코로나 데이터 Prophet 기계학습
- 데이터 불러오기
- date & total_case 컬럼의 이름을 각각 ds, y로 변경
- prophet을 이용한 학습시, ds & y 2개의 열이 들어가야 하고
- ds의 경우 날짜 형태로 존재해야
import pandas as pd
from prophet import Prophet
data = pd.read_csv('/content/drive/MyDrive/AI스쿨 파일/owid-covid-data.csv')
data
data.rename(columns={'date':'ds','total_cases':'y'},inplace=True)
want = data[data.location=='South Korea']
df = pd.DataFrame()
df = want[['ds', 'y']]
df
2. prophet 학습 & 예측 데이터 프레임 확인
# 프로핏 모델 객체 만들기
m = Prophet()
# 데이터프레임 학습하기
m.fit(df)
# 예측 데이터프레임 준비하기
future = m.make_future_dataframe(periods=1000) # 1000개의 예측대상 frame 만들기
# 끝부분 확인하기
future.tail()
3. 예측 & 시각화
# 예측하기
forecast = m.predict(future) # predict() --> 예측하기
# 예측 결과 끝부분 확인하기
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
# 시각화
plot_plotly(m2, forecast2)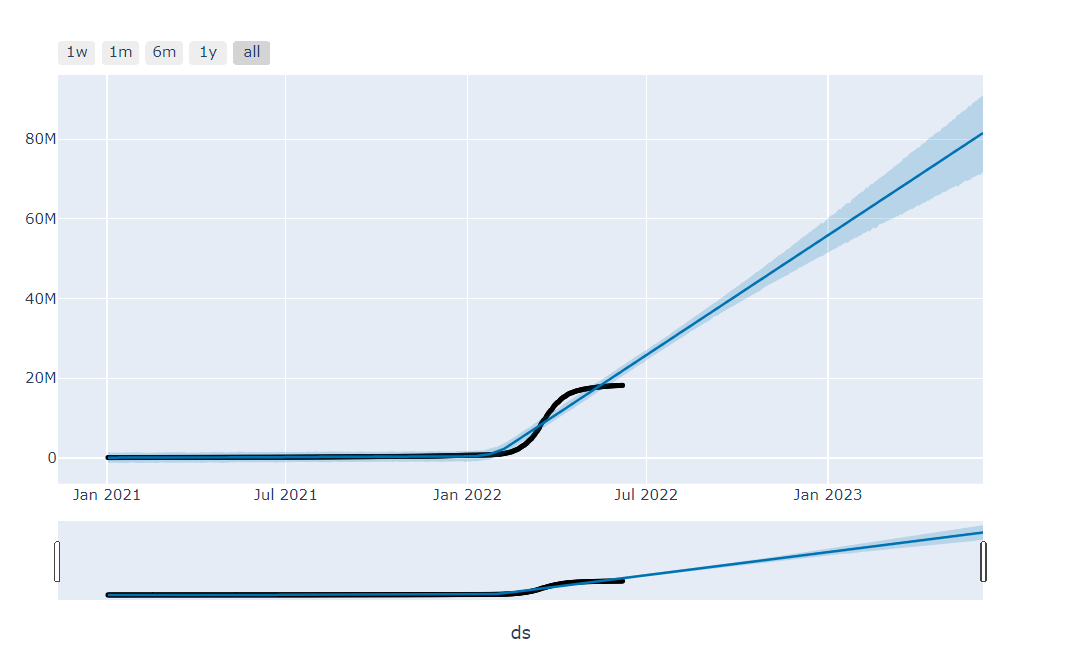
4. 2차 예측 & 시각화
# 2차 예측을 위한 프로핏 객체 만들기
m2 = Prophet()
# 2021년 1월 1일 이후 데이터만 준비
df2 = df[df['ds'] > '2021-01-01']
# 데이터 학습하기
m2.fit(df2)
# 예측 데이터프레임 만들기
future2 = m2.make_future_dataframe(periods=365)
# 예측하기
forecast2 = m2.predict(future2)
# plot 모듈 탑재
from prophet.plot import plot_plotly, plot_components_plotly
# 대화형 예측 그래프 그리기
plot_plotly(m2, forecast2)
트리맵
- stack overflow 설문 데이터 사용
- 데이터 불러와 DevType 컬럼의 문자열을 리스트로 변환
# 개발자 타입 열 확인
data['DevType']
# 문자열을 리스트로 변환
dev_type = data['DevType'].str.split(';')
dev_type- str.split(';')을 통해 변환

- 결손치 제거
# 결손치 제거
dev_type.dropna(inplace=True)
dev_type.isnull().sum()
dev_type
3. 리스트 항목을 각 열로 나누고 유일값 확인
# 리스트 항목 각 열로 나누기
exploded_dev_type = dev_type.explode()
exploded_dev_type
# 유일한 값 확인
exploded_dev_type.unique()
- explode() : 리스트 형태의 열을 풀어서 각 요소를 새로운 행으로 만듦
- 특정 값 추출
- 'Data scientist or machine learning specialist' / 'Data or business analyst'
data_analyst_data = data[data['DevType'].isin(['Data scientist or machine learning specialist', 'Data or business analyst'])]
data_analyst_data['DevType']
5. 프로그래밍 언어에 대해서도 리스트 형태로 변환
# 프로그래밍 언어 데이터 추출
languages = data_analyst_data['LanguageHaveWorkedWith']
# 데이터 확인
languages
# 데이터 문자열 변환 후 구분자(;)로 구분
languages = languages.str.split(';')
# 데이터 확인
languages
6. 프로그래밍별 응답 수 구하기
# 리스트 항목을 행으로 나누기
exploded_languages = languages.explode()
# 데이터 확인
exploded_languages
# 프로그래밍 별 응답 수 구하기
size_by_languages = exploded_languages.groupby(exploded_languages).size()
# 데이터 빈도 역순으로 정렬
size_by_languages.sort_values(ascending=False, inplace=True)
size_by_languages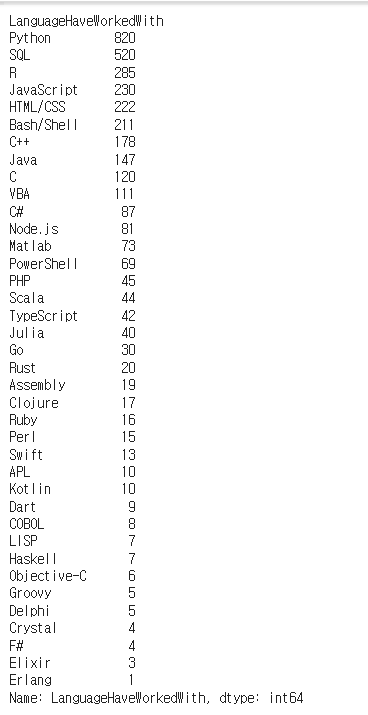
7. 위 결과를 딕셔너리 형태로 변환
# 데이터프레임 만들기 위한 딕셔너리 만들기
frame = {'language': size_by_languages.index, 'count': size_by_languages.values}
# 데이터프레임 만들기
size_by_languages_df = pd.DataFrame(frame)
size_by_languages_df.head(10)
# 매트플랏립 라이브러리 탑재
import matplotlib.pyplot as plt
# Wordcloud 라이브러리 탑재
from wordcloud import WordCloud
# 데이터프레임을 딕셔너리로 변경하기
size_by_languages.to_dict()
8. 위 결과를 트리맵으로 표현
# plotly.express 모듈 탑재
import plotly.express as px
# 트리맵 그리기
fig = px.treemap(size_by_languages_df, path=['language'], values='count')
fig.show()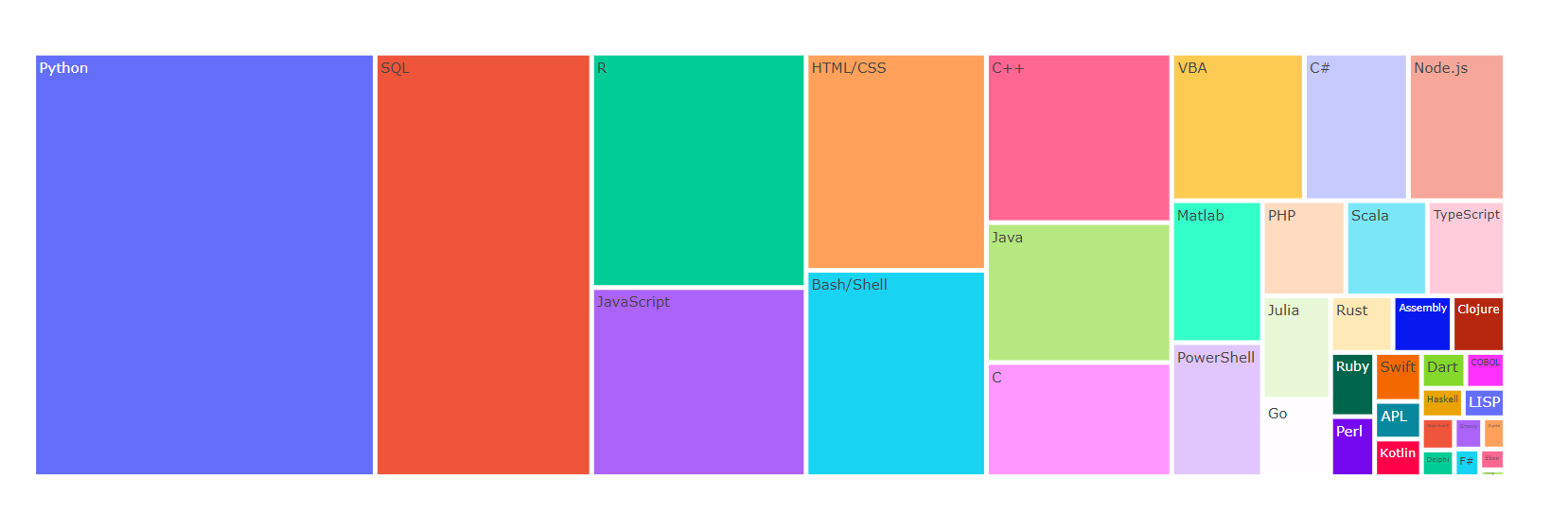
연관 관계 분석
- 트리맵 과정 중 프로그래밍 언어를 가지고 진행
- 결손치 제거 및 리스트 변환
# 결손치 제거
languages.dropna(inplace=True)
# 필터링을 위한 리스트로 변환
lang_list = languages.to_list()
# 일부 값 확인
lang_list[:10]
2. 추출할 언어 선정 및 필터링 결과 확인
# 추출 대상 프로그래밍 언어 선정
target_langs = ['Python', 'R', 'SQL','MATLAB', 'Go', 'SAS', 'Scala', 'Julia', 'Java', 'JavaScript']
# 필터링 완료된 프로그래밍 언어를 담기 위한 리스트 생성
revised_lang_list = []
# 필터링을 위해 전체 리스트 순회
for lang in lang_list:
# 추출 대상 프로그래밍 언어만 필터링
filtered = [x for x in lang if x in target_langs]
# 해당 리스트에 파이썬이 있는 경우에만 학습 대상 리스트에 추가
# if 'Python' in filtered:
# revised_lang_list.append(filtered)
revised_lang_list.append(filtered)
# 필터링 결과 확인
revised_lang_list
3. 전처리 & 데이터프레임 변환
from mlxtend.preprocessing import TransactionEncoder
# 전처리기 생성
te = TransactionEncoder()
# 전처리 수행
te_ary = te.fit(revised_lang_list).transform(revised_lang_list)
te_ary
new_languages = pd.DataFrame(te_ary, columns=te.columns_)
new_languages
4. 지지도 & 학습 + 결과 확인
from mlxtend.frequent_patterns import apriori, association_rules
# 지지도 구하기
freq_items = apriori(new_languages, min_support=0.01, use_colnames=True, verbose=1)
# 학습 결과 확인하기
freq_items.sort_values(['support'], ascending=False).head(20)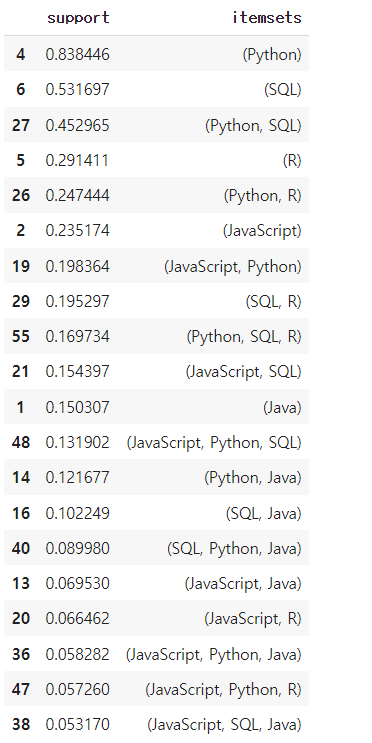
5. 항목 개수 추가
# 항목 집합의 항목 개수 추가하기
freq_items['length'] = freq_items['itemsets'].apply(lambda x: len(x))
freq_items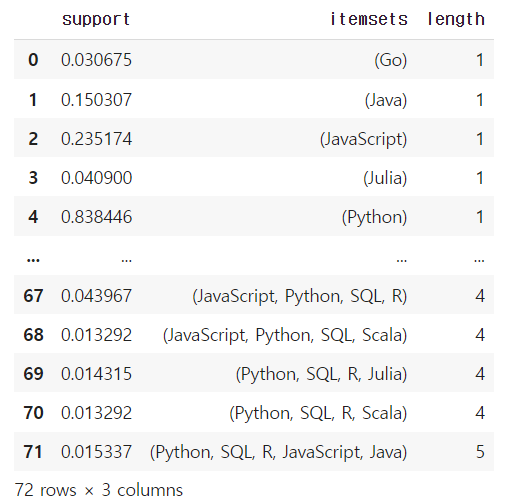
6. 신뢰도 & 향상도 구하기
rules = association_rules(freq_items, min_threshold=0.01)
rules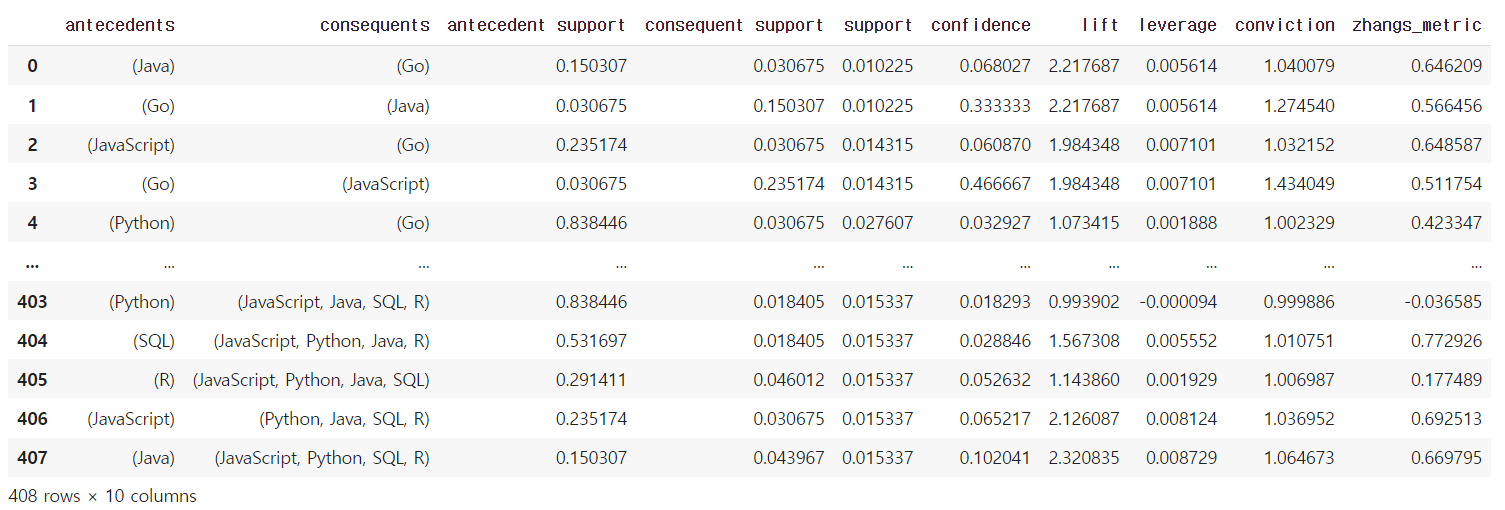
- antecedents : 연관규칙의 조건
consequents : 연관규칙의 결과
antecedent support : antecedents가 발생하는 비율
consequent support : consequents가 발생하는 비율
support antecedents와 consequents가 함께 발생하는 비율
confidence : antecedents가 주어졌을 때 consequents가 발생할 조건부 확률(연관 규칙의 신뢰도)
lift : antecedents와 consequents가 서로 독립일 때 대비하여 함께 발생하는 비율(연관 규칙의 향상도)
leverage : antecedents와 consequents의 동시 발생 빈도에서 독립적인 경우의 예상 빈도를 빼고 표준화한 값
conviction : , antecedents가 주어졌을 때 consequents가 발생하지 않을 확률에 대한 비율(연관 규칙의 확신도)
zhangs_metric : 신뢰도와 향상도의 비율로 계산되며, 두 항목 간의 상관성을 측정하는 데 사용
