파이썬은 속도가 느리다.
처음에 이 말을 들었을 때는 그냥 그런가 싶었다. C나 자바가 얼마나 빠른지 몰랐기 때문에 파이썬이 얼마나 느린지 몰랐고, 지금까지 코딩하면서 그렇게까지 빠른 속도를 요구하는 기능이 필요한 적이 없어서 그냥 파이썬의 특징인가 보다 하고만 넘어갔었다. 개발자로서 부끄럽지만 왜 파이썬의 속도가 느리다고 하는지 명확히 이해해볼 생각을 하지 않았다.
파이썬 알고리즘 인터뷰 라는 책을 읽으면서 파이썬 내부의 자료형이 어떻게 구현되어 있는지 알게 되었다. 그제서야 “파이썬의 속도가 느리다”는 말이 어떤 의미였는지 알게 되었다. 오늘의 아하 모먼트를 통해 알게 된 내용을 정리해놓으려고 한다.
파이썬은 모든 것이 객체이다
CPython의 GIL(Global Interpreter Lock)이 무엇인지 공부하면서 들어본 말이다. 객체라는 말을 들었을 때, 가장 처음 떠오른 것은 클래스였다. 파이썬이 클래스 기반으로 동작하는 객체 지향 언어라는 의미인가 싶었다. 정확히 어떤 의미인지 감이 잡히지는 않았지만 그래도 그 이후의 내용을 어느 정도 파악할 수 있었기 때문에 GIL이라는 개념을 이해함에 있어 필수적인 부분은 아니라고 생각해서 넘겼다.
지금 와서 알게되었다. 그때의 내 생각은 틀렸고 완전히 헛짚었다. 고민해보지 않고 넘긴 저 개념이 완전 핵심 개념이었다. 그 동안 ‘ok, 이해했다'고 생각했던 건 사실 이해한 게 아니었고, 얼레벌레 반 정도만 어렴풋이 알아먹고 있었던 거였다.
그럼 파이썬에서 모든 것은 객체라는 말이 의미하는 건 무엇일까?
원시 타입과 참조 타입
이 말은 파이썬이 데이터를 저장하는 방식과 관련이 있다. 파이썬에서 모든 데이터는 객체 형식으로 저장된다는 말로 바꿔볼 수 있을 것이다.
이를 이해하기 위해서는 메모리에 데이터가 어떻게 저장되는지 알아야 한다. 여기에는 두 가지 방식이 있는데, 하나는 원시 타입(Primitive Type)이고 다른 하나는 참조 타입(Reference Type)이다. 원시 타입이란, 변수에 데이터가 할당될 때 고정된 메모리 공간을 부여받고 거기에 데이터의 값(value)을 저장하는 방식의 데이터 타입이다. 반면, 참조 타입은 변수의 메모리 공간에 데이터의 값을 직접 저장하는 게 아니라, 해당 데이터의 값이 저장된 별도의 메모리 공간을 가리키는 주소값(reference)만을 저장하는 방식이다.
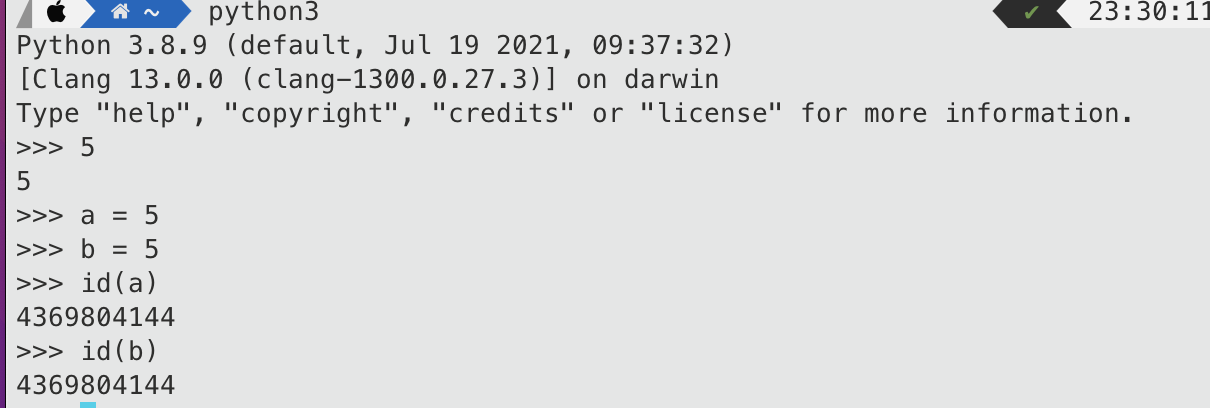
예를 들어, 각각 5라는 동일한 값을 가지는 두 변수 a와 b가 있다고 생각해보자.
두 변수가 원시 타입 자료형이라면 5라는 값이 저장되어 있는 메모리 공간은 각각 다르다. 변수 a의 메모리 공간에도 5라는 값이 저장되어 있고, 변수 b의 메모리 공간에도 5라는 값이 저장되어 있을 것이기 때문이다.
하지만 두 변수가 참조 타입 자료형일 경우에는 5라는 값은 두 변수의 메모리 공간과는 별도의 공간에 보관되며, 변수 a와 b의 메모리 공간에는 5라는 값이 저장되어 있는 공간의 주소값이 저장되어 있다. 그래서 변수 a와 b는 동일한 5를 가리킬 수도 있고, 각기 다른 5를 가리킬 수도 있다. 변수는 두 개이지만 각 변수가 가리키는 실제 데이터는 하나의 공간에 저장되어 있을 수도 있는 것이다.
아래는 참조 타입 자료형을 사용하는 파이썬의 예시이다. id() 함수는 해당 변수가 가지고 있는 값이 저장되어 있는 메모리 공간의 주소를 리턴하는 함수인데, 변수 a, b가 동일한 주소값을 가지고 있음을 알 수 있다.
파이썬의 원시 타입
그러면 파이썬은 원시 타입과 참조 타입을 어떻게 구현하고 있을까?
결론부터 말하자면 파이썬에는 원시 타입이 없다. 전부 참조 타입이다. 그리고 변수들이 참조하는 데이터는 모두 pyObject라는 객체 형식으로 이루어져 있다.
PyObject란, CPython에서 데이터를 관리하기 위한 구조체이다. 여기에는 이 객체가 참조되고 있는 횟수를 나타내는 값과 데이터의 자료형(str, int…)을 알려주는 값이 저장되어 있다.
고정된 메모리 공간만을 차지하는 원시 타입의 데이터와는 달리, 객체 형식의 데이터는 훨씬 많은 메모리 공간을 차지한다. 그 대신 다양한 속성과 메서드를 가질 수 있다. 파이썬이 원시 타입을 희생하고 객체 참조 방식을 선택한 이유는 사용 상의 편리함에 우선순위를 두고 있는 파이썬의 특징과 연관이 있는 것으로 보인다.
다양한 기능 제공에 초점을 맞추는 파이썬에서 str, int, list 등의 데이터 타입은 각 변수가 참조하고 있는 객체가 가질 수 있는 기능을 결정한다.
또한 파이썬은 메모리 관리를 레퍼런스 카운팅 기반의 가비지 콜렉터 방식을 사용하고 있는데, 이를 위해 각 데이터가 참조되고 있는 횟수를 별도로 저장해야 하는 이유도 있을 것이다.
파이썬의 속도가 느린 이유
파이썬의 속도가 느린 이유는 파이썬의 객체 참조 방식이 원시 타입에 비해 느리기 때문이다. 메모리에서 데이터를 꺼내서 확인하면 되는 원시 타입과는 달리, 파이썬은 해당 변수가 가리키는 객체의 PyObject_HEAD를 확인해서 데이터 타입 정보를 가지고 있는 typecode를 확인하고 거기에 해당되는 C의 자료형을 확인하는 일련의 작업이 필요하다. 배열 형태의 자료형이라면 할 일은 더 많아진다. 배열 역시 각각의 아이템의 값을 직접 들고 있는 게 아니라, 각 아이템이 해당 데이터가 보관되어 있는 메모리 공간을 가리키고 있는 포인터의 목록으로 구성된다. 따라서 아이템 하나를 조회할 때도 일일이 포인터를 따라가서 typecode를 확인하는 등의 작업이 요구된다.
그런데 파이썬은 동적 타이핑 인터프리터 언어이기 때문에, 컴파일 단계에서 데이터의 자료형에 대한 정보를 알고 있는 정적 타이핑 컴파일 언어와는 다르게 객체의 PyObject_HEAD에 typecode를 설정하고 읽어오는 작업이 모두 실행 시간에 이루어진다. 그래서 느리다.
요약
파이썬의 속도가 느린 이유는
- 데이터를 객체 형식으로 저장하고, 각 변수는 객체들을 참조하는 방식으로 동작하기 때문에 데이터를 읽고 쓰는 데 할 일이 많아서 시간이 오래 걸리고,
- 각 데이터의 타입이 실행 시간에 결정되기 때문에 위 작업들이 실행할 때 수행되어서
라고 정리할 수 있다.
이해한 만큼만 설명했기 때문에 틀린 내용이 있을 수 있다.
참고
