
QuerySet
- Django ORM에서 제공하는 데이터 타입
- 데이터베이스에서 전달받은 객체 목록
구조는 list와 같지만, 파이썬의 기본 자료구조가 아니기 때문에 파이썬 파일에서 읽고 쓰기 위해서는 자료형 변환을 해줘야 한다.
QuerySets evaluate
QuerySets은 평가되기 전까지 데이터베이스 활동이 일어나지 않는다.
📍QuerySets 순회
QuerySets은 iterable객체이며, 순회하는 순간 데이터베이스에 Query를 실행해 QuerySets에 담긴 레코드를 불러옴
for loop
#Drink 에 있는 모든 korean_name 출력
>>>for e in Drink.objects.all():
... print(e.korean_name)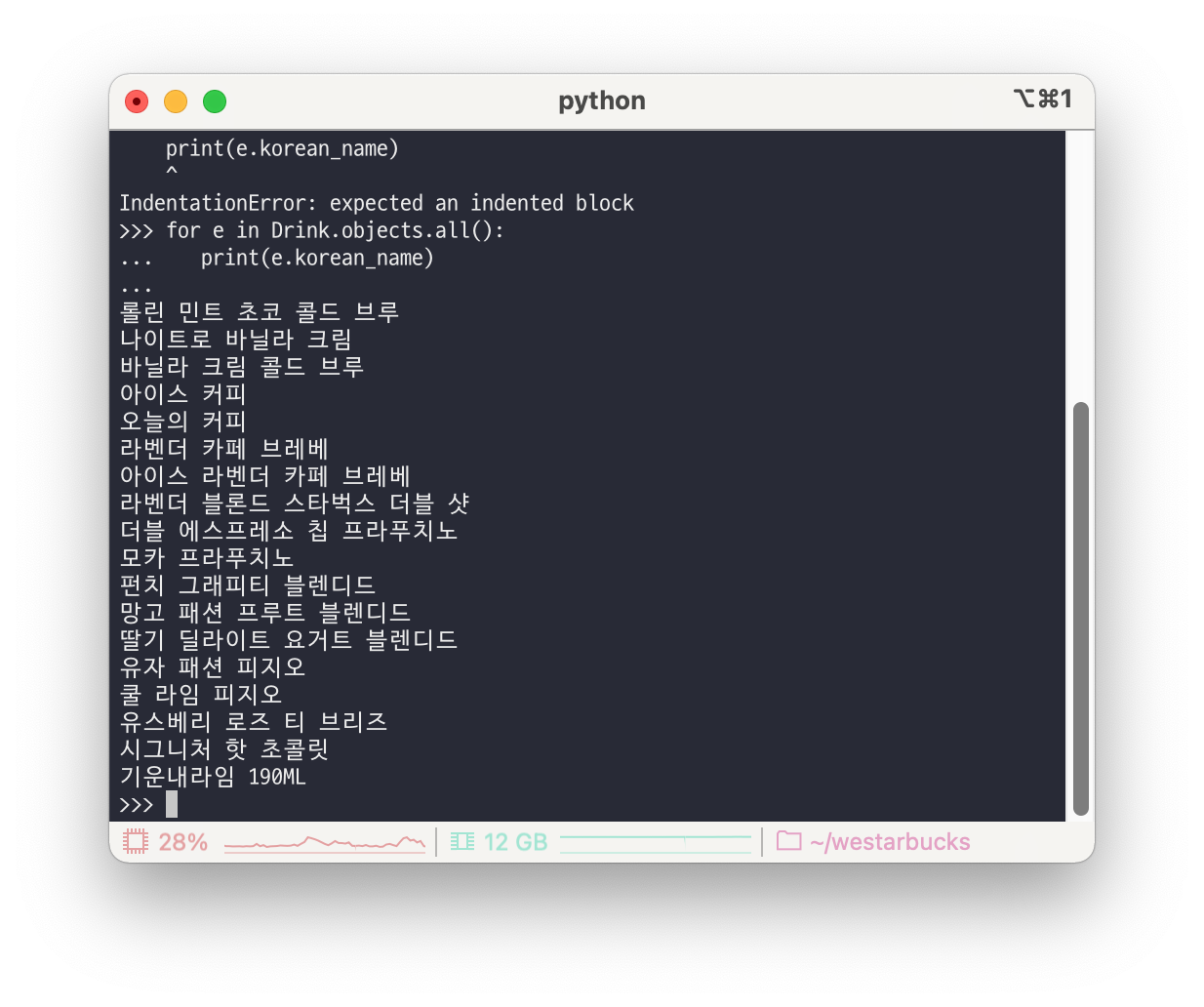
데이터 출력이 아닌 존재만 확인하면 되는경우에는 exists()를 사용하자
exists()
>>>Drink_set = Drink.objects.filter(category_id=2)
>>> if Drink_set.exists():
... print(True)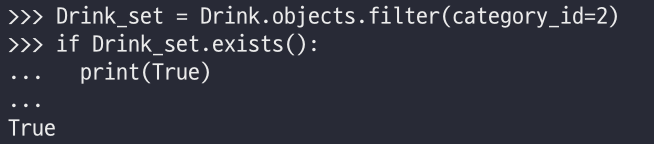
📍QuerySets 슬라이싱
>>>Drink.objects.all()[4:8]
# <QuerySet [
<Drink: Drink object (5)>,
<Drink: Drink object (6)>,
<Drink: Drink object (7)>,
<Drink: Drink object (8)>
]>
QuerySetnew 를 반환하는 메소드
ex) QuerySet|[<Category:Category objects(1)>...
Django는 QuerySet반환된 결과 유형 QuerySet이나 SQL 쿼리가 실행되는 방식을 수정하는 다양한 구체화 방법을 제공
- filter()
filter(**kwargs): 주어진 매개변수와 일치 하는 객체 반환
>>>Drink.objects.filter(category_id=3)

- exclude()
exclude(**kwargs): 주어진 매개변수와 일치하지 않는 객체 반환
>>>Drink.objects.exclude(category_id=3)
👉 category_id=3인 객체는 id 6~8 까지이기 때문에 해당부분은 제외하고 출력된 것을 볼 수 있다.
>>>Drink.objects.exclude(category_id=3).exclude(korean_name='롤린 민트 초코 콜드 브루')
👉 category_id=3인 객체 id 6~8 과 korean_name='롤린 민트 초코 콜드 브루' 인 id 1이 함께 제외된 것을 볼 수 있다.
- annotate()
annotate(*args,**kwargs)
- 필드명 깔끔하게 만들기
Drink가 Category PK를 외래키로 받고 있을 때
Drink id=1 이 속해있는 Category id의 type을 출력하려면
category__type이렇게_2개를 써서 표현해야하고 출력 또한
category__type:'콜드브루'이런식 일 것이다.
하지만 annotate()를 쓰면 필드명을type으로 출력할 수 있다.
예제)
>>> e=Drink.objects.values('korean_name','category__type')
>>> print(e)
'''
<QuerySet [{'korean_name': '롤린 민트 초코 콜드 브루', 'category__type': '콜드브루'}, {'korean_name': '나이트로 바닐라 크림', 'category__type': '콜드브루'}, {'korean_name': '바닐라 크림 콜드 브루', 'category__type': '콜드브루'}, {'korean_name': '아이스 커피', 'category__type': '브루드 커피'}, {'korean_name': '오늘의 커피', 'category__type': '브루드 커피'}, ...
'''
#필드명이 korean_name 과 category__type 으로 출력
>>> from django.db.models import F
>>>e=Drink.objects.annotate(type=F('category__type')).values('korean_name','type')
>>> print(e)
'''
<QuerySet [{'korean_name': '롤린 민트 초코 콜드 브루', 'type': '콜드브루'}, {'korean_name': '나이트로 바닐라 크림', 'type': '콜드브루'}, {'korean_name': '바닐라 크림 콜드 브루', 'type': '콜드브루'}, {'korean_name': '아이스 커피', 'type': '브루드 커피'}, ...
'''
#필드명이 korean_name 과 type 으로 출력- 개수
>>>Drink.objects.values('category_id').annotate(count=Count('category_id'))
<QuerySet [
{'category_id': 1, 'count': 3},
{'category_id': 2, 'count': 2},
{'category_id': 3, 'count': 3},
{'category_id': 4, 'count': 2},
{'category_id': 5, 'count': 3},
{'category_id': 6, 'count': 2},
{'category_id': 7, 'count': 1},
{'category_id': 8, 'count': 1},
{'category_id': 9, 'count': 1}]>- order_by()
order_by( *필드 ): 오름차순 정렬
>>>Drink.objects.order_by('english_name')
#알파벳순으로 정렬
>>>Drink.objects.order_by('-english_name')
#알파벳순으로 역정렬
>>>Drink.objects.order_by('english_name','size_id')
#알파벳순으로 정렬 후 size_id 순으로 정렬(사이즈별로 알파벨순 정렬)- reverse()
>>>Drink.objects.order_by('-english_name').reverse()[:5]
#영어이름 역순으로 정렬 후 역정렬
'''
<QuerySet [
<Drink: Drink object (5)>,
<Drink: Drink object (15)>,
<Drink: Drink object (9)>,
<Drink: Drink object (4)>,
<Drink: Drink object (7)>]>
'''reverse()는 정의된 순서가 있는 경우에만 사용가능
순서가 정의되어있지 않은 경우 order_by()
order_by()는 조건만 걸어주면 그 순서대로 정렬이 되는 메소드.
reverse()는 역정렬을 해주는건데 이미 어떠한 정렬을 하고 있어야 역정렬이 가능
- distinct()
QuerySet 결과에서 중복 레코드(행, 오브젝트)를 제거 - values()
values( *필드 , **표현식 )
#filter()
>>> Drink.objects.filter(category_id=1)
'''
<QuerySet [
<Drink: Drink object (1)>,
<Drink: Drink object (2)>,
<Drink: Drink object (3)>
]>
'''
>>> Drink.objects.filter(category_id=1).values()
'''
<QuerySet [
{'id': 1,'korean_name': '롤린 민트 초코 콜드 브루','english_name': 'Rollin Mint Choco Cold Brew','description': '스타벅스의 콜드 브루와 은은한 민트 초코 베이스','category_id': 1},
{'id': 2, 'korean_name': '나이트로 바닐라 크림', 'english_name': 'Nitro Vanilla Cream', 'description': '부드러운 목넘김의 나이트로 커피와 바닐라 크림의 매력을 한번에 느껴보세요!', 'category_id': 1},
{'id': 3, 'korean_name': '바닐라 크림 콜드 브루', 'english_name': 'Vanilla Cream Cold Brew', 'description': '', 'category_id': 1}
]>
'''QuerySetnew 를 반환하지 않는 메소드
ex) <Category:Category objects(1)>,9,True..
- get()
get( **kwargs ): 지정된 조회 매개변수와 일치하는 객체를 반환
>>> Drink.objects.get(id=3)
#<Drink: Drink object (3)>🚫ERROR
1. 일치하는 객체가 없을 때
Model.DoesNotExist
2. 일치하는 객체가 2개 이상일 때
Model.MultipleObjectsReturned
- create()
create( **kwargs ): 한 번에 개체를 만들고 모두 저장
Menu.objects.create(name=음료)- get_or_create()
get_or_create( 기본값=없음 , **kwargs ): 조건에 맞는 데이터를 조회하고 해당 데이터가 없다면 새로 생성 후 생성된 모델 데이터를 반환
Drink.objects.get_or_create(korean_name='어쩌구',englilsh_name='저쩌구')- count()
일치하는 데이터베이스의 개체 수를 나타내는 정수를 반환
>>> Drink.objects.count()
#18-
iterator()
iterator( 청크 크기=2000 )
??? -
latest()
주어진 필드 기준으로 가장 최신의 모델 데이터를 반환 -
first()
- 쿼리셋의 가장 첫번째 모델 데이터를 반환
- 정렬하지 않은 쿼리셋이라면 pk를 기준으로 반환
- 데이터가 없다면 None
-
last()
- 연산된 쿼리셋의 가장 가지막 모델 데이터를 반환
- 데이터가 없다면 None
