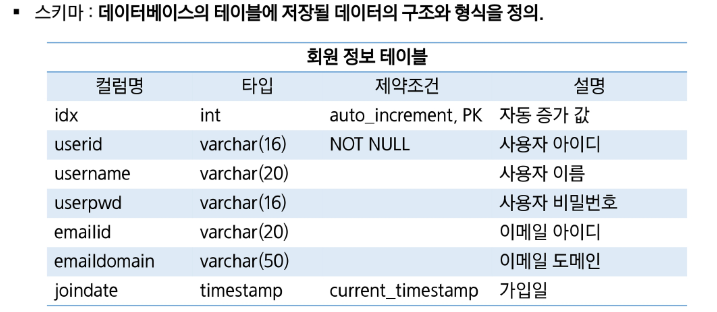
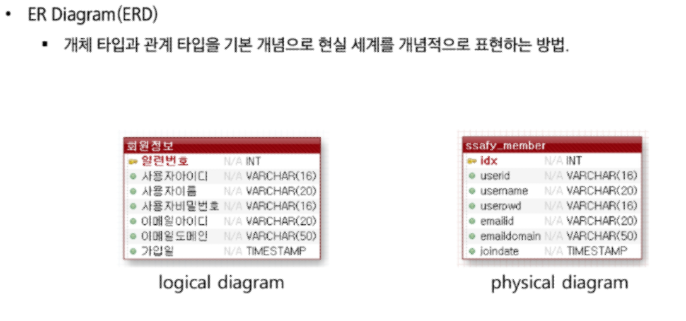
순서 : From - Where - Group by - Having - Select - Order by
SQL
- SQL 구문은 DCL, DDL, DML
- 데이타 제어어(DCL: Data Control Language) : grant, revoke
- 데이타 정의어(DDL : Data Definition Language): create, alter, drop, rename, truncate
- 데이타 조작어(DML : Data Manipulation Language): select, insert, update, delete
DML : 데이터베이스 테이블에서 새로운 행을 입력하고, 기존의 행을 변경하고 제거한다.
DDL : 테이블로부터 데이터 구조를 생성, 변경, 제거한다.
DCL : 데이터베이스와 그 구조에 대한 접근권한을 제공하거나 제거한다.
commit, rollback : DML명령문으로 수행한 변경을 관리한다.
DDL
- create가 주가 됨
- 개발자 입장에서는 drop,alter는 일단 xx
- create 만드는거 drop 날리는거 alter바꾸는거
- 데이터 정의어
- 데이터베이스 객체(table,view,index)의 구조를 정의
- 테이블 생성, 컬럼 추가, 타입변경, 제약조건 지정, 수정 등
- create : 데이터베이스 객체 생성
- alter : 기존에 존재하는 데이터베이스 객체를 수정
- drop : 데이터베이스 객체를 삭제
데이터베이스 생성
-
데이터베이스 생성
create database 데이터베이스명;
create database 데이터베이스명
default character set 값
collate 값; -
Character set은 각 문자가 컴퓨터에 저장될 때 어떠한 '코드'로 저장될지에 대한 규칙의 집합
-
Collation은 특정 문자 셋에 의해 데이터베이스에 저장된 값들을 비교검색하거나 정렬 등의 작업을 위해 문자열들을 서로 비교할때 사용하는 규칙들의 집합을 의미한다
show character set;
한글은 크게 조합형과 완성형

데이터베이스 변경
- 데이터베이스 변경
alter database 데이터베이스명
default character set 값 collate 값; - dbtest의 character set, collate 변경
alter database dbtest
default character set utf8mb4 collate utf8mb4_general_ci;
데이터베이스 삭제
-
데이터베이스 삭제
drop database 데이터베이스명;
-
이름이 'dbtest'인 데이터베이스 삭제
drop database dbtest; -
데이터베이스 사용
use 데이터베이스명;
-
이름이 ssafydb인 데이터베이스 사용
use ssafydb;
Data Type - 문자형
table 생성
- Data Type
- 이전 데이터 타입
Type : 숫자,문자,날짜,이진데이터타입 -> db에 영화저장?할수있을가? YES 저장 가능하지만 일반적으로 xxcreate table table_name(
column_name1 Type [optional|attribute],
column_name2 Type,
column_nameN Type
);
optional attributes : 제약조건
- 이전 데이터 타입
- 문자형 데이터 타입
CHAR, VARCHAR 가장 많이 사용
둘의 차이점은 고정이냐 가변이나 !
CHAR는 고정 길이를 갖는 문자열
VARCHAR는 가변 길이를 갖는 문자열
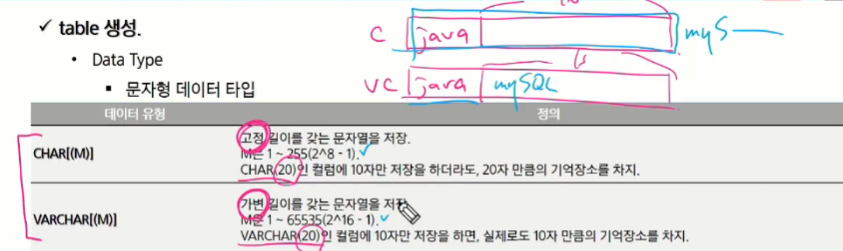
CHAR는 언제쓰는게 좋은가? 주민등록번호, 비밀번호 암호화했을때 최대길이 정해져있음..boolean
길이가 고정적으로 정해져있을 때
엄청 큰 것을 저장할 때는 TEXT, TEXT는 검색을 할 때 좀 느림
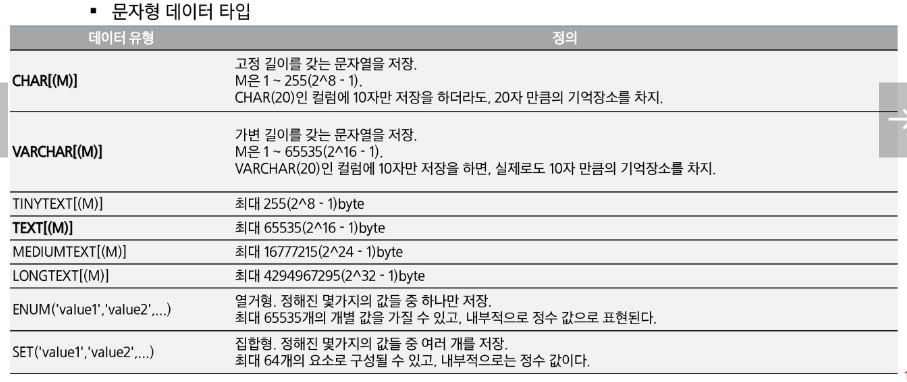
Data Type - 숫자형
- 숫자형 데이터 타입1
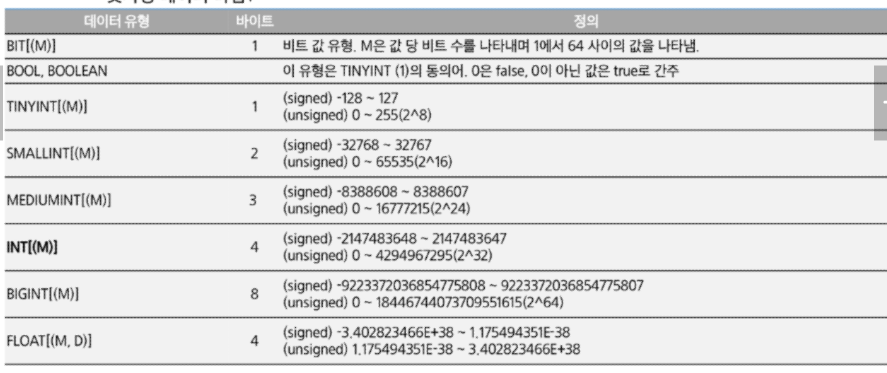
- 숫자형 데이터 타입2

Data Type - 날짜형
- 날짜형 데이터 타입
DATETIME은 문자열로 저장이 됨 (8byte) 1001-01-01 ~ 9999-12-31, now같은걸로 현재시간 저장가능..
TIMESTAMP 날짜에 해당하는 것을 숫자로 바꿔서 저장이 됨 (4byte) 타임존이 같이 저장
차이점 : 내가 현재 시간 9시에 저장하면 뉴욕에 있는 데이터를 처리해야할 때 서울의 시간이 저장됨 , 타임존을 바꿔서 타임스탬프 저장하면 뉴욕의 시간으로 저장됨

Data Type - 이진 데이터형
- 이진 데이터 타입
binary large object

- 제약조건
- NOT NULL : 각 행은 해당 열의 값을 포함해야하며 null값 허용되지 않음
- DEFAULT value : 기본값 설정
- AUTO INCREMENT : PK만들때 많이 사용
- PRIMARY KEY: 중복 안됨, 널도 안됨, row 구분
- UNIQUE : 중복 안됨, 널은 허용
- UNIQUE + NOT NULL : primary key
- FOREIGN KEY : 널 값 허용! 외래키는 널값이 허용 된다.. kim벌리..아직 부서가 결정 안됐던 친구..부서번호가 없어..
- DEFAULT : 널 대신 집어넣을값 설정할 수 있음

Create Table
table 생성
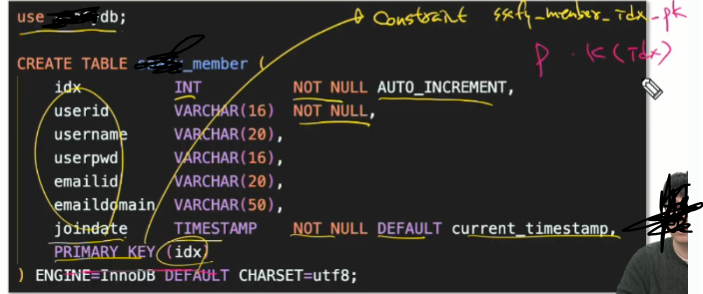
constraint ss_member_idx_px primary_key(idx);
제약조건을 만들건데 이런 이름을 가지고 프라이머리키 제약조건을 걸 것이다.
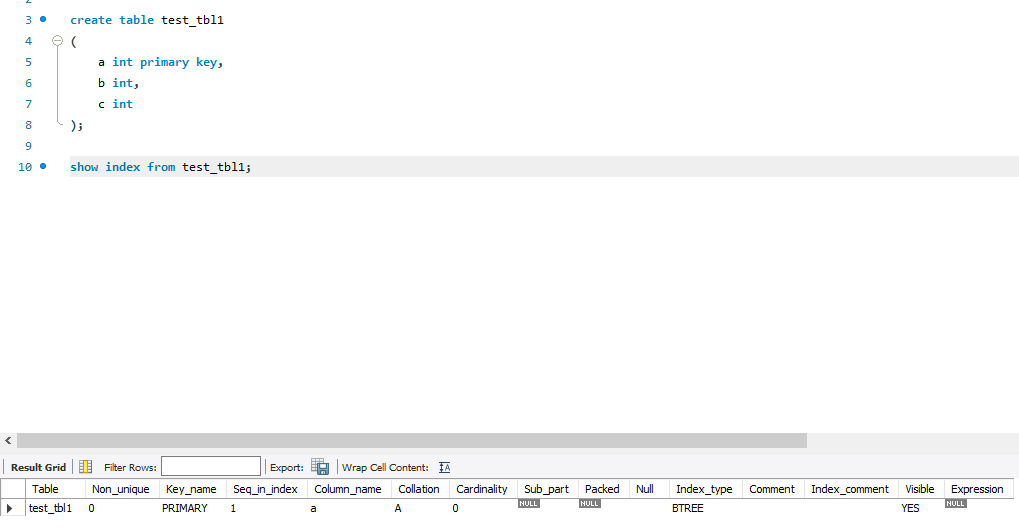
Index
Index
색인 .. 인덱스..머 찾아볼때 씁니다..

- 원하는 내용을 바로 찾을 수 있도록 지원
- 테이블의 데이터 조회 시 동작속도를 높여주는 자료구조
- 데이터의 위치를 빠르게 찾아주는 역할
- 컬럼의 값과 레코드가 저장된 주소를 키와 값의 쌍으로 인덱스를 만들어 둠
- MYI파일에 인덱스 저장 -> 물리적인 공간을 차지하는 단점
- ㄴ단점 : 물리적인 공간을 차지함
- 인덱스 빠르지만 남발 X
Index의 문제점
- 책의 모든 페이지에 나오는 단어를 찾아보기에 표시하게 되면 찾아보기의 분량이 엄청나게 많아져 오히려 본문보다 두꺼워지는 상황이 발생
- 필요없는 index를 만들면 데이터베이스가 차지하는 공간만 늘어나고, index를 이용하여 데이터를 찾는 것이 전체 테이블을 찾는 것 보다 느려짐
- 데이터베이스의 공간을 차지하므로 추가적인 공간 필요(DB크기의 10%정도의 추가 공간 필요)
- 처음 index를 생성하는데 많은 시간이 소요 (한번만해놓으면 다음부터는 빠르긴함)
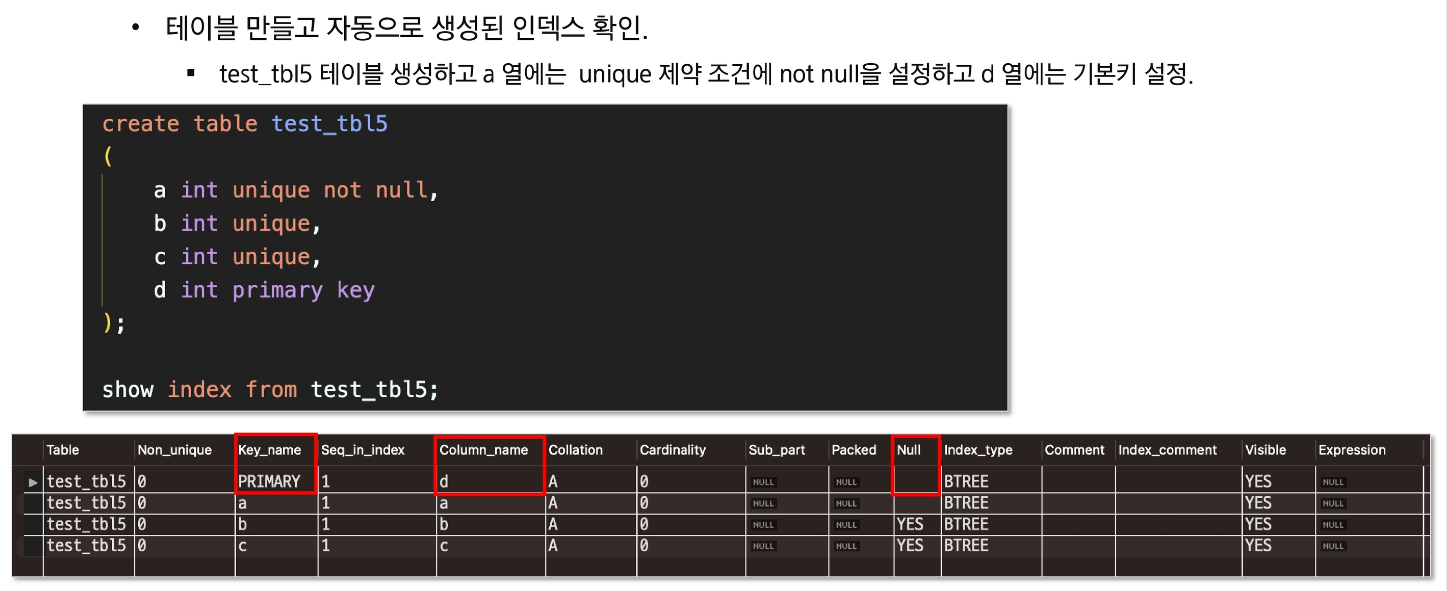
- PRIMARY KEY 자동으로 인덱스 생성
- 데이터의 변경작업 (insert,update,delete)이 자주 일어나는 경우 오히려 성능 저하가 일어날 수 있음
Index의 종류
-
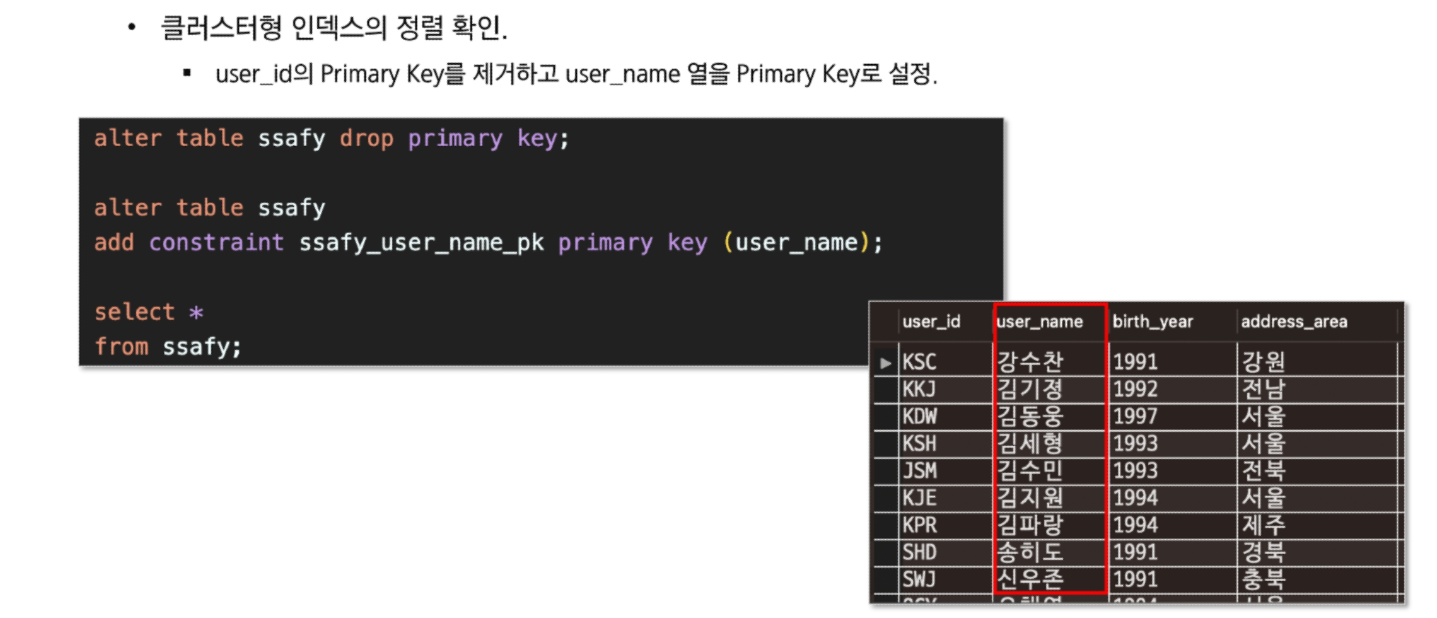
클러스터형 인덱스
-
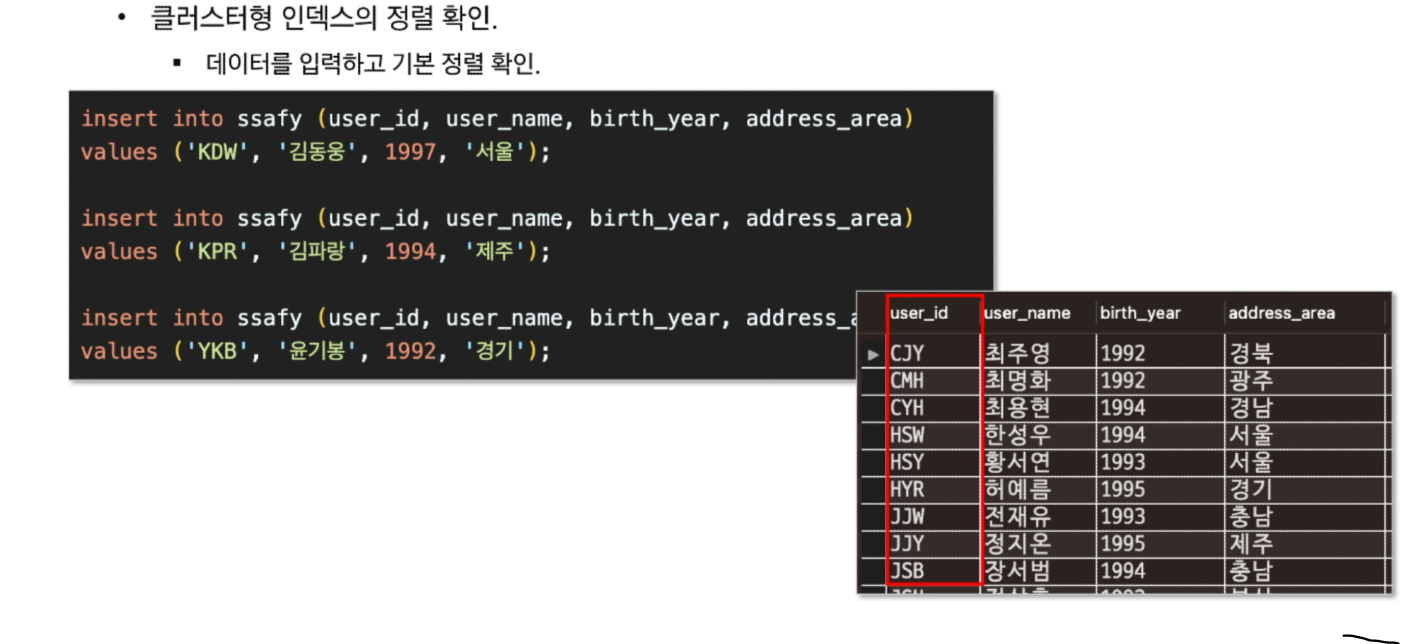
특정 나열된 데이터들을 일정 기준으로 정렬해 주는 인덱스(ex: 영어사전)
-
클러스터형 인덱스 생성 시 페이지 전체가 다시 정렬 >> 이미 대용량의 데이터가 입력된 상태라면 클러스터형 인덱스 생성시 심각한 부하가 발생
-
데이터 자체가 정렬돼서 저장되기때문에 (영어사전처럼..정렬돼서 인쇄됨) 클러스
-
새로운게 들어올때마다 뒤에꺼를 다 이동시켜야되기때문에 부하가 발생
-
집어넣을때마다 재정렬이 일어나야되니까
-
테이블당 하나만 생성 가능. 어느 열에서 클러스터형 인덱스를 생성하는지에 따라 시스템의 성능이 달라짐
-
보조 인덱스보다 검색 속도는 더 빠르다. 단 입력/수정/삭제는 더 느림
-
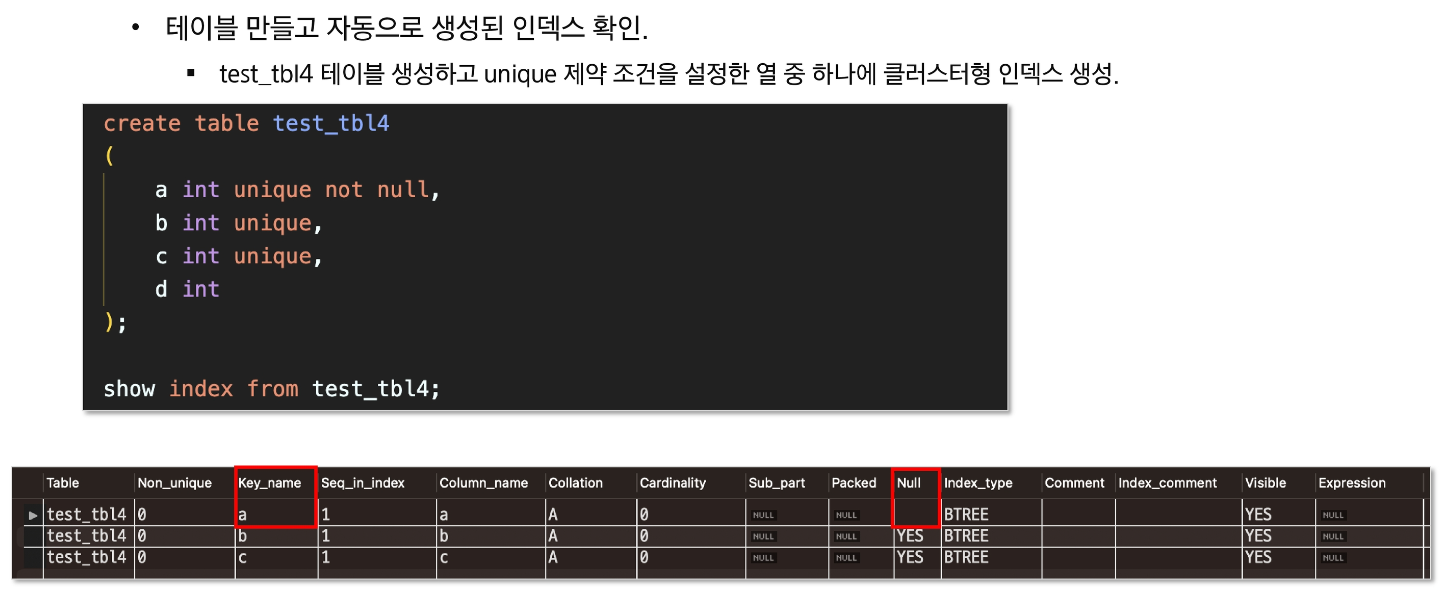
mysql의 경우 primary key가 있다면 primary key를 클러스터형 인덱스로,
없다면 unique하면서 not null인 컬럼을, 그것도 없으면 임의로 보이지 않는 컬럼을 만ㄷ르어서 클러스터형 인덱스로 지정
-
-
보조인덱스
- 보조 인덱스 생성시 데이터 "페이지 : B-Tree .. :비트리 인덱스 찾아보기"
- 자동정렬 되지 않음! 책 인덱스 생각하면됨..
- 주소값저장
- 성능부하가 적다는건 클러스터형에 비해 적다는거지 없다는게 아님- 개념적으로 후보키에만 부여가능한 index (후보키: 주민번호와 같이 각 데이터를 인식할 수 있는 최소한의 고유 식별 속성 집합) - **보조 인덱스 생성시 데이터 페이지는 그냥 둔 상태에서 별도의 페이지에 인덱스를 구성 (자동 정렬되지 않음 ex : 책의 인덱스 색인)** - **데이터가 위치하는 주소값 (RID)** - 클러스터형 인덱스보다 검색 속도는 느리지만 데이터의 입력/수정/삭제 시 성능 부하가 적음 - 보조 인덱스는 테이블 당 여러개 생성 가능(너무 많이 생성시 오히려 성능 저하)
Index 생성 전략
- 인덱스는 열단위에 생성
- where 절에서 사용되는 열에 생성
- where 절에 사용되는 열이라도 자주 사용해야 가치가 있음
- 데이터 중복도가 높은 열에는 인덱스를 만들어도 효과가 없음(중복도가 낮은 열에 생성)
- 외래키를 설정한 열에는 자동으로 외래키 인덱스가 생성됨
- 조인에 자주 사용되는 열에는 인덱스를 생성하는 것이 좋음
- 데이터 변경(삽입, 삭제, 수정) 작업이 얼마나 자주 일어나는지를 고려해야함
- 클러스터형 인덱스는 테이블당 하나만 생성할 수 있음
- 사용하지 않는 인덱스는 제거
자동생성
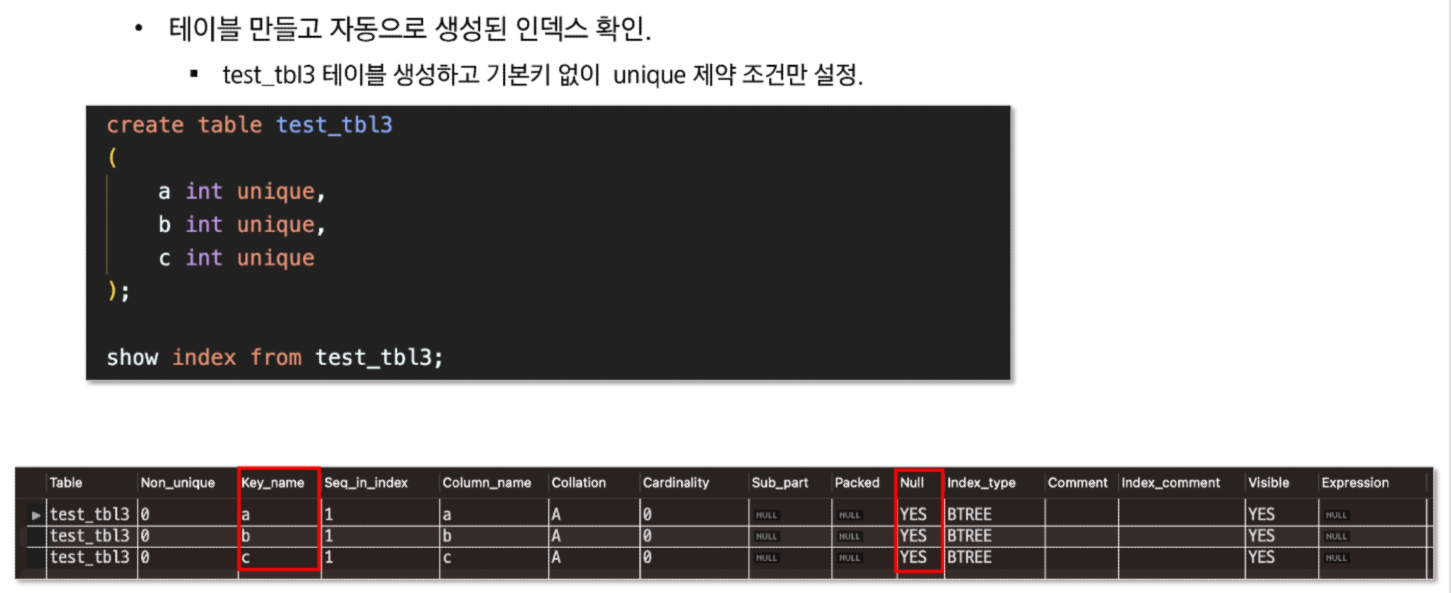
유니크하면 보조인덱스 생김
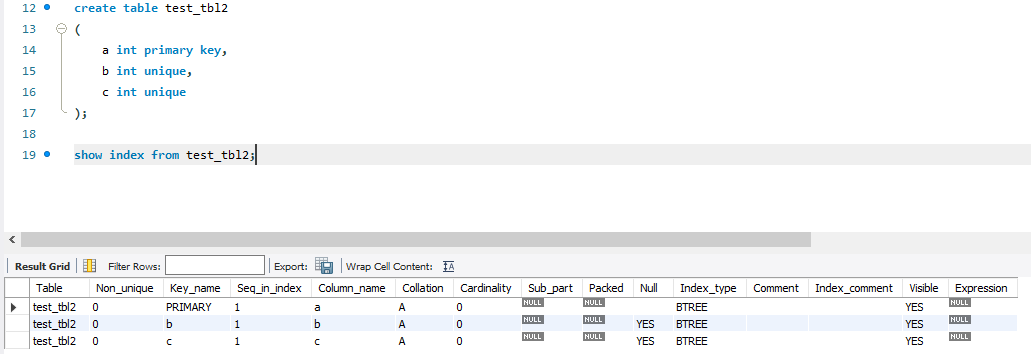
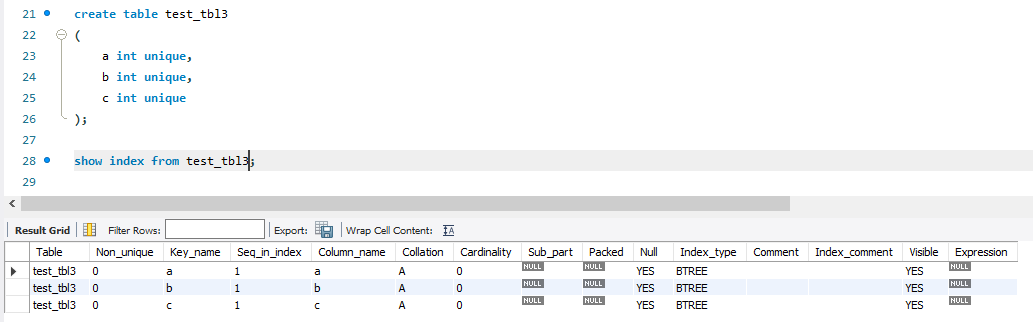
pk 기본적으로 인덱스 생성될 때 오름차순됨!
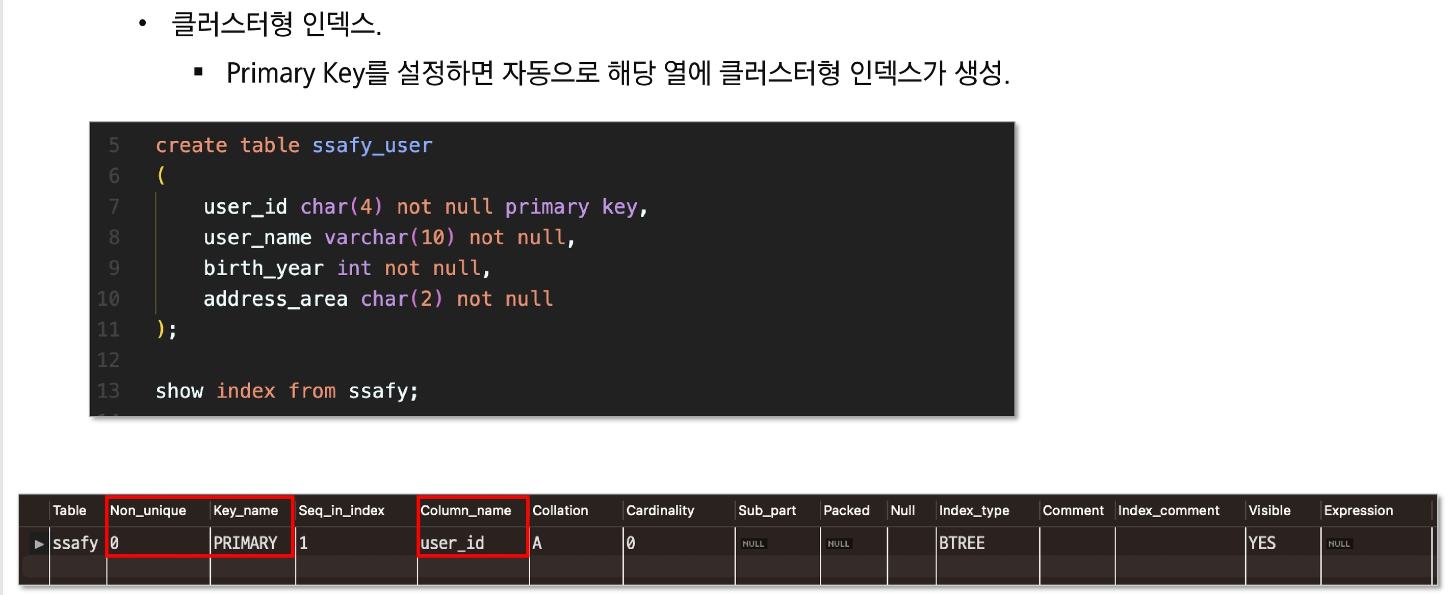
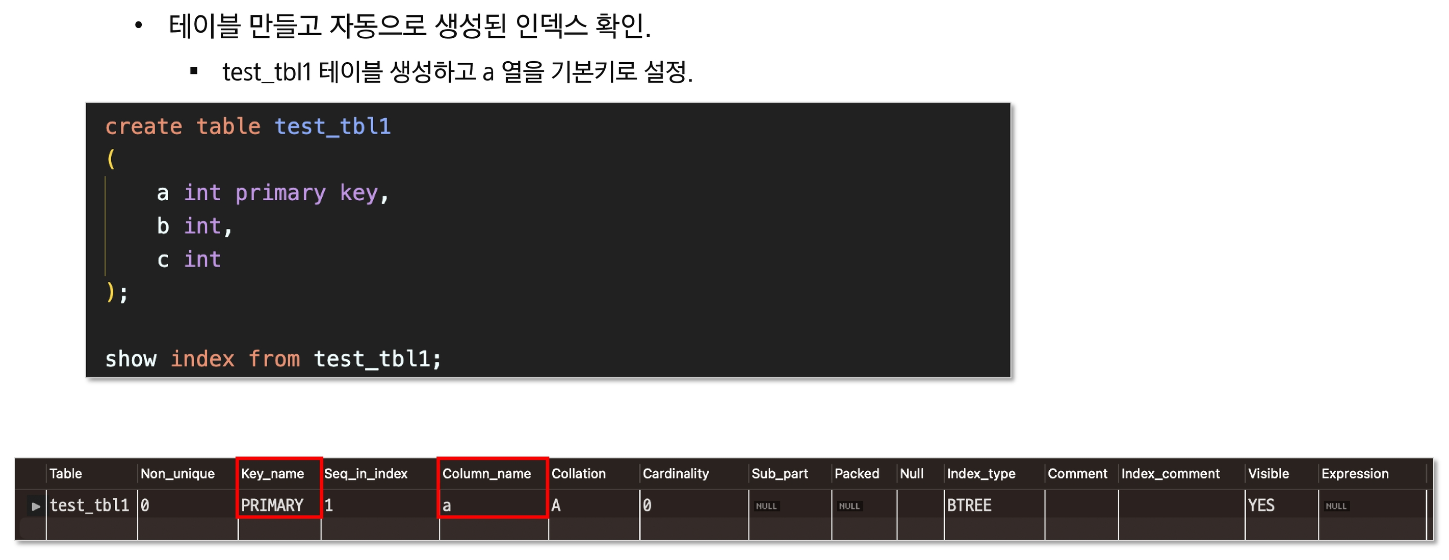
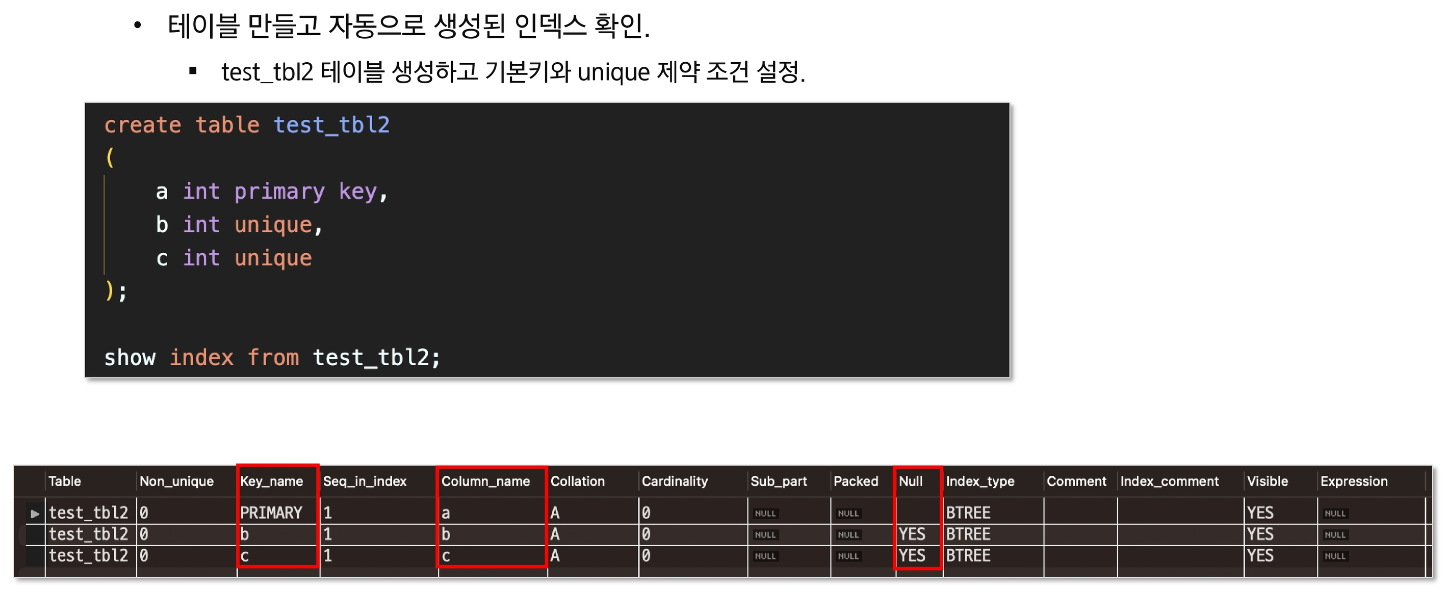

index 활용
Index 생성
- create index 문으로 인덱스를 만들면 보조 인덱스가 생성
- create index 문으로는 클러스터형 인덱스를 만들 수 없으며, 클러스터형 인덱스를 만들려면 alter table을 사용해야함
- create index 문의 unique옵션은 고유한 인덱스를 만들 때 사용
- ASC, DESC로 정렬 방식 지정
- index_type은 생략 가능하며, 생략할 경우 기본값인 B-Tree 형식 사용
show index from ss;
create index ss_address_area_idx on ss(address_area);
create index ss_user_name_birth_year_idx on ss(user_name, birth_year);
- 보조 인덱스 삭제
drop index 인덱스이름 on 테이블이름;- 자동으로 생성된 클러스터형 인덱스 삭제
alter table 테이블이름 drop primary key;
View
View?
- 데이터베이스에 존재하는 '가상의 테이블'
- 실제 행과 열을 가지고 있지만 데이터를 저장하고 있지는 않음
- 테이블처럼 물리적으로 저장되는 것은 아님
- join이나 subquery와 같이 여러 개의 테이블을 참조하여 데이터를 조회할 때 번거로움을 줄일 수 있음
- 단, MYSQL에서 View는 단지 다른 테이블이나 View에 있는 데이터를 보여주는 역할만 수행
- View와 Table의 차이점은, Table은 실질적인 데이터가 있지만 View는 데이터가 없고 SQL만 저장한다.
View 장점
- 특정 사용자에게 테이블 전체가 아닌 필요한 필드(보안성) 보여줄 수 있음
- DBMS의 사용자별 권한 관리 기능을 통해 사용자가 테이블에 직접적인 접근을 하지 못하도록 막을 수 있음
- 복잡한 쿼리를 단순화해서 사용할 수 있음
- 쿼리를 재사용할 수 있음
- 여러 방법의 데이터 조회에 알맞은 다양한 구조의 데이터 분석 기반을 구축할 수 있음
- 기존 테이블 구조를 변경하지 않음
View 단점
- 삽입, 삭제, 갱신 작업에 많은 제한 사항을 가짐
- View는 자신만의 인덱스를 가질 수 없음
View data 변경?
- View를 생성한 기존 테이블의 data가 업데이트되면 View의 내용도 update될까?
- update된다!!!
- View를 조회하게 되면, 옵티마이저에서 View를 생성할 때 저장해 놓은 Select문이 실행되는 것이기 때문에 View이 data또한 update가 된 것처럼 보임
View종류
- 단순 뷰(Simple Vie)
- 하나의 테이블로 생성
- 그룹 함수의 사용이 불가능
- distinct사용 불가능
- DML 사용 가능
- 복합 뷰(Complex View)
- 여러개의 테이블로 생성(join)
- 그룹 함수의 사용이 가능
- distinct 사용 가능
- DML 사용 불가능
- 인라인 뷰
- 일반적으로 가장 많이 사용
- from 절 안에 SQL문장이 들어가는 것을 인라인 뷰라 볼 수 있음
Simple View
- 단순 뷰에서 DML명령어 사용이 불가능한 경우
- View 정의 시 포함되지 않은 컬럼 중 not null 제약조건이 지정되어 있는 경우
- 산술 표현식을 포함한 컬럼이 표현되어 있는 경우
- distinct를 포함한 경우
- 그룹 함수나 group by 절을 포함한 경우
View 생성
create view 뷰이름
as
select 필드이름
from 테이블이름
where 조건;
- select 문에서 선택된 필드를 이용하여 새로운 View 생성
- View는 원본 테이블의 이름과 같은 이름을 사용할 수 없음
View 대체
-
설정한 필드를 대체하기 위해서는 새로운 View로 대체해야 함
create or replace view 뷰이름
as
select 필드이름
from 테이블이름
where 조건; -
뷰이름에 해당하는 View가 존재하면 replace, 존재하지 않으면 create가 일어남
View 수정
- alter 사용
alter view 뷰이름
as
select 필드이름
from 테이블이름
where 조건;
View 삭제
- drop 사용
drop view 뷰이름;

