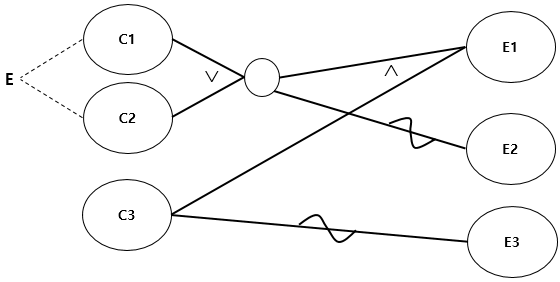
then: 오후라는 결과가 나온다.원인 - 효과 그래프(Cause Effect Graph)
원인-결과 그래프를 통해 요구사항 명세를 입력및 출력 조건 간의 논리적 관계로 표현하고 이를 기반으로 테스트 케이스를 만들어낸다.
여러 원인들을 논리적으로 IDENTITY, AND, OR, NOT연산으로 연관지어 결과를 도출할 수 있고, 뿐만아니라 E(exclusive), I(inclusive), O(one and only one), R(requires) 제약 심볼을 적용할 수 있다.
입력 데이터 간의 관계와 출력에 영향을 미치는 상황을 체계적으로 분석한 다음 효용성이 높은 테스트 케이스를 선정하여 검사하는 기법이다.
비교 테스트 : 여러 버전의 프로그램에 입력값을 넣어서 동일한 결과가 나오는지 비교해 보는 테스트 기법
오류예측기법 : 경험이 있는 전문가의 예측
페이지 교체 알고리즘
OPT(OPTimal replacement, 최적 교체
-
앞으로 가장 오랫동안 사용하지 않을 페이지를 교체하는 기법
-
페이지 부재 횟수가 가장 적게 발생하는 가장 효율적인 알고리즘
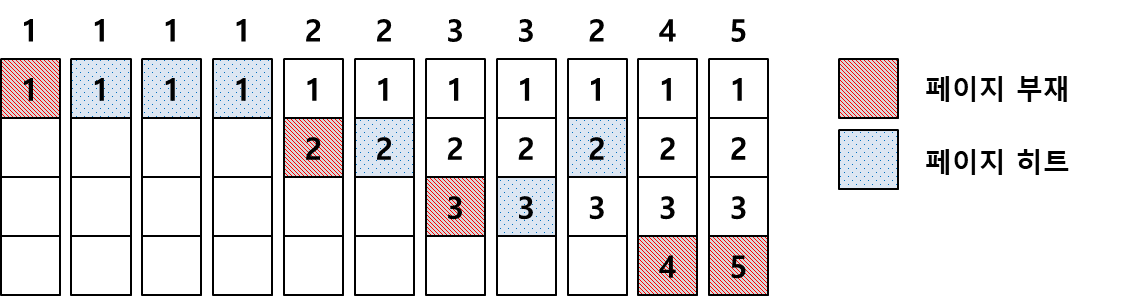
FIFO(First in first out)
-
각 페이지가 주기억장치에 적재될 때마다 그때의 시간을 기억시켜 가장 먼저 들어와서 가장 오래 있었던 페이지 교체
-
이해하기 쉽고, 프로그래밍 및 설계 간단
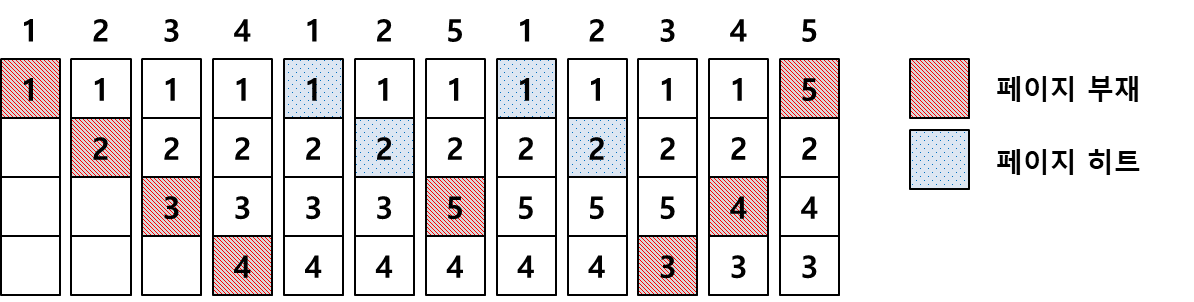
LRU(Least Recently Used)
-
최근에 가장 오랫동안 사용하지 않은 페이지를 교체하는 기법
-
각 페이지마다 계수기나 스택을 두어 현 시점에서 가장 오랫동안 사용하지 않은, 즉 가장 오래 전에 사용된 페이지를 교체
LFU(Least Frequently Used)
-
사용빈도가 가장 적은 페이지를 교체
-
활발하게 사용되는 페이지는 사용 회수가 많아 교체되지 않음
NUR(Not Used Recently)
-
최근에 사용하지 않은 페이지를 교체
-
최근에 사용되지 않은 페이지는 향후에도 사용되지 않을 가능성이 높다는 것을 전제로 , LFU에서 나타나는 시간적인 오버헤드를 줄일 수 있음
프로세스 스케줄링 알고리즘
반환시간 = 대기시간 + 실행시간
대기시간 = 이전 프로세스들의 실행시간 - 자신의 도착시간
5개의 작업에 대한 도착시간과 CPU 사이클 시간이 아래표와 같다고 하고 다음 물음에 답하시오.

SJF 평균대기시간:
SJF 평균반환시간:
SRT 평균대기시간:
SRT 평균반환시간:
인터페이스 구현
REST (Representational State Transfer)
- 웹과 같은 분산 하이퍼미디어 환경에서 자원의 존재 및 상태 정보를 표준화된 HTTP 메서드로 주고 받는 웹 아키텍쳐
- JSON 문서를 이용
AJAX (Asynchronous Javcascript And XML)
- 자바스크립트를 사용하여 웹 서버와 클라이언트 간 비동기적으로 XML 데이터를 교환하고 조작하기 위한 웹 기술
- 브라우저 내의 XML Http Request 객체를 이용하여 전체 페이지 로드 없이 일부 페이지의 데이터만 로드
XML (Extensible Markup Language)
- HTML의 단점을 보완하고 SGML의 복잡성을 개선한 마크업 언어
- 인간과 기계가 모두 이해할 수 있는 텍스트 형태로 마크업 포맷을 정의하기 위한 메타언어
JSON (Javascript Object Notation)
- 속성-값 또는 키-값으로 이루어진 데이터 객체를 전달하기 위해 텍스트로 작성하는 개방형 표준 포맷
- AJAX에서 많이 사용되는 방식
- XML을 대체하는 주요 데이터 포맷
DBMS
공유데이터: 데이터베이스는 특정 조직의 여러 사용자가 함께 소유하고 이용할 수 있어야 하는 공용 데이터
저장데이터: 데이터베이스의 데이터는 주로 컴퓨터가 처리하므로, 컴퓨터가 접근할 수 있는 매체에 데이터베이스를 저장
통합데이터: 데이터 베이스는 데이터 중복성, 즉 똑같은 데이터가 여러 개 존재 하는 것을 허용하지 않는다
운용데이터: 일시적으로 사용하고 마는 것이 아닌, 지속적으로 유지해야 하는 데이터
데이터베이스 모델링 종류
개논물
개념적 데이터 모델링
추상화 수준 높음
업무중심적이고 포괄적인 수준의 모델링 진행
전사적 데이터 모델링
EA 수립시 많이 이용
논리적 데이터 모델링
시스템으로 구축하고자 하는 업무에 대해 Key, 속성, 관계 등을 정확하게 표현
재사용성 높음
물리적 데이터 모델링
실제로 데이터베이스에 이식할 수 있도록 성능, 저장 등 물리적인 성격을 고려하여 설계
데이터베이스 스키마 구조 3단계
외개내
외부 스키마 : 개개인 사용자가 보는 개인적 DB 스키마
외부 단계에서 사용자에게 필요한 데이터베이스를 정의한 것
개념 스키마 : 모든 사용자 관점을 통합한 전체 DB
조직의 모든 응용시스템에서 필요로 하는 개체 관계, 그리고 제약조건들을 포함하고 있게 됩니다.DB를 효율적으로 관리하는데 필요한 접근권한, 보안정책, 무결성 규칙등에 관한 사항들도 추가적으로 포함
- 데이터 베이스의 전체적인 논리적 구조
- 데이터 베이스에 실제로 어떤 데이터가 저장되었으며 데이터간의 관계는 어떻게 되는가
- 모든 응용프로그램이나 사용자들이 필요로하는 데이터를 종합한 조직전체의 데이터베이스
- 개체간의 관계와 제약조건 명시
- 데이터 베이스의 접근 권한 보안 및 무결성 규칙에 관한 명세를 정의
- 단순한 스키마라고 하면 개념스키마를 의미- 기관이나 조직체의 관점에서 데이터베이스를 정의
- 데이터베이스 관리자 (DBA)에 의해 구성 * 데이터 베이스당 하나만 존재
내부 스키마 : 물리적 장치에서 데이터가 실제적 저장
물리적인 저장장치 입장에서 DB가 저장되는 방법을 기술한 것구체적으로 개념 스키마를 디스크 기억장치에 물리적으로 구현하기 위한 방법을 기술한 것으로서 주된 내용은 실제로 저장될 내부레코드 형식, 내부레코드의 물리적 순서, 인덱스의 유/무 등에 관한 것입니다.
⭐ 데이터 독립성
논리적 독립성 : 개념스키마가 변경되어도 외부스키마에 영향 X
물리적 독립성 : 내부스키마가 변경되어도 외부/개념스키마에 영향 X
✅ Mapping(사상) : 상호 독립적인 개념을 연결시켜주는 다리
논리적 사상 : 외부 스키마 ~ 개념 스키마
물리적 사상 : 개념 스키마 ~ 내부 스키마
⭐ 데이터 모델링의 3요소
어떤 것(Things)
성격(Attributes)
관계(Relationships)
세타조인
조인에 참여하는 두 릴레이션의 속성값을 비교하여 조건을 만족하는 튜플만 반환하는 조인이다.
크로스조인
조건 없이 두 테이프를 조합
동등조인
세타조인에서 = 연산자를 사용한 조인으로 일반적으로 조인이라고 하면 동등조인을 의미한다.
자연조인
동등조인의 결과 릴레이션에서 중복된 속성을 제거하여 수행하는 연산. 즉 동등조인에서 중복속성 중 하나가 제거된 것이다. 자연조인의 핵심은 두 릴레이션의 공통된 속성을 매개로 하여 두 릴레이션의 정보를 관계로 묶어내는 것이다.
관계대수
관계형 데이터베이스 내에서 원하는 정보를 어떻게 찾아낼 수 있는가를 기술하는 절차적인 언어이다.
관계해석
관계데이터의 연산을 표현하는 방법으로, 관계데이터모델의 제안자인 코드가 수학을 술어 해석에 기반을 두고 관계데이터베이스를 위해 제안했다.
정규화 순서

제 1 정규화 : 테이블 한칸에 그렇게 큰 건 안들어가아아앗
제 2 정규화 : 따까리를 데리고 나타나다니... 네 녀석은 사나이(composite primary key)자격이 없다
제 3 정규화 : 알빠노들은 알빠노 테이블로 이동
회선교환방식
회선 교환 circuit switching 방식은 먼저 메시지 전송로인 회선 circuit을 설정하고 이를 통해 메시지를 주고받는 방식입니다. ‘회선을 설정한다’라는 말은 ‘두 호스트가 연결되었다’, ‘전송로를 확보하였다’라는 말과도 같습니다. 회선 교환 네트워크에서는 호스트들이 메시지를 주고받기 전에 두 호스트를 연결한후, 연결된 경로로 메시지를 주고받습니다.
예를 들어서 다음 그림과 같은 회선 교환 네트워크에서 A와 B가 통신하려고 한다면, 메시지를 주고 받기 전에 A와 B 사이를 연결하는 회선(붉은 선)을 설정해야 이 경로를 통해 메시지를 주고받을 수 있습니다.
-> 많은 데이터를 오랜 시간 전송하는 경우에 적합함
패킷교환방식
- 패킷교환이란 일정한 데이터 블록인 패킷을 교환기가 수신측 주소에 따라 적당한 통신경로를 선택하여 전송하는 교환방식
- 전송하고자 하는 정보를 일정한 크기의 데이터로 분할한 후, 송수신 주소인 헤더를 각각에 부가한 패킷단위로 전송하는 방식
패킷 교환 packet switching 방식은 회선 교환 방식의 문제점을 해결한 방식으로, 메시지를 패킷이라는 작은 단위로 쪼개어 전송합니다. 여기서 패킷 packet은 패킷 교환 네트워크상에서 송수신되는 메시지의 단위입니다. 현대 인터넷은 대부분 패킷 교환 방식을 이용합니다.
예를 들어서 우리가 패킷 교환 방식으로 2GB 크기의 영화 파일을 다운로드한다면, 2GB 크기의 영화 파일이 한 번에 컴퓨터로 전송될까요? 아닙니다. 패킷의 크기만큼 분할되어 전송됩니다. 그리고 이렇게 쪼개진 패킷들은 수신지인 컴퓨터에 도달한 뒤 재조립됩니다.
사전에 설정된 경로만으로 통신하는 회선 교환 방식과는 달리, 패킷 교환 방식은 정해진 경로만으로 메시지를 송수신하지 않습니다.
이 과정에서 메시지는 다양한 중간 노드를 거칠 수 있는데, 이때 중간 노드인 패킷 스위치는 패킷이 수신지까지 올바르게 도달할 수 있도록 최적의 경로를 결정하거나 패킷의 송수신지를 식별합니다. 대표적인 패킷 스위치 네트워크 장비로는 라우터 router와 스위치 switch가 있습니다.
->짧은 실시간 전송에 적합함
경로설정: 발신자와 목적지가 직접 연결되지 않으므로 각 패킷을 네트워크를 통해서 노드에서 노드로 보내는 기능
트레픽제어: 네트워크에 전송되어지는 트래픽의 양을 효율적이고 안정하게 하기 위해서 통제하는 기능
에러제어: 네트워크에서 유실되는 패킷에 대해 제어하는 기능
가상회선 패킷교환 (TCP)
데이터를 전송하기 전 논리적 연결 설정 연결 지향형
데이터그램 패킷교환 (UDP)
데이터를 전송하기 전에는 논리적 연결이 설정되지 않으며 패킷이 독립적으로 전송됨 비연결 지향형
메시지 교환방식
송신된 메시지를 중앙에서 축적하여 처리하는 방법으로 흔히 축적교환방식이라고 한다. 메시지를 메모리에 저장하고 여러 수신자에게 데이터를 전송할 수 있다.
RIP 경로 문제 (거리벡터 알고리즘)
Routing Information Protocol 의 약자로, 거리벡터 알고리즘을 기반으로 개발된 동적 라우팅 알고리즘이다.
인접한 라우터의 라우팅 테이블 정보를 수집해 저장하고, 수집한 정보에서 Hop Count 가 가장 작은 경로로 라우팅을 하게된다.
IGP 로 많이 이용되는 프로토콜.
RIP 특징
중간에 거치는 홉(hop) Count 를 기준으로 Hop Count가 가장 작은 최적의 경로를 찾는다.
최대 Hop Count는 15이다.
자신의 라우팅 테이블을 30초 주기로 전파한다.
패킷이 목적지로 가는 동안 거치는 라우터 수가 최소가 되도록 경로를 선택
OSPF 경로 문제 (링크상태알고리즘)
링크 상태 정보를 모든 라우터에게 전달해 최단 경로 트리를 구성하는 라우팅 프로토콜 알고리즘
Network에 대한 전반적인 정보(Topology, path)를 가지고 라우터와 라우터 간 가능성 있는 모든 경로 정보를 교환
거리와 대역폭에 따라 경로를 계산하고 어떤 링크의 변화가 있는 경우만 정보를 전달하는 방식
흐름 제어(Flow Control)와 혼잡 제어(Congestion Control)
흐름 제어
흐름 제어는 데이터 송신하는 곳과 수신하는 곳의 데이터 처리 속도를 조절해 수신자의 버퍼 오버플로우를 방지하는 것이다.
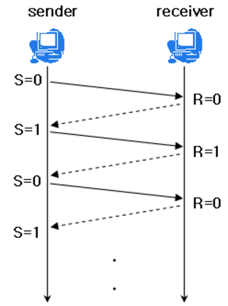
Stop and wait 정지와 대기
매번 전송한 패킷에 대한 확인 응답을 받아야만 그 다음 패킷을 전송하는 기법
Sliding Window(Go-Back-n ARQ)
수신측에서 설정한 윈도우 크기만큼 송신측에서 패킷 각각에 대한 확인 응답없이 세그먼트를 전송하게 하고, 데이터 흐름을 동적으로 조절하는 기법
전송은 되었으나, ACK 을 받지 못한 Byte 크기를 파악하기 위해 사용
윈도우 크기만큼 패킷을 모두 전송하고, 그 패킷들의 전달이 확인되는대로 해당 윈도우를 옆으로 슬라이딩하면서 그 다음 패킷을 전송하는 방식으로 동작
혼잡 제어
혼잡 제어는 네트워크 내의 패킷 수가 넘치지 않도록 방지하는 것이다. 만약 패킷이 많아지면 혼잡 붕괴 현상이 일어날 수도 있기 때문이다.
프로세스 상태전이
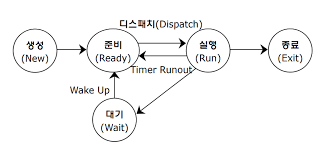
준비와 실행사이에선 문맥교환이 일어남
순서 및 디스패치와 WAKE UP 외워두기
(테일러링) 소프트웨어 개발 방법론의 절차, 사용기법을 수정 및 보완
(SOAP) HTTPS/SMTP와 XML을 교환하기 위한 통신규약
(WSDL) UDDI의 기초이며, SOAP와 XML 스키마와 결합하여 인터넷에 웹서비스를 제공하기 위해 사용됨
(표의 숫자코드): 코드화 대상항목의 물리적 수치를 그대로 코드에 적용
(중재자 패턴): 수많은 객체들 간의 복잡한 상호작용을 캡슐화하여 객체로 정의하는 패턴
(프록시 패턴): 복잡한 시스템을 개발하기 쉽도록 클래스나 객체들을 조합하며 객체 캡슐화
(IPsec): IP 패킷 단위 데이터변조 방지 및 은닉 기능 제공하는 프로토콜
(xUnit): 단위테스트 프레임워크
(STAF): 서비스 호출 및 컴포넌트 재사용 테스트 프레임워크
(FitNesse): 웹 기반 테스트 케이스 설계 및 실행을 지원
(NTAF) FitNesse와 STAF를 통합
(watir) 인터프리터 방식의 객체지향 스크립트 언어인 Ruby를 사용하는 애플리케이션 테스트 프레임워크
(SEED) 한국정보보호진흥원의 기술진이 개발한 대칭키 암호 알고리즘
(ISMS) 국내 정보보호관리 체계
(CC인증) 나라별 인증체계가 다른데 이를 연동시켜줌
(AAA) 사용자의 컴퓨터 자원 접근에 대한 처리 및 서비스 제공, 인증, 인가, 과금
(TearDrop) offset 값을 변경시켜 수신 측에서 패킷을 재조립할 때 오류로 인한 과부화 발생시킴
(NAC) MAC주소 IP관리시스템에 등록한 후 보안 솔루션
(SIEM) 로그 및 보안이벤트 통합
(백도어) 개발자가 몰래 만든 보안 없는 후문으로 들어가는 거
(DDE) 마이크로소프트 오피스와 애플리케이션 사이의 프로토콜
(멀버타이징) 멀웨어 없이 깨긋한 환경에서도 광고에 의해 악성코드가 유포됨
(바이러스) 자가복제 기능없음. 숙주가 필요함. 주로 파일에서 섞임
(웜) 자가복제 기능 있음. 호스트 파일 필요 없
(크리덴셜 스터핑) 로그인 자격증명을 다른계정에 무작위 대입
(스니핑) 몰래 훔쳐보는거;;
(매시업) 웹에서 제공하는 정보 및 서비스를 이용하여 새로운 소프트웨어, 서비스, 디비를 만듬
(SOA) 서비스 단위나 컴포넌트 중심으로 구축하는 정보기술 아키텍처
(디지털트윈) 현실 속 사물을 소프트웨어로 가상화
(시맨틱 웹) 컴퓨터가 사람을 대신하여 정보를 읽고 이해하고 가공하여 새로운 정보를 만들어냄
(앤스크린) TV, PC 등 다양한 기기에서 하나의 콘텐츠 계속 시청 ㅇㅇ
(신 클라이언트 PC) 단말기 PC인데 최소한으로 갖춘 PC
(엠디스크) 걍 수명 ㅈㄴ 긴 저장장치
(멤리스터) 전자신호의 값에 따라 저항이 변하는 전자소자
(멤스) 미세전자기시스템
(트러스트존 기술) 하드웨어 기반의 보안기술
(하둡) 오픈소스를 기반으로 한 분산 컴퓨팅 플랫폼
(맵리듀스) 대용량 데이터 분산처리 목적으로 개발된 프로그래밍 모델
(데이터 마이닝) 걍 빅데이터에서 필요한 데이터 추출
(타조) 아파치 하둡 기반의 분산 데이터 웨어하우스 프로젝트
(OLAP) 다차원으로 이루어진 데이터로부터 통계적인 요약정보를 분석하여 의사결정에 활용하는 방식이다
(브로드 데이터) 새로운 데이터나 기존 데이터에 새로운 가치가 더해진 데이터. 걍 다크데이터의 반대라고 생각하자.
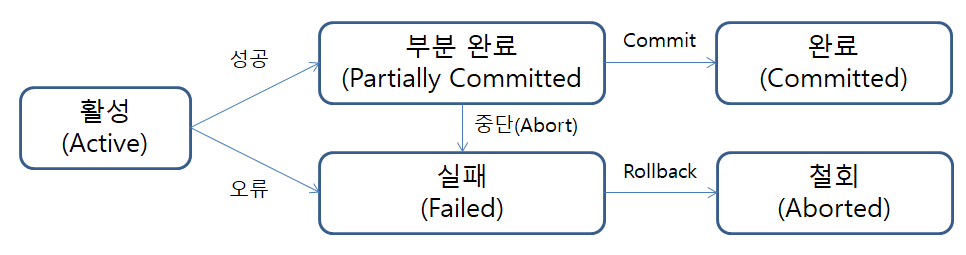
트랜잭션 상태
형상관리 기능
- 형상식별: 형상관리 대상에 이름과 관리 번호를 부여하고 계층구조로 구분하여 수정 및 추적이 용이하도록 하는 작업
- 버전제어: 소프트웨어 업그레이드나 유지보수 과정에서 생성된 다른 버전의 형상 항목관리
- 형상통제: 변경 요구를 검토하여 현재 기준선이 반영되도록 함
- 형상감사: 기준선의 무결성을 평가하기 위함
- 형상기록: 형상의 식별, 통제, 감사작업의 결과 기록
(리포지토리) 최신 버전의 파일들과 변경 배역에 대한 정보 저장
(가져오기) 아무것도 없는 저장소에 처음으로 파일 복사
(체크아웃) 프로그램 수정을 위해 저장소에서 파일 받아옴
(체크인) 파일 수정을 완료 후 저장소 파일 새로운버전으로 갱신
(커밋) 체크인 수행할 때 이전에 갱신된 내용이 있는 경우 충돌
(동기화) 저장소에 있는 최신 버전으로 자신의 저장공간 동기화
GIT, SVN, CVS
