TimescaleDB 사용을 고민하고 계신가요?
들어가는 말
스리슬쩍 업로드를 안했던 기술 블로그..(너무 바빴어요 ㅠㅠ)
이제 프로젝트가 다 끝남에 따라 마무리격으로 써보려고 한다.
이번 프로젝트에서 했던 경험 정리한 것으로 약간(많이) 날먹을 해보도록 하겠다.
🚀 시계열 데이터 조회 성능 최적화: PostgreSQL → TimescaleDB 도입
🧭 도입 배경
이번 프로젝트는 주식 모의투자 플랫폼 서비스로, 사용자에게 실시간으로 변동하는 캔들 차트(분봉, 일봉, 주봉, 월봉) 데이터를 제공해야 했습니다.
시계열 데이터를 다루기 위해 초기에는 PostgreSQL을 사용했지만,
대량의 거래 데이터를 대상으로 기간별 평균, 최고가, 최저가, 종가 등을 집계하는 쿼리가 잦아지면서 조회 속도가 느려지는 문제가 발생했습니다.
특히 사용자 수가 많아지고, 각 사용자가 다양한 기간(1분, 5분 등)으로 데이터를 요청할 경우, PostgreSQL의 단순 group by 쿼리로는 빠른 응답이 불가능했습니다.
이를 해결하기 위해 TimescaleDB를 도입하여 시계열 데이터에 특화된 최적화 기능을 활용하기로 결정했습니다.
🎯 고민: 빠른 조회를 위한 시계열 데이터 구조 최적화
PostgreSQL 사용 시의 문제
- 대량의 시계열 데이터에서 group by + aggregation 수행 시 쿼리 지연
- 동일한 데이터에 대해 반복 조회가 많아 불필요한 재계산 발생
- 압축 기능 부재로 스토리지 효율 낮음
- 지속적인 데이터 규모 증가
- 1분봉 데이터만으로도 하루에 약 7만 건 생성 (200개 종목 × 6시간 × 60분)
시계열 캔들 데이터 조회 쿼리
SELECT *
FROM minute_candles
WHERE stock_code = '005930'
AND time BETWEEN '2025-01-01' AND '2025-09-25'
ORDER BY time;집계된 데이터 조회 쿼리
SELECT date_trunc('day', time) AS day,
MAX(high), MIN(low),
FIRST(open, time), LAST(close, time)
FROM minute_candles
WHERE stock_code = '005930'
GROUP BY day;이러한 쿼리들은 단일 테이블에서 수천만 건을 스캔하게 되므로,
응답 시간이 오래 걸리는 경우가 많았습니다.
🤔 기술 선택지 검토
1. InfluxDB
- 장점: 시계열 데이터 전용 DB, 뛰어난 성능
- 단점: 완전히 새로운 시스템, 기존 PostgreSQL 스키마 폐기 필요
- 성능은 좋지만 기존에 구축한 사용자 관리, 거래 내역 등 모든 테이블을 마이그레이션해야 함
- 새로운 쿼리 언어(Flux)를 배워야 하는 러닝커브 있음
2. ClickHouse
- 장점: 분석 쿼리에 최적화, 압축률 우수
- 단점: OLTP 성능 부족, 실시간 삽입에 약함
- 주식 거래 데이터는 실시간으로 계속 들어오는데, ClickHouse는 배치 삽입에 최적화되어 있음
3. Redis TimeSeries
- 장점: 메모리 기반 초고속 처리
- 단점: 메모리 제약, 대용량 히스토리 데이터 저장 불가
- 최근 데이터는 빠르지만 1년치 히스토리 데이터를 모두 메모리에 올릴 수 없음
왜 TimescaleDB였나?
1. 기존 자산 100% 활용 가능
- PostgreSQL의 확장(Extension)이라서 기존 스키마, ORM, 운영 도구 모두 그대로 사용
- 사용자 테이블, 거래 내역 테이블은 그대로 두고 캔들 데이터만 선택적으로 Hypertable로 전환
2. 하이브리드 워크로드 완벽 지원
-
OLTP: 실시간 거래 데이터 삽입 (초당 1000건)
-
OLAP: 대용량 히스토리 데이터 집계 쿼리
💡 OLTP = Online Transaction Processing(실시간 거래 처리)
- 작은 단위의 데이터
- 조회/삽입 빈도: 매우 빈번
- 응답시간: 밀리초 단위
- 많은 사용자가 동시 접근
💡 OLAP = Online Analytical Processing(분석용 데이터 처리)
일반적인 OLAP- 대용량 데이터 집계
- 빈도: 상대적으로 적음
- 응답시간: 초~분 단위 (복잡한 계산)
- 소수의 분석가가 사용
하지만 우리 서비스의 OLAP는 유저 대부분이 차트 조회 시 OLAP가 필요
3. 점진적 마이그레이션 가능
- 서비스 중단 없이 테이블별로 순차 전환
- 혹시 문제가 생기면 언제든 다시 일반 PostgreSQL 테이블로 되돌릴 수 있는 안전성
TimescaleDB의 특장점
✅ 하이퍼테이블(Hypertable)
- TimescaleDB의 핵심 개념
- 일반 테이블처럼 보이지만 사실상 내부적으로 많은 작은 테이블(Chunk)로 나뉜 시계열 전용 테이블
- 큰 시계열 데이터를 자동으로 시간 단위로 분할(Chunking) 해서 저장 → 성능 향상, 관리 용이
✅ 압축(Compression)
- 청크 단위로 압축 가능
- 읽기 시 자동으로 압축 해제
- 저장 용량 대폭 절감
- 대량 조회 시 디스크 I/O 감소
✅ 사전 집계(Continuous Aggregate)
- 대량 시계열 데이터를 미리 집계하여 조회 성능 향상
time_bucket()으로 원하는 단위(예: 5분, 1일)로 집계- 실제 데이터가 변경되어도 일정 주기로 자동 갱신 가능
- 일반 뷰처럼 조회 가능 → 매번 원본 데이터 계산 불필요
🔍 PostgreSQL vs TimescaleDB: 내부 동작 원리 비교
예시: 삼성전자 3개월 일봉 데이터 조회
SELECT date_trunc('day', time) AS day,
FIRST(open, time) AS daily_open,
MAX(high) AS daily_high,
MIN(low) AS daily_low,
LAST(close, time) AS daily_close
FROM minute_candles
WHERE stock_code = '005930'
AND time BETWEEN '2025-03-01' AND '2025-05-31'
GROUP BY day
ORDER BY day;PostgreSQL의 내부 구조 및 처리 과정

1단계: 쿼리 파싱 및 실행 계획 생성
Query Planner가 실행 계획 수립
└── 전체 테이블 스캔 계획 수립 (인덱스가 있어도 대용량에서는 비효율)2단계: 전체 테이블 순차 스캔
minute_candles 테이블 (1억 행)
├── 2025-01-01 데이터 (불필요) ✗
├── 2025-02-01 데이터 (불필요) ✗
├── 2025-03-01 데이터 (필요) ✓
├── 2025-04-01 데이터 (필요) ✓
├── 2025-05-01 데이터 (필요) ✓
├── 2025-06-01 데이터 (불필요) ✗
└── ... (모든 데이터를 읽어야 함)- 전체 데이터를 탐색해야 함
3단계: WHERE 조건 필터링
- 메모리에 로드된 1억 행에서 조건에 맞는 600만 행 추출
4단계: GROUP BY 집계 연산
- 600만 행을 날짜별로 그룹화
- FIRST, MAX, MIN, LAST 함수 계산
- 해시 테이블 생성으로 추가 메모리 사용
5단계: 결과 정렬 및 반환
TimescaleDB의 내부 구조 및 처리 과정

1단계: 쿼리 파싱 및 하이퍼테이블 인식
Query Planner가 하이퍼테이블 메타데이터 확인
└── 관련 청크 식별을 위한 Constraint Exclusion 준비2단계: 청크 프루닝 (Chunk Pruning)
전체 50개 청크 중 필요한 청크만 식별:
chunk_202501 (2025-01-01~01-07) ✗ 시간 범위 밖
chunk_202502 (2025-01-08~01-14) ✗ 시간 범위 밖
...
chunk_202509 (2025-03-01~03-07) ✓ 조건 일치!
chunk_202510 (2025-03-08~03-14) ✓ 조건 일치!
...
chunk_202522 (2025-05-24~05-31) ✓ 조건 일치!3단계: 병렬 청크 스캔
청크를 CPU 코어별로 병렬 처리
- 각 청크는 평균 200만 행으로 관리 가능한 크기
- 청크별 독립적인 인덱스 활용으로 빠른 접근
4단계: 압축 데이터에서 직접 집계
압축 블록 메타데이터 활용:
block_1: MIN=50000, MAX=51000, COUNT=1000, FIRST_TIME=09:00, LAST_TIME=09:01
block_2: MIN=51000, MAX=52000, COUNT=1000, FIRST_TIME=09:01, LAST_TIME=09:02
...
GROUP BY day는 압축 블록의 메타데이터만으로 90% 계산 완료
실제 행 데이터 접근은 FIRST/LAST 계산 시에만 필요5단계: 청크별 결과 병합
- 각 청크에서 계산된 일별 집계를 최종 병합
🛠️ 우리 프로젝트에 적용
1. Hypertable 전환
minute_candles(분봉), daily_candles(일봉), weekly_candles(주봉), monthly_candles(월봉)을 각각 Hypertable로 변환했습니다.
SELECT create_hypertable('minute_candles', 'time', 'stock_code');
SELECT create_hypertable('daily_candles', 'time', 'stock_code');
SELECT create_hypertable('weekly_candles', 'time', 'stock_code');
SELECT create_hypertable('monthly_candles', 'time', 'stock_code');time컬럼 기준으로 시간별 chunk 분할stock_code기준으로 병렬 처리 효율 향상- 쿼리 시 해당 기간 chunk만 접근하므로 I/O 대폭 감소
2. 압축(Compression) 활성화
과거 데이터(예: 3개월 이상 지난 캔들 데이터)는 자주 조회되지 않으므로
TimescaleDB의 압축 기능을 적용했습니다.
ALTER TABLE minute_candles SET (
timescaledb.compress,
timescaledb.compress_segmentby = 'stock_code'
);
SELECT compress_chunk(i) FROM show_chunks('minute_candles', older_than => INTERVAL '90 days') i;- 압축된 상태에서도
MAX,MIN,AVG등 aggregate 함수 바로 실행 가능
3. Continuous Aggregate(사전 집계) 적용
1분봉 데이터를 기반으로 3분봉/5분봉 등을 생성하는 쿼리를 위해
사전 집계(Materialized View)를 활용했습니다.
💡 Materialized View?
- 일반 PostgreSQL 기능
- 쿼리 결과를 실제 테이블로 저장
💡 Continuous Aggregate?
- TimescaleDB가 시계열용으로 확장한 Materialized View
WITH (timescaledb.continuous)옵션을 사용- 자동으로 새로운 데이터가 추가될 때 집계 갱신 가능
- 주로
time_bucket()과 함께 사용 → 시계열 집계 최적화- 기존 MV와 달리 자동/부분 갱신 기능 제공
-- 5분봉 continuous aggregate 생성
CREATE MATERIALIZED VIEW five_minute_from_minute
WITH (timescaledb.continuous) AS
SELECT
time_bucket('5 minutes', time) AS five_minute,
stock_code,
FIRST(open, time) AS open,
MAX(high) AS high,
MIN(low) AS low,
LAST(close, time) AS close,
SUM(volume) AS volume
FROM minute_candles
GROUP BY five_minute, stock_code;
-- 초기 집계 실행
CALL refresh_continuous_aggregate('five_minute_from_minute', NULL, NULL);- 매일 데이터 자동 업데이트
- 단위 다른 분봉 요청 시 원본 테이블 스캔 없이 즉시 응답
⚡ 성능 비교 결과
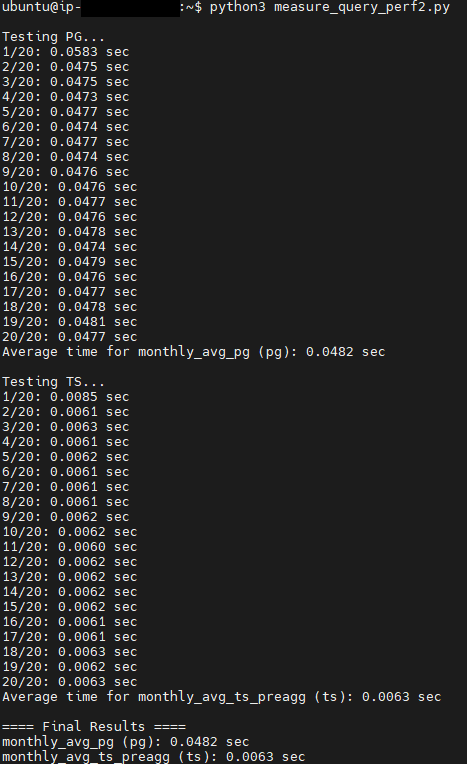
| 항목 | PostgreSQL | TimescaleDB |
|---|---|---|
| 데이터 수 | 144,646행 | 144,646행 |
| 조회 쿼리 (일별 평균) | 약 0.0482 | 약 0.0063 |
- 동일한 쿼리 환경에서 TimescaleDB는 약 7배 이상 빠른 응답 속도
📈 개선 결과
- ✅ 실시간 차트 렌더링 시 데이터 로딩 속도 향상
- ✅ 기간별 캔들 조회 시 딜레이 없이 즉시 응답
- ✅ 데이터가 1억 건 이상 쌓여도 성능 저하 없이 안정적 유지
- ✅ 단위를 바꾼 분봉 조회도 사전 집계를 통해 즉시 응답
🚀 향후 개선 방향
1. 실시간 + 배치 혼합 구조
- 최신 데이터는 실시간으로 쿼리 + 과거 데이터는 Continuous Aggregate에서 조회하는 혼합 전략
2. Redis 캐시 도입
- 인기 종목의 최근 캔들 데이터는 Redis에 캐싱하여 DB 부하 감소 및 응답 속도 향상
3. 자동 압축 & 집계 스케줄링
- 일정 기간이 지난 chunk는 자동 압축
- Continuous Aggregate 자동 리프레시 스케줄링으로 운영 자동화
💡 정리
- 시계열 데이터는 일반 RDB보다 시계열 특화 엔진이 필수
- Hypertable, 압축, 사전 집계를 조합하면 👉 성능 + 저장 효율 + 관리 편의성 모두 향상
- TimescaleDB는 PostgreSQL 기반이라, 기존 쿼리와 호환성을 유지하면서도 시계열 데이터 성능을 극적으로 개선할 수 있음
맺는 말
사실 timescaledb를 도입할때는 큰 고민이 없었다.
'우리가 PostgreSQL을 쓰니까 당연히 시계열은 그 확장인 TimescaleDB를 써야지~'라고만 생각했으니까!!
그런데 프로젝트를 경험으로써 정리하는 과정에서는 그 이유가 꼭 필요하더라..
그래서 선도입 후고민을 좀 해보았다!(클로드와 함께)
벌써 특화 프로젝트가 끝났다! 짧게만 느껴졌는데(실제로 엄청엄청대박왕짧음), 다른 팀들은 이 기간에 어떻게 개발한건지 너무 신기하다.
마지막에 유저테스트를 하루(원래 계획은 사흘이었다..) 진행했는데, 너무 재밌었다!
버그가 발생하는걸 실시간으로 지켜보고, 문제가 발생할 예정인 걸 뒤늦게 알아채고 급하게 서버 내리고..
찬이형이 없어서 그랬는지 막판에 불안불안~했지만 그래도 재밌게 해주신 분들이 계셔서 뿌듯했다! 실사용자 피드백 받은건 처음이야!!
실제 사용할만한 서비스를 만든다는게 얼마나 힘든건지 다시한번 느끼면서.. 이번 프로젝트도 너무 고생 많았다! 팀원분들도 나도!!
