알고리즘에서 정렬할 때 카운팅 정렬을 활용할 수 있다.
카운팅 정렬의 정의는 아래와 같다.
항목들의 순서를 결정하기 위해 집합에 각 항목이 몇 개씩 있는지 세는 작업을 하여
시간 복잡도 O(리스트 길이 + 정수의 최대값)에 정렬하는 효율적인 정렬
카운팅 정렬의 제한 사항은 아래와 같다.
- 정수나 정수로 표현할 수 있는 자료에만 적용할 수 있다.
- 집합 내의 가장 큰 정수를 알아야 한다.
{0, 4, 1, 3, 1, 2, 4, 1}을 카운팅 정렬해보자. 그 과정은 아래와 같다.
1번 과정
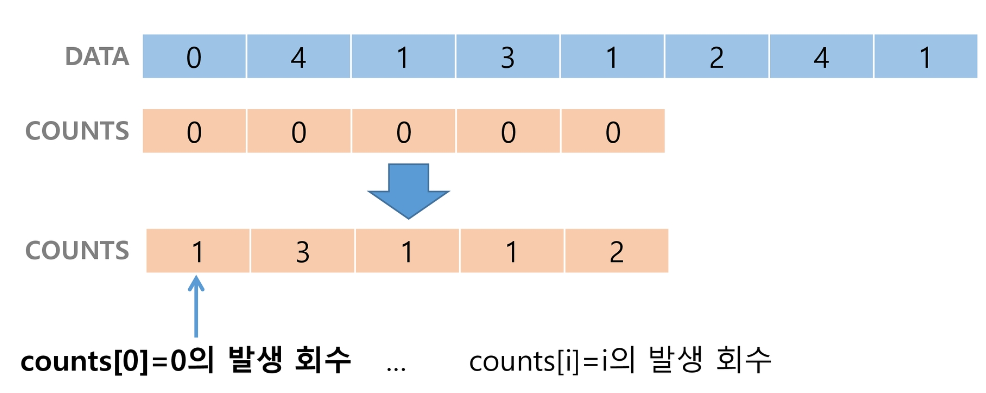
Data에서 각 항목들의 발생 횟수를 세어 Counts 배열에 저장한다.
2번 과정
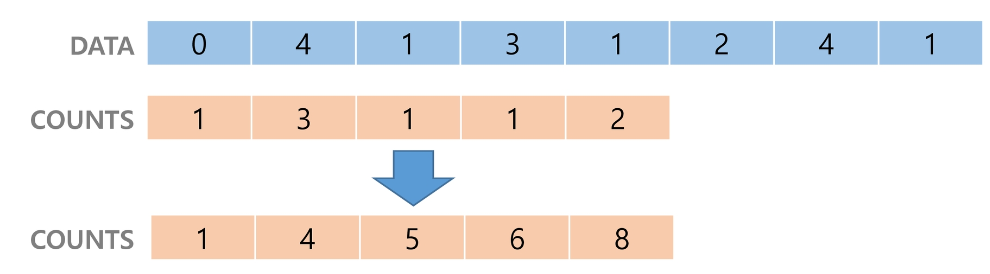
Counts의 원소 바로 앞 원소의 값을 원래 원소 값에 배열의 앞에서부터 더해준다.
3번 과정
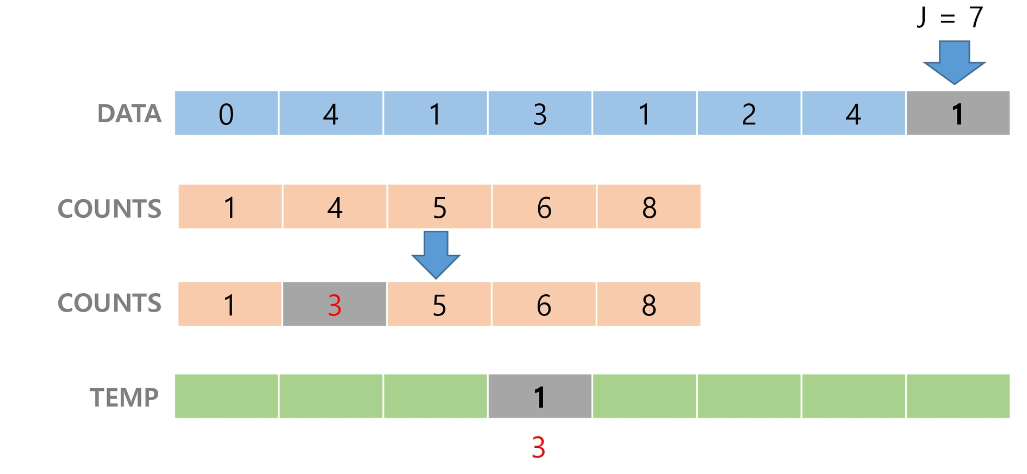
Data의 끝에서부터 Data의 값을 접근한다.
이 때, Data의 값을 인덱스로 Counts의 값을 1 줄여준다.
그리고 줄어든 Counts의 값을 인덱스로 Temp 배열에 Data의 값을 저장한다.
4번 과정
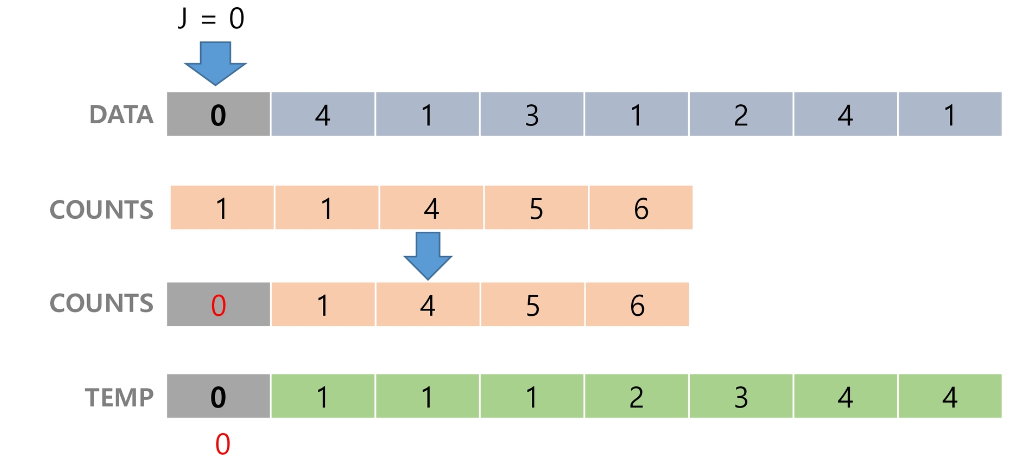
Data를 모두 접근할 때까지 3번 과정을 반복한다.
알고리즘에서 정렬할 때 선택 정렬을 활용할 수 있다.
선택 정렬의 정의는 아래와 같다.
가장 작은 값의 원소부터 차례대로 선택하여 위치를 교환하는 방식으로
시간 복잡도 O(N^2)에 정렬하는 정렬
선택 정렬의 정렬 과정은 아래와 같다.
1번 과정

주어진 리스트 중에서 최소값을 찾는다.
2번 과정

그 값을 리스트의 맨 앞에 위치한 값과 교환한다.
3번 과정
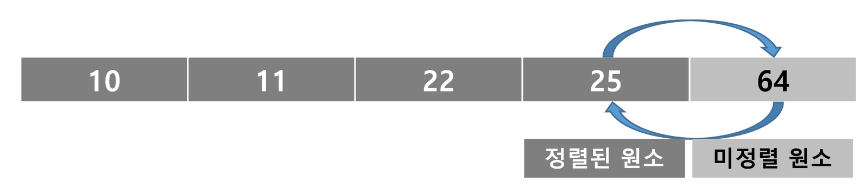
리스트의 끝에 도달하기 바로 전까지 1, 2번 과정을 반복한다.
알고리즘에서 정렬할 때 퀵 정렬을 활용할 수 있다.
퀵 정렬의 정의는 아래와 같다.
특정 값을 기준으로 작은 것은 왼쪽으로 큰 것은 오른쪽으로 위치하는 작업을 반복하여
시간 복잡도 O(Nlog(N))에 정렬하는 정렬
퀵 정렬의 정렬 과정은 아래와 같다.
1번 과정
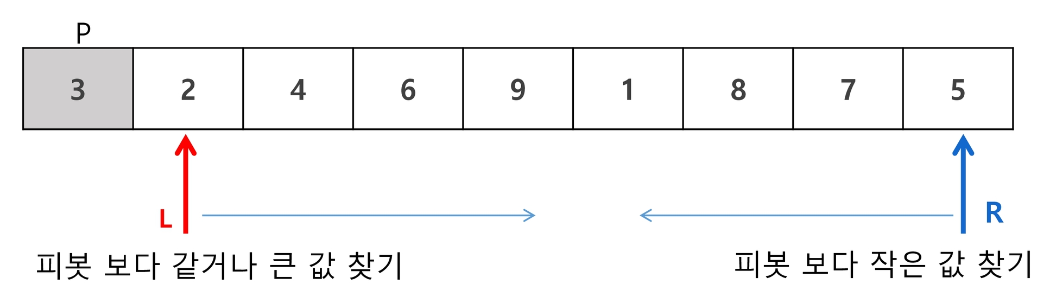
임의의 기준 값을 잡는다. 여기선 가장 왼쪽 값을 기준 값으로 잡았다.
2번 과정
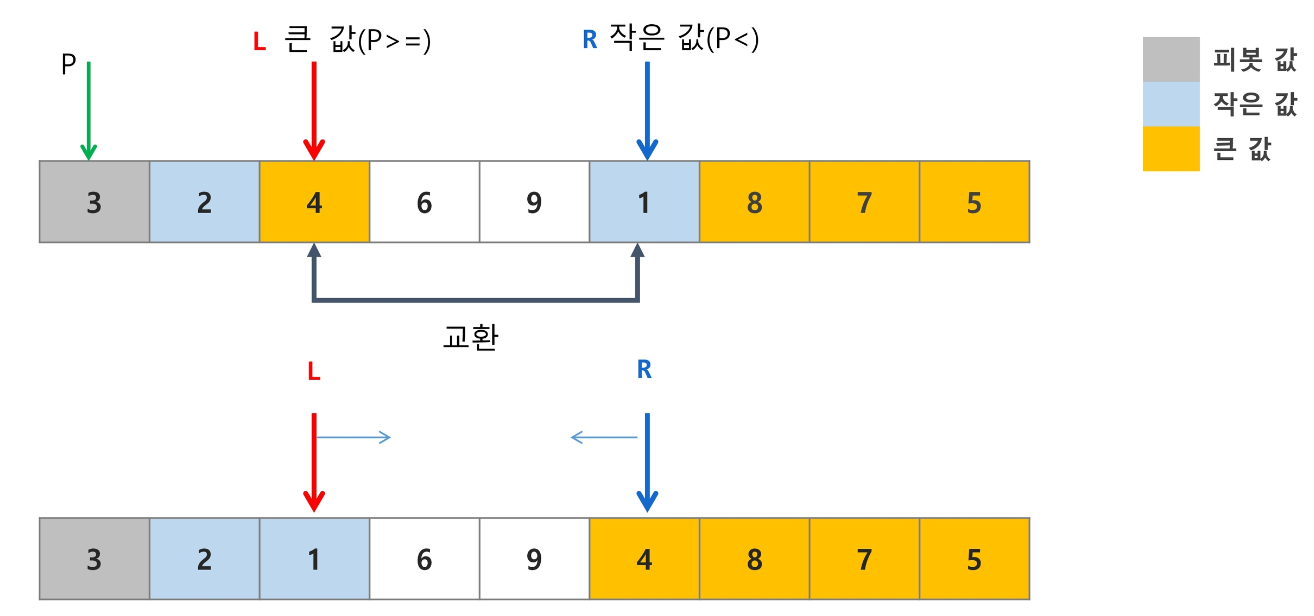
기준 값을 제외한 가장 왼쪽부터 기준 값보다 더 크거나 같을 때까지 인덱스를 이동한다.
또한 가장 오른쪽부터 기준 값보다 작을 때까지 인덱스를 이동한다.
위의 두 가지 조건을 모두 만족하면 두 값을 교환한다.
3번 과정

2번 과정을 반복하다가 왼쪽 포인터가 오른쪽 포인터보다 커지면
기준 값과 오른쪽 포인터 값을 교환한다.
4번 과정
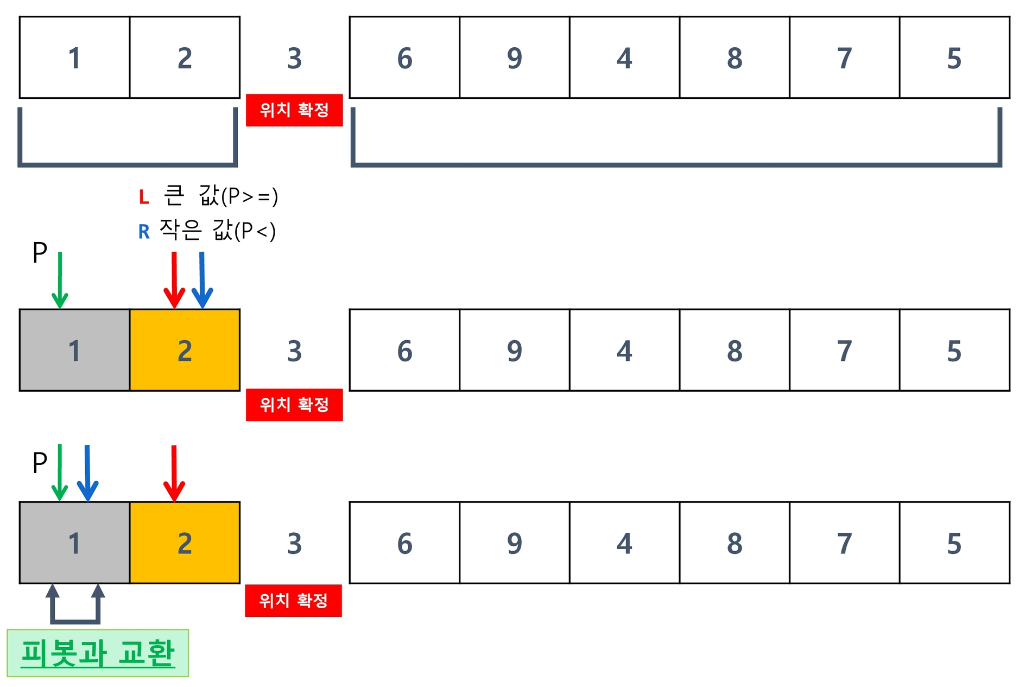
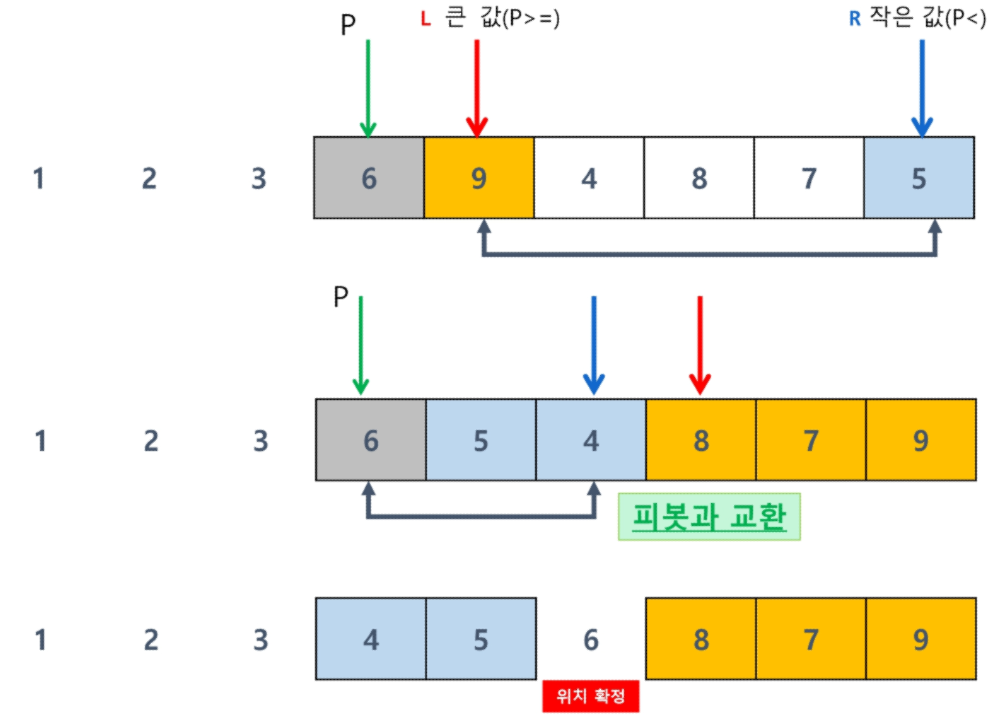
배열의 모든 요소가 확정될 때까지 1, 2, 3번 과정을 반복한다.
