이 글은 다음 쿼리를 완성하는 것을 목표로 합니다.
조건은 Natural_Cure_능력을_가진_포켓몬입니다.
포켓몬의 능력은 여러개일 수 있습니다.
@Test
void Natural_Cure_능력을_가진_포켓몬() throws IOException {
// TODO
}조건 분석
Natural_Cure_능력을_가진_포켓몬을 찾아야 합니다.
원본 데이터(csv)에서 포켓몬의 능력(abilities)은 다음과 같습니다.
name,abilities,...
이상해씨,"['Overgrow', 'Chlorophyll']",...
파이리,"['Blaze', 'Solar Power']"복수로 구성되어 있습니다.
이제 파싱하여 List 형태로 바꾸고, List 형태로 인덱싱하겠습니다.
abilities 파싱
아래와 같이 하나의 abilities array가 복수의 ability로 파싱되도록 개발했습니다.
"['Overgrow', 'Chlorophyll']" → Overgrow, Chlorophyll
private static void indexAbilitiesStat(String pokemonStat, String statName, Document document) {
String processed1 = pokemonStat.substring(1, pokemonStat.length() - 1);
String processed2 = processed1.replace("\'", "");
String[] splittedString = processed2.split(",");
List<String> abilitiesStat = Arrays.stream(splittedString).map(String::trim).collect(Collectors.toList());
...문제는...
List을 lucene으로 저장하려면, 거기에 맞는 필드가 필요합니다.
하지만 List에 맞는 Field는 아무리 봐도 없습니다.
모두 단건으로 데이터를 저장하는 필드들 뿐입니다.
복수의 데이터를 저장하려면,
→ 같은 필드의 이름으로 데이터를 여러 번 저장하면 됩니다.
이전에 NumericDocValuesField, StoredField, DoublePoint 세 개의 필드를 같은 이름으로 저장하여 정렬, Range 검색 등을 가능하게 했던 점을 상기해 보겠습니다.
복수의 데이터를 하나의 필드로 저장하고 싶은 경우, 같은 이름의 필드로 여러 번 저장하면 됩니다.
같은 이름의 필드로 여러 번 저장해도 이전 값들을 엎어치지 않습니다.
코드는 다음과 같습니다.
인덱싱 코드 수정
private static void indexAbilitiesStat(String pokemonStat, String statName, Document document) {
String processed1 = pokemonStat.substring(1, pokemonStat.length() - 1);
String processed2 = processed1.replace("\'", "");
String[] splittedString = processed2.split(",");
List<String> abilitiesStat = Arrays.stream(splittedString).map(String::trim).collect(Collectors.toList());
for (String abilityStat : abilitiesStat) {
indexString(document, abilityStat, statName);
}
}
private static void indexString(Document document, String pokemonStatValue, String statFieldName) {
FieldType type = new FieldType();
type.setStored(true);
Field field = new StringField(statFieldName, pokemonStatValue, Field.Store.YES);
document.add(field);
}abilities를 List< String >으로 파싱한 이후, 각각의 ability에 대해 동일한 필드 이름으로 인덱싱했습니다.
쿼리
@Test
void Natural_Cure_능력을_가진_포켓몬() throws IOException {
File file = new File("hi");
Directory directory = FSDirectory.open(file.toPath());
DirectoryReader directoryReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(directoryReader);
TermQuery query = new TermQuery(new Term("abilities", "Natural Cure"));
TopDocs search = indexSearcher.search(query, 1000);
for (int i = 0; i < search.totalHits; i++) {
Document doc = indexSearcher.doc(search.scoreDocs[i].doc);
System.out.println(doc.get("name") +" " + doc.get("abilities"));
}
}Natural Cure 에 대한 Term query를 수행했습니다.
쿼리는 간단합니다.
루씬은 abilities 필드에 대해 Natural Cure값이 존재하는 모든 문서를 전달합니다.
쿼리 수행
Natural Cure가 존재하는 포켓몬 16마리를 출력합니다.
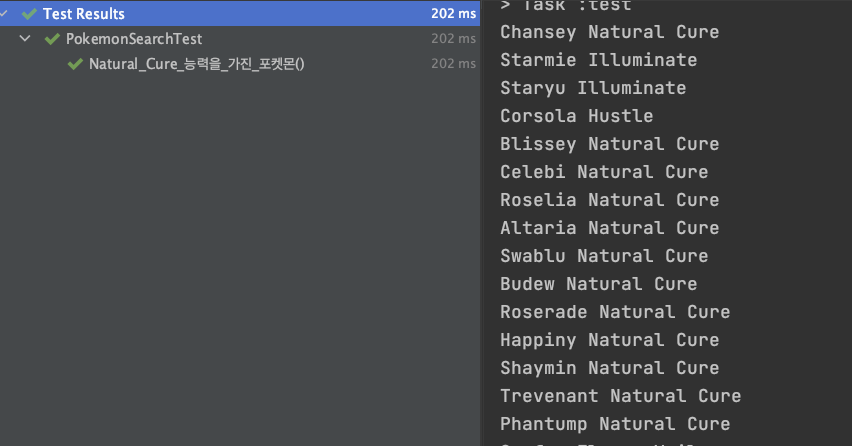
포켓몬 이름 옆에 Natural Cure가 아닌 것들이 있습니다. 이는 doc.get("abilities")에서 데이터가 복수로 존재하는 경우, 첫번째 값만을 전달하기 때문에 나타납니다. (doc.get()에 대한 설명)
이름 옆 Natural Cure가 아닌 포켓몬들은, 두번째 또는 n번째 능력으로 Natural Cure을 갖고 있다고 할 수 있습니다.
Elasticsearch 쿼리라면
elasticsearch 쿼리라면, 위 조건은 다음과 같이 표현할 수 있습니다.
{
"query": {
"term": {
"abilities": "Natural Cure"
}
}
}
