
✅그래프 순회 알고리즘 : 하나의 정점으로부터 시작하여 차례대로 모든 정점을 한 번씩 방문하는 것
깊이 우선 탐색(Depth Sirst Search, DFS)
깊은 부분을 우선적으로 탐색하는 알고리즘
실행 과정
-
첫 정점을 방문한다.
-
인접한 정점 중 아직 방문하지 않은 정점을 방문한다. 이때 한 길로 쭉 파고 들어간다.
-
더 이상 들어갈 길이 없으면(인접한 모든 정점에 이미 방문했으면), 방문하지 않은 인접한 정점을 찾을 때까지 들어온 길을 돌아간다.
-
위 과정을 반복한다.
구현
1. 순환 호출 이용
재귀함수를 필요로 함. 공부 후 내용 추가
import java.io.*;
import java.util.*;
/* 인접 리스트를 이용한 방향성 있는 그래프 클래스 */
class Graph {
private int V; // 노드의 개수
private LinkedList<Integer> adj[]; // 인접 리스트
/** 생성자 */
Graph(int v) {
V = v;
adj = new LinkedList[v];
for (int i=0; i<v; ++i) // 인접 리스트 초기화
adj[i] = new LinkedList();
}
/** 노드를 연결 v->w */
void addEdge(int v, int w) { adj[v].add(w); }
/** DFS에 의해 사용되는 함수 */
void DFSUtil(int v, boolean visited[]) {
// 현재 노드를 방문한 것으로 표시하고 값을 출력
visited[v] = true;
System.out.print(v + " ");
// 방문한 노드와 인접한 모든 노드를 가져온다.
Iterator<Integer> i = adj[v].listIterator();
while (i.hasNext()) {
int n = i.next();
// 방문하지 않은 노드면 해당 노드를 시작 노드로 다시 DFSUtil 호출
if (!visited[n])
DFSUtil(n, visited); // 순환 호출
}
}
/** 주어진 노드를 시작 노드로 DFS 탐색 */
void DFS(int v) {
// 노드의 방문 여부 판단 (초깃값: false)
boolean visited[] = new boolean[V];
// v를 시작 노드로 DFSUtil 순환 호출
DFSUtil(v, visited);
}
/** DFS 탐색 */
void DFS() {
// 노드의 방문 여부 판단 (초깃값: false)
boolean visited[] = new boolean[V];
// 비연결형 그래프의 경우, 모든 정점을 하나씩 방문
for (int i=0; i<V; ++i) {
if (visited[i] == false)
DFSUtil(i, visited);
}
}
}//n = 노드의 개수
public static void dfs(int target){
nodeSet[target][0] = true;
sb.append(target).append(' ');
for(int i=1; i<=n; i++){
if(!nodeSet[i][0] && !nodeSet[target][i]){
dfs(i);
}
}
}2. 스택 이용
//n = 노드의 개수, m = 간선의 개수, v = 시작 노드
public static void dfs(boolean[][] node){
Stack<Integer> st = new Stack<>();
node[v][0] = true;
st.push(v);
sb.append(v).append(' ');
while(!st.isEmpty()){
int target = st.peek();
for(int i=1; i<=n; i++){
node[0][0] = true;
if(!node[i][0]){
if(!node[target][i]){
node[i][0] = true;
st.push(i);
sb.append(i).append(' ');
break;
}
node[0][0] = false;
} else if(i==n){
if(node[0][0]) st.clear();
else st.pop();
}
}
}
}시간 복잡도
N = 정점(노드)의 수, E = 간선의 수
- 인접 리스트 : O(N+E)
- 인접 행렬 : O(N^2)
사용 사례
- 미로 탐색
- 그래프 사이클 찾기
- 전위 순회
너비 우선 탐색(Breadth First Search, BFS)
가까운 곳을 우선적으로 탐색하는 알고리즘
실행 과정
- 첫 정점을 방문한다.
- 아직 방문하지 않은 인접한 정점들을 방문한다.
- 방문한 정점에 대해 인접하면서 방문하지 않은 정점들을 차례대로 방문한다.
- 위 과정을 반복한다.
구현
0. 의사 코드(Pseudo code)
void search(Node root) {
Queue queue = new Queue();
root.marked = true; // (방문한 노드 체크)
queue.enqueue(root); // 1-1. 큐의 끝에 추가
// 3. 큐가 소진될 때까지 계속한다.
while (!queue.isEmpty()) {
Node r = queue.dequeue(); // 큐의 앞에서 노드 추출
visit(r); // 2-1. 큐에서 추출한 노드 방문
// 2-2. 큐에서 꺼낸 노드와 인접한 노드들을 모두 차례로 방문한다.
foreach (Node n in r.adjacent) {
if (n.marked == false) {
n.marked = true; // (방문한 노드 체크)
queue.enqueue(n); // 2-3. 큐의 끝에 추가
}
}
}
}1. 큐 이용
//n = 노드의 개수, v = 시작 노드
public static void bfs(boolean[][] node){
Queue<Integer> que = new LinkedList<>();
node[v][0] = true;
que.add(v);
sb.append(v).append(' ');
while(!que.isEmpty()){
int target = que.poll();
for(int i=1; i<=n; i++){
node[0][0] = true;
if(!node[i][0]){
if(!node[target][i]){
node[i][0] = true;
que.add(i);
sb.append(i).append(' ');
}
node[0][0] = false;
}
}
if(node[0][0]) que.clear();
}
}시간 복잡도
N = 정점(노드)의 수, E = 간선의 수
- 인접 리스트 : O(N+E)
- 인접 행렬 : O(N^2)
사용 사례
- 최단 경로 탐색
- 그래프 사이클 찾기
깊이 우선 탐색(DFS) VS 너비 우선 탐색(BFS)
깊이 우선 탐색의 특징
- 같은 레벨의 경로보다 더 깊은 레벨을 우선으로 탐색한다.
- 경로상의 노드들만 기억하면 되므로 차지하는 저장공간이 적다
- 재귀적으로 동작하며, 후입선출(LIFO) 구조이다.
너비 우선 탐색의 특징
- 목표 지점까지 최단 길이를 보장한다.
- 경로가 길수록 인접한 정점이 많이 생겨나므로(저장되므로) 저장 공간이 많이 필요하다.
- 선입선출(FIFO) 구조이다.
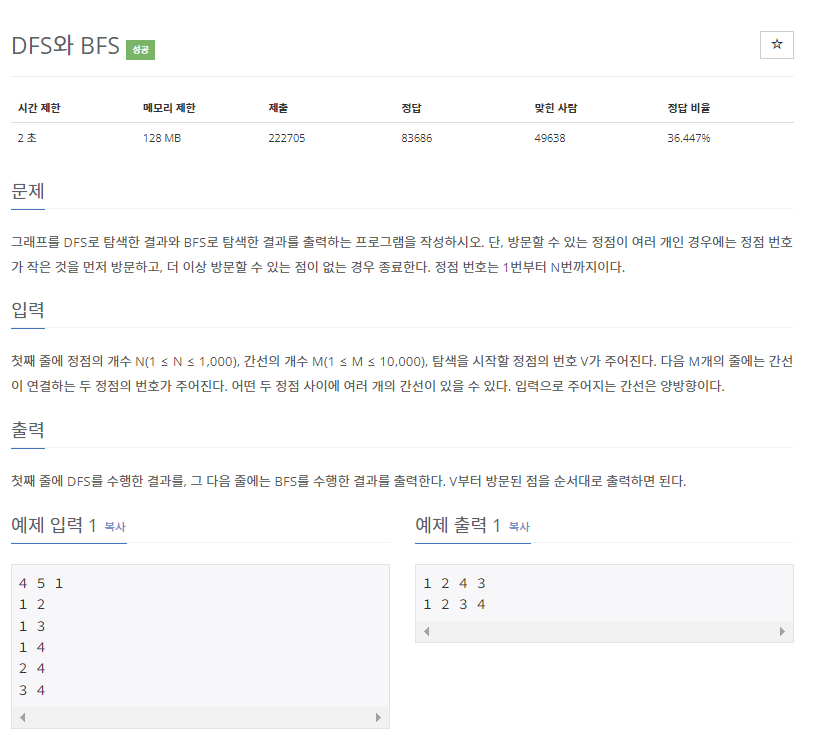
package Y2023.March.week2;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
public class q1260 {
static StringBuilder sb = new StringBuilder();
static int n, m, v;
static boolean[][] nodeSet;
public static void dfs(boolean[][] node){
Stack<Integer> st = new Stack<>();
node[v][0] = true;
st.push(v);
sb.append(v).append(' ');
while(!st.isEmpty()){
int target = st.peek();
for(int i=1; i<=n; i++){
node[0][0] = true;
if(!node[i][0]){
if(!node[target][i]){
node[i][0] = true;
st.push(i);
sb.append(i).append(' ');
break;
}
node[0][0] = false;
} else if(i==n){
if(node[0][0]) st.clear();
else st.pop();
}
}
}
}
public static void bfs(boolean[][] node){
Queue<Integer> que = new LinkedList<>();
node[v][0] = true;
que.add(v);
sb.append(v).append(' ');
while(!que.isEmpty()){
int target = que.poll();
for(int i=1; i<=n; i++){
node[0][0] = true;
if(!node[i][0]){
if(!node[target][i]){
node[i][0] = true;
que.add(i);
sb.append(i).append(' ');
}
node[0][0] = false;
}
}
if(node[0][0]) que.clear();
}
}
public static boolean[][] copyNodeSet(){
boolean[][] copy = new boolean[n+1][n+1];
for(int i=0; i<n+1; i++) {
for(int j=0; j<n+1; j++) {
copy[i][j] = nodeSet[i][j];
}
}
return copy;
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String[] NMV = br.readLine().split(" ");
n = Integer.parseInt(NMV[0]);
m = Integer.parseInt(NMV[1]);
v = Integer.parseInt(NMV[2]);
nodeSet = new boolean[n+1][n+1];
for(int i=0; i<n+1; i++){
Arrays.fill(nodeSet[i], true);
}
for(int i=0; i<m; i++){
String[] edge = br.readLine().split(" ");
int n1 = Integer.parseInt(edge[0]);
int n2 = Integer.parseInt(edge[1]);
nodeSet[n1][0] = false;
nodeSet[n2][0] = false;
nodeSet[n1][n2] = false;
nodeSet[n2][n1] = false;
}
dfs(copyNodeSet());
sb.append('\n');
bfs(copyNodeSet());
System.out.println(sb);
}
}
출처
- https://librewiki.net/wiki/%EC%8B%9C%EB%A6%AC%EC%A6%88:%EC%88%98%ED%95%99%EC%9D%B8%EB%93%AF_%EA%B3%BC%ED%95%99%EC%95%84%EB%8B%8C_%EA%B3%B5%ED%95%99%EA%B0%99%EC%9D%80_%EC%BB%B4%ED%93%A8%ED%84%B0%EA%B3%BC%ED%95%99/%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98_%EA%B8%B0%EC%B4%88
- https://velog.io/@falling_star3/2.-%EA%B9%8A%EC%9D%B4%EC%9A%B0%EC%84%A0%ED%83%90%EC%83%89DFS%EA%B3%BC-%EB%84%93%EC%9D%B4%EC%9A%B0%EC%84%A0%ED%83%90%EC%83%89BFShttps://gmlwjd9405.github.io/2018/08/14/algorithm-dfs.html
- https://gmlwjd9405.github.io/2018/08/15/algorithm-bfs.html
- https://kwin0825.tistory.com/112?category=1252233
- https://kwin0825.tistory.com/111

프론트엔드 공부합니다. 블로그 이전: https://jinijana.tistory.com