
틈새시장 프로젝트에서 성능 분석을 위해 저장 프로시저로 약 5만 건의 테스트 데이터를 생성하고, 위치 기반 게시글 조회 쿼리의 성능을 분석했습니다.
해당 과정에서 기존 위치 기반 검색 API가 서비스의 주요 병목 구간으로 드러났습니다.
프로젝트 구조상 단순한 코드 리팩토링으로는 한계가 있었고,
결국 MySQL의 실행 계획과 인덱스 전략까지 파고들게 되었습니다.
1. 문제 상황: v0 하버사인과 Specification의 한계
초기 구현은 JpaSpecificationExecutor 기반이었으며,
다음과 같은 구조적 한계를 가지고 있었습니다.
1) 쿼리 분리로 인한 비효율
반경 조건, 검색 조건, 정렬 조건이 분리되며 쿼리 구조가 복잡해지고, 실행 계획 상 최적의 접근 경로를 사용하지 못함
2) N+1 문제
- 게시글 목록 조회 후 각 게시글의 대표 이미지를 개별 조회
- 데이터 증가 시 DB 부하가 빠르게 증가
3) 하버사인 기반 거리 계산의 Full Table Scan 문제
- 하버사인 공식은 모든 행에 대해 거리 계산을 수행
- 인덱스를 활용할 수 없기 때문에 실행 계획 상 Full Table Scan이 발생
- 데이터가 증가할수록 거리 계산 비용이 선형적으로 증가

2. 1차 리팩토링: v1 Querydsl과 DTO 직접 조회
“개인적으로 실무에서 JpaSpecificationExcutor를 사용하는 것은 권장하지 않습니다.
JpaSpecification 자체가 결국 JPA가 제공하는 Criteria로 이루어지는데, JPA의 Criteria는 조금만 복잡해져도, 실무에서 사용이 정말 어려워 집니다. JPA를 잘 사용하는 저도 한참을 들여다 봐야 코드가 읽히더라구요.
그래서 제가 사용하는 모든 프로젝트에서는 JPA Criteria는 사용을 금지합니다. 대신에 Querydsl을 적극 활용하도록 합니다.”
개선방법
기존 코드가 쓸데없는 중복 조회가 너무 많이 일어나고 있어서 이를 수정하고, 이전에 김영한 강사님의 답변을 참고하여 specification을 지양하고 querydsl을 적용하였으며, dto로 한 번에 조회해오는 방식으로 리팩토링하였습니다.
코드
@Override
public Page<BoardSearchSpatial> searchBoardsSpatial(BoardSearchDto requestDto, Point userLocation,
Pageable pageable) {
QImage minImage = new QImage("minImage");
NumberTemplate<Double> distanceExpr = Expressions.numberTemplate(Double.class,
"ST_Distance_Sphere({0}, {1})",
board.location, userLocation
);
JPAQuery<BoardSearchSpatial> query = queryFactory
.select(new QBoardResponseDto_BoardSearchSpatial(
board.id,
board.title,
board.itemTime,
board.itemPrice,
board.createDate,
board.chatCount,
board.ScrapCount,
distanceExpr,
board.address,
board.boardState,
image.storedFileName
))
.from(board)
.leftJoin(image).on(image.board.eq(board)
.and(image.id.eq(
JPAExpressions
.select(minImage.id.min())
.from(minImage)
.where(minImage.board.eq(board))
))
)
.where(
withKeyword(requestDto.getKeyword()),
withCategory(requestDto.getCategory()),
withBoardType(requestDto.getBoardType()),
withSpatialCondition(userLocation)
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize());
for (Sort.Order o : pageable.getSort()) {
PathBuilder pathBuilder = new PathBuilder(board.getType(), board.getMetadata());
query.orderBy(
new OrderSpecifier(o.isAscending() ? Order.ASC : Order.DESC, pathBuilder.get(o.getProperty())));
}
List<BoardSearchSpatial> content = query.fetch();
JPAQuery<Long> countQuery = queryFactory
.select(board.count())
.from(board)
.where(
withKeyword(requestDto.getKeyword()),
withCategory(requestDto.getCategory()),
withBoardType(requestDto.getBoardType()),
withSpatialCondition(userLocation)
);
return PageableExecutionUtils.getPage(content, pageable, countQuery::fetchOne);
}결과
- 쿼리 수: 다수 → 단일 쿼리
- 응답 시간: 약 160ms → 130ms
3. 2차 리팩토링: v2 공간 인덱스(Spatial Index) 적용
성능 개선의 핵심을 다음으로 정의했습니다.
얼마나 적은 행을 탐색하느냐
이를 위해 POINT 타입 컬럼에 Spatial Index를 적용하고,
반경 조건을 공간 함수 기반으로 변경했습니다.
ST_Contains(
ST_Buffer(:userPoint, 0.1),
board.location
)문제 발생
좌표 정보가 없는 게시글도 함께 조회해야 했기 때문에,
다음과 같은 조건을 추가했습니다.
longitude = 0.0 AND latitude = 90.0
OR spatialCondition결과
- Spatial Index 미사용
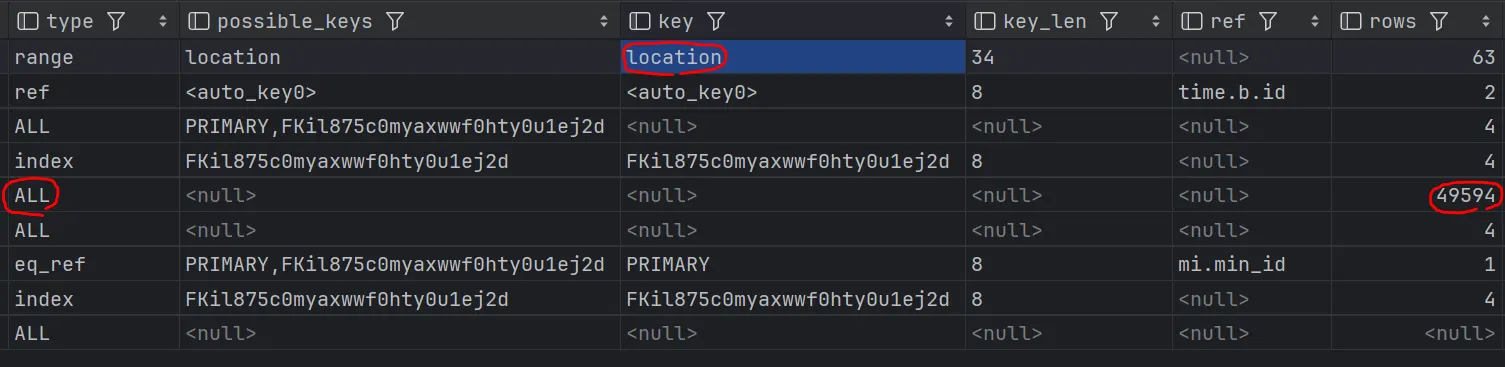
- 실행 계획 상 Full Table Scan 지속
원인 분석
MySQL 옵티마이저는 OR 조건이 포함된 경우,
공간 인덱스를 포함한 인덱스 사용을 포기하고 전체 테이블 스캔을 선택하는 경향이 있었습니다.
즉, Spatial Index 자체의 문제가 아니라,
쿼리 구조상 옵티마이저가 인덱스를 선택할 수 없는 상태였습니다.
4. 3차 리팩토링: Native Query와 UNION ALL의 도입
OR 조건을 제거하기 위해 쿼리를 두 개로 분리했습니다.
- 공간 조건을 사용하는 쿼리
- 좌표가 없는 데이터를 조회하는 쿼리
→ UNION ALL로 병합
JPQL은 UNION을 지원하지 않기 때문에 Native Query를 사용했습니다.
결과
- 응답 시간: 약 180ms
- 기존보다 성능 악화
원인
- 상단 쿼리는 Spatial Index 사용
하단 쿼리는 여전히 Full Table Scan
원인은 두 번째 쿼리의 Full Scan이었습니다.
5. 4차 리팩토링: 복합 인덱스 전략 적용
직접 StackOverflow에 질문글을 작성하였습니다.
https://stackoverflow.com/questions/79590075/how-to-apply-spatial-index-in-my-situation-without-using-or-and-union-all
StackOverflow의 조언과 인덱스 심화 학습을 통해, 각 쿼리가 최적의 인덱스를 탈 수 있도록 전략을 수정했습니다.인덱스 재설계공간 검색뿐만 아니라, board_type 필터링과 좌표 없는 데이터 검색을 위해 복합 인덱스를 생성했습니다.
-- 상단 쿼리(공간 검색)용 인덱스
CREATE INDEX idx_spatial_filter ON board (location, board_type);
-- 하단 쿼리(좌표 미지정 데이터)용 인덱스
CREATE INDEX idx_non_spatial_filter ON board (board_type, longitude, latitude);결과
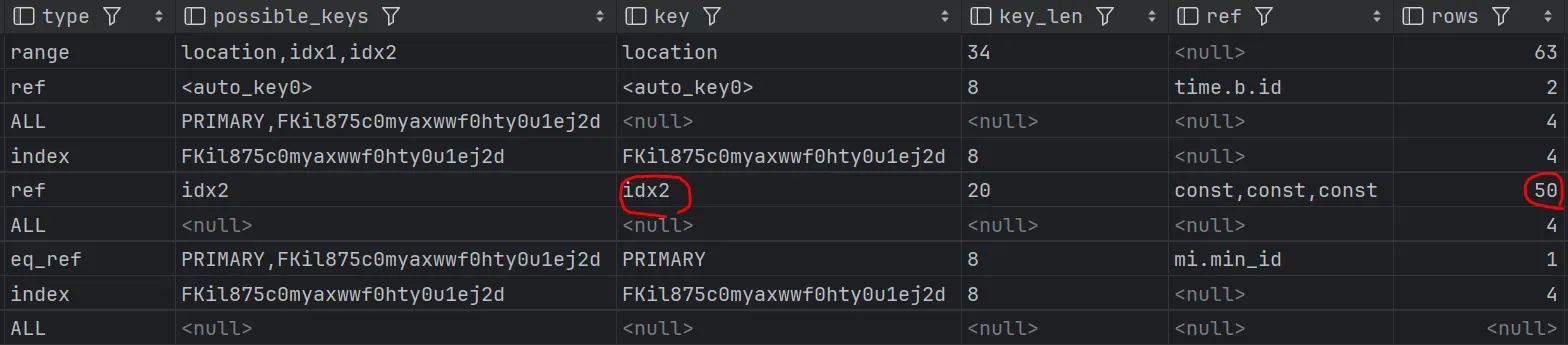
결과 비교
최종적으로 공간 인덱스와 복합 인덱스가 각각 적절히 작동하면서, 탐색 행(rows) 수가 비약적으로 줄어들었습니다.
- Rows 수: 5만 건 전체 탐색 → 필요한 수십 건만 정밀 탐색.
- 응답 속도: 초기 160ms에서 78ms까지 단축 (약 2배 개선).
| 단계 | 접근 방식 | 응답 시간 | 특징 |
|---|---|---|---|
| v0 | Specification | 160ms | 다수 쿼리, N+1 |
| v1 | QueryDSL | 130ms | 쿼리 수 감소, Full Scan |
| v2 | Spatial Index | - | OR 조건으로 인덱스 미사용 |
| v2-2 | UNION ALL | 180ms | 하단 쿼리 Full Scan |
| Final | 복합 인덱스 전략 | 78ms | rows 감소 |
인덱스 적용에 대한 고민
인덱스는 조회 성능을 크게 향상시키는 반면,
INSERT·UPDATE·DELETE 시 추가적인 유지 비용이 발생한다는 트레이드오프가 존재합니다.
하지만 본 프로젝트는
- 위치 기반 조회가 핵심 기능이며
- 조회 비중이 압도적으로 높고
- 인덱스 대상 컬럼은 변경 가능성이 낮은 구조
라는 특성을 가지고 있어,
읽기 성능 개선이 더 큰 이점이라고 판단했습니다.
