알고리즘을 구현하며 입/출력 최적화로 많은 시간을 줄일 수 있다.
표준 입출력과 표준 입출력 대상 설정 방법은 아래와 같다.
- 입력 : System.in / System.setIn()
- 출력 : System.out / System.setOut()
대표적인 입력 클래스는 Scanner가 있다. Scanner의 주요 메서드는 아래와 같다.
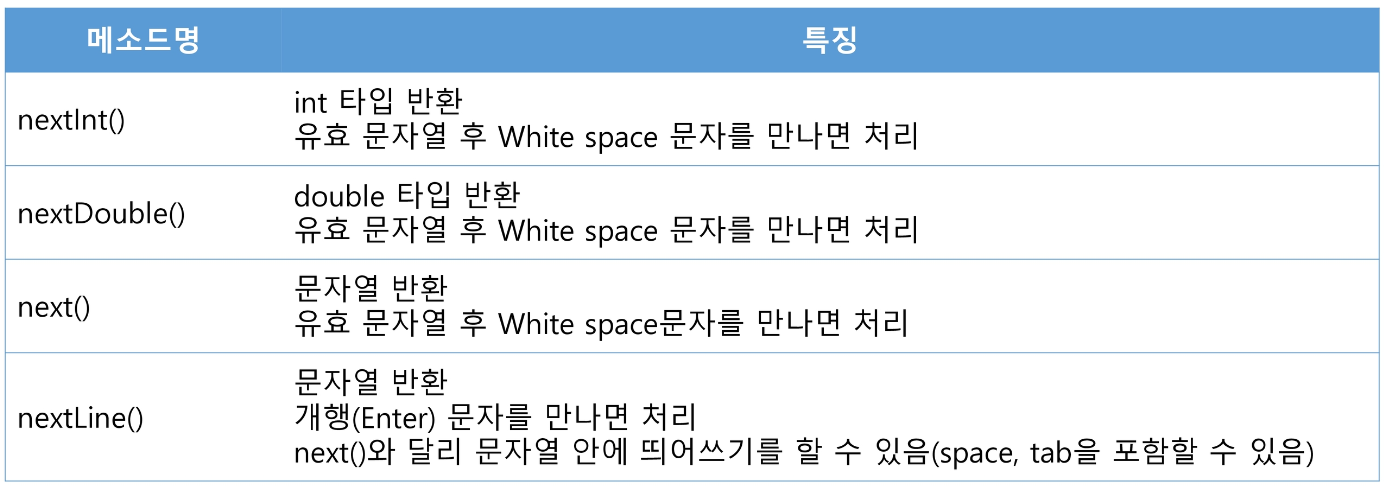
nextInt(), nextDouble(), nextLine()과 nextLine()에는 차이점이 있다.
앞의 세 함수는 구분자 직전까지 읽고, nextLine()은 구분자까지 읽는다는 점이다.
따라서 앞의 세 함수와 nextLine()을 섞어 사용할 때는 주의가 필요하다.
Scanner의 사용 예시는 아래와 같다.
public class IO1_ScannerTest {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.print("기수? : ");
System.out.println("==> 아임 : "+sc.nextInt());
System.out.print("하고 싶은 말 한마디 ? : ");
System.out.print("==> 한마디 :"+sc.next()+"!");
sc.close();
}
}Scanner는 대량의 데이터에 비효율적이라는 단점이 있다. 따라서 Buffered 계열을 사용해 이 단점을 극복한다.
public class IO2_BufferedReaderTest {
public static void main(String[] args) throws IOException {
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(in.readLine(), " ");
int i = Integer.parseInt(st.nextToken());
int j = Integer.parseInt(st.nextToken());
System.out.println(i+"//"+j);
}
}출력 클래스의 예시는 StringBuilder가 있다.
해당 클래스는 문자열을 조작할 때마다 메모리에 새로이 할당되는 문제를 막아준다.
아래는 StringBuilder의 예시를 보여준다.
public class IO4_StringBuilderOutputTest {
static String path = ".\\output.txt";
public static void main(String[] args) throws IOException {
int TC = 10;
FileWriter out = new FileWriter(path);
StringBuilder sb = new StringBuilder(); // Builder에 출력 내용 모음
long start = System.nanoTime();
// out.write(TC+"\n");
sb.append(TC+"\n");
Random r = new Random();
for (int tc = 0; tc < TC; tc++) {
int N = 1000;
// out.write(N+"\n");
sb.append(TC+"\n");
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
// out.write(r.nextInt(10)+" ");
sb.append(TC+"\n");
}
// out.write("\n");
sb.append(TC+"\n");
}
}
out.flush();
long end = System.nanoTime();
System.out.println((end-start)/1_000_000_000.0+"s!");
out.close();
}
FileWriter를 쓸 때보다 StringBuilder를 쓴 것이 시간이 더 빠르다.
알고리즘 성능은 지표로 측정될 수 있다.
좋은 알고리즘을 보여주는 지표는 아래와 같다.
- 정확성 : 얼마나 정확하게 동작하는가?
- 작업량 : 얼마나 적은 연산으로 원하는 결과를 얻어내는가?
- 메모리 사용량 : 얼마나 적은 메모리를 사용하는가?
- 단순성 : 얼마나 단순한가?
- 최적성 : 더 이상 개선할 여지없이 최적화되었는가?
시간 복잡도를 확인할 수 있는 수적 지표는 아래와 같다.
- 빅 오메가 표기법 - 최선의 경우
- 빅 오 표기법 - 최악의 경우
- 빅 세타 표기법 - 평균의 경우
그 중, 알고리즘을 짤 때는 주로 빅 오 표기법을 사용한다.
※ Java는 1억연산을 거의 1초로 본다.
알고리즘을 구현하며 재귀를 활용할 수 있다.
자신을 정의하는데 그 내용 안에 다시 자신을 포함하는 형태의 메서드를 재귀라고 한다.
재귀 함수는 재귀가 파생되는 유도 부분, 끝나는 기저 부분을 잘 구분해야 한다.
아래는 1부터 10까지의 합을 구하는 문제를 재귀함수로 푸는 방법이다.
static int m2(int i) { // 재귀호출되면서 매번 바뀌어야 하는 값을 매개변수로 관리
if (i == 11) { // 고정된 값은 관리하지 말기 (11), 기저 부분
return 0; // 기저 부분
}
// 실행해야 하는 소스 (유도 부분) - 여기선 없음
// 재귀 호출
return i + m2(i+1);
}public static void main(String[] args) {
// 1부터 10(N)까지의 합을 구하여라.
// int sum = 0;
// for (int i = 1; i < 11; i++) {
// sum += i;
// }
// System.out.println("1부터 10의 합 : " + sum);
System.out.println("1부터 10의 합 : " + m2(1));
}사실 위 경우에는 재귀가 메모리를 더 사용한다. 그러면 재귀는 왜 사용하는 것일까?
아래는 2진수 자릿수 3자리의 모든 문자열을 출력하는 경우이다.
static int radix = 2;
static void m6(String str, int size) {
if (size == 0) { // 기저 부분
System.out.print(str + " "); // 유도 부분
return;
}
// 재귀 호출
for (int i = 0; i < radix; i++) {
m6(str + Integer.toString(i), size - 1);
}
}public static void main(String[] args) {
// 2진수 자리수 3자리의 모든 문자열을 다 구하여 출력하라.
// m6("", 3);
}이때 반복문으로 해당 문제를 푼다면
진수나 자릿수가 바뀌면 거기에 대비하는 모든 반복문 코드를 작성해야 할 것이다.
하지만 재귀로 풀었기 때문에 size, radix 값만 바뀌면 구현이 가능하다.
즉, 반복을 돌아야 하는 값이 고정되지 않고 바뀔 때 재귀는 유용하게 사용 가능하다.
