
Q Object & annotate
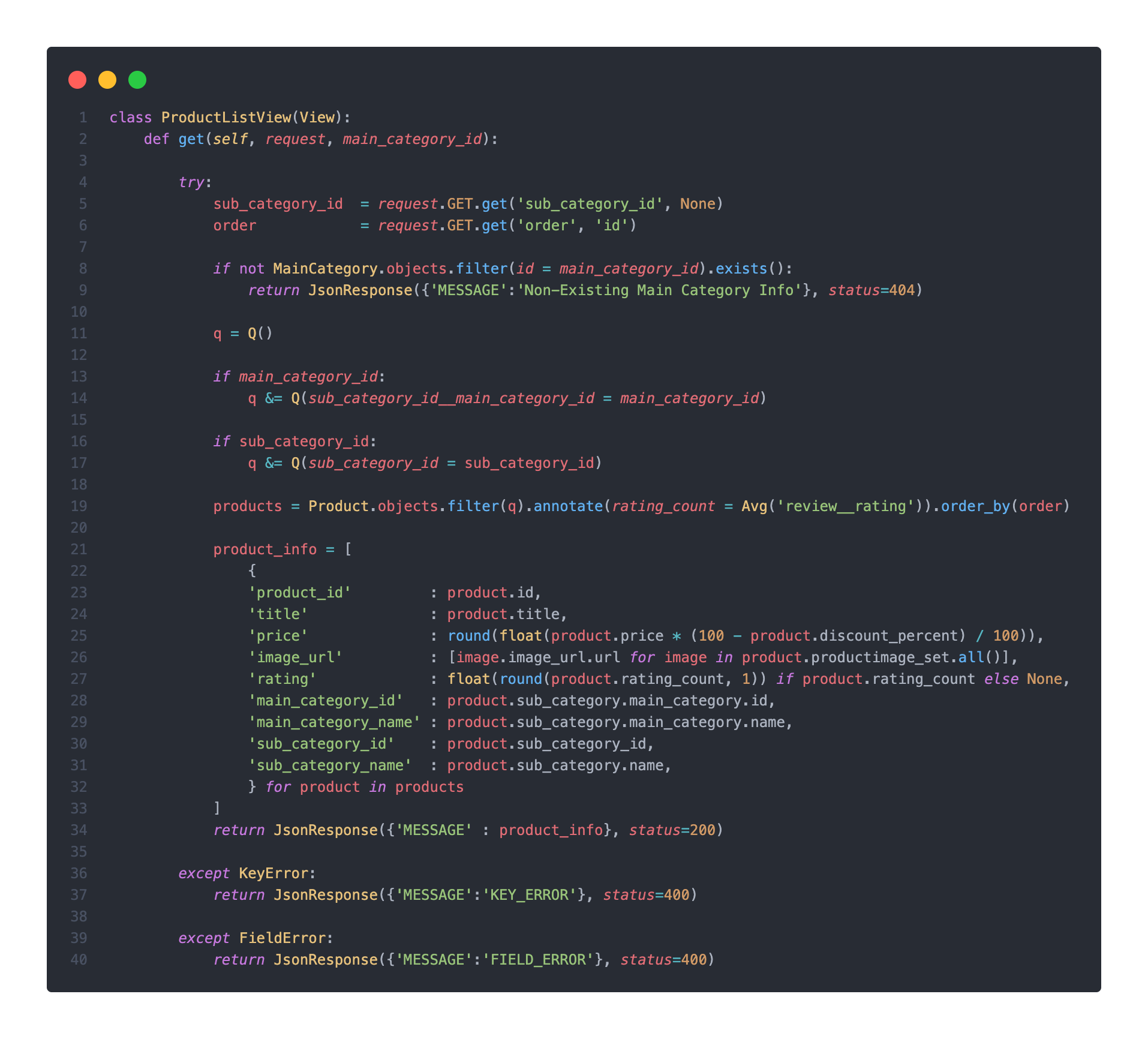
ProductListView
FLIP 프로젝트를 진행하며 내가 완성했던 코드에서 어떤걸 배웠고, 어떤 식으로 적용되었는 지를 간단하게 알아보고자 한다.
Q Object (Q 객체)
SQL의 WHERE절과 Q 객체의 관계
SQL에서 조건을 통해 검색하고자 할 때 WHERE절을 사용하고, Django에서는 동일한 로직을 수행하고자 할 때 Q 객체를 사용한다.
기준점

각 액티비티들은
- 메인 카테고리 (아웃도어, 스포츠, 베이킹 등..)
- 서브 카테고리 (서핑, 캠핑, 댄스, 클라이밍 등..)
두 개로 이루어진다.
나는 main_category는 path parameter를 통해 필수적으로 받고,
sub_cateogory와 filtering condition이 query parameter를 통해 받아지면 해당 액티비티들을 뿌려주고자 하였다.
즉,
아웃도어라는main_category의id만 받아지면 아웃도어 액티비티들을 모두 보여주고,서핑이라는sub_category의id가 같이 받아지면 아웃도어 안 서핑 액티비티들만 보여주며,-price와 같은 조건이 주어지면 필터링된 순서대로 서핑 액티비티들을 보여주고자 하였다.
코드 분석
위 코드를 보면, 두가지 로직으로 이루어 진다.
main_category_id를 path paramere를 통해 전달받는다- query parameter로
sub_category_id와order을 전달받는다.
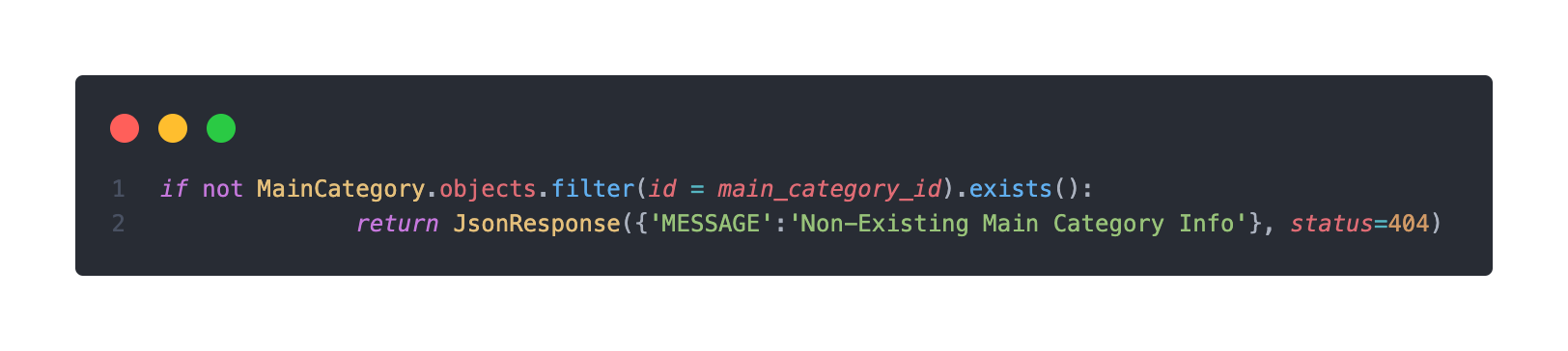
main_cateogry_id가 존재하지 않을때의 조건문 삽입
(사실 path parameter로 받을 때 존재하지 않으면 굳이 프론트에서 404 에러를 반환하지 않아도 프론트에서 바로 걸러진다고 한다. 하지만 필요한 작업이니 포함!)
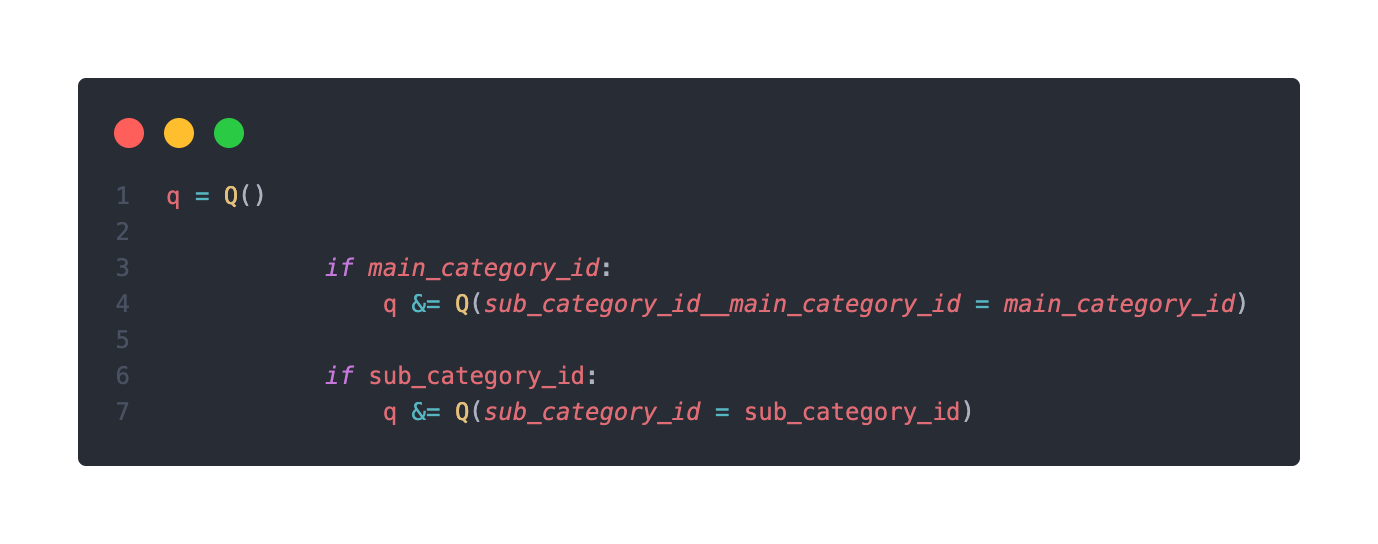
Q 객체 안에 main_category_id가 받아질 때와 sub_category_id가 받아질 때의 조건을 포함
and 조건(&=)을 걸어주었으므로 둘 다 들어왔을 때는 두개 다 검사를 하게 된다.

위 코드를 풀어 말해보자면,
- 위에서 Q 객체에 넣어진 정보를 기준으로 필터링
Product→Review테이블의rating의 평균을 계산하여rating_count라는 변수에 담음annotate표현식을 통해 Product에rating_count라는 row를 추가order_by를 통해order를 기준으로 정렬
4-1.order의 기준은 무엇이든 될 수 있으나, 해당 프로젝트에는price와review_rating을 적용
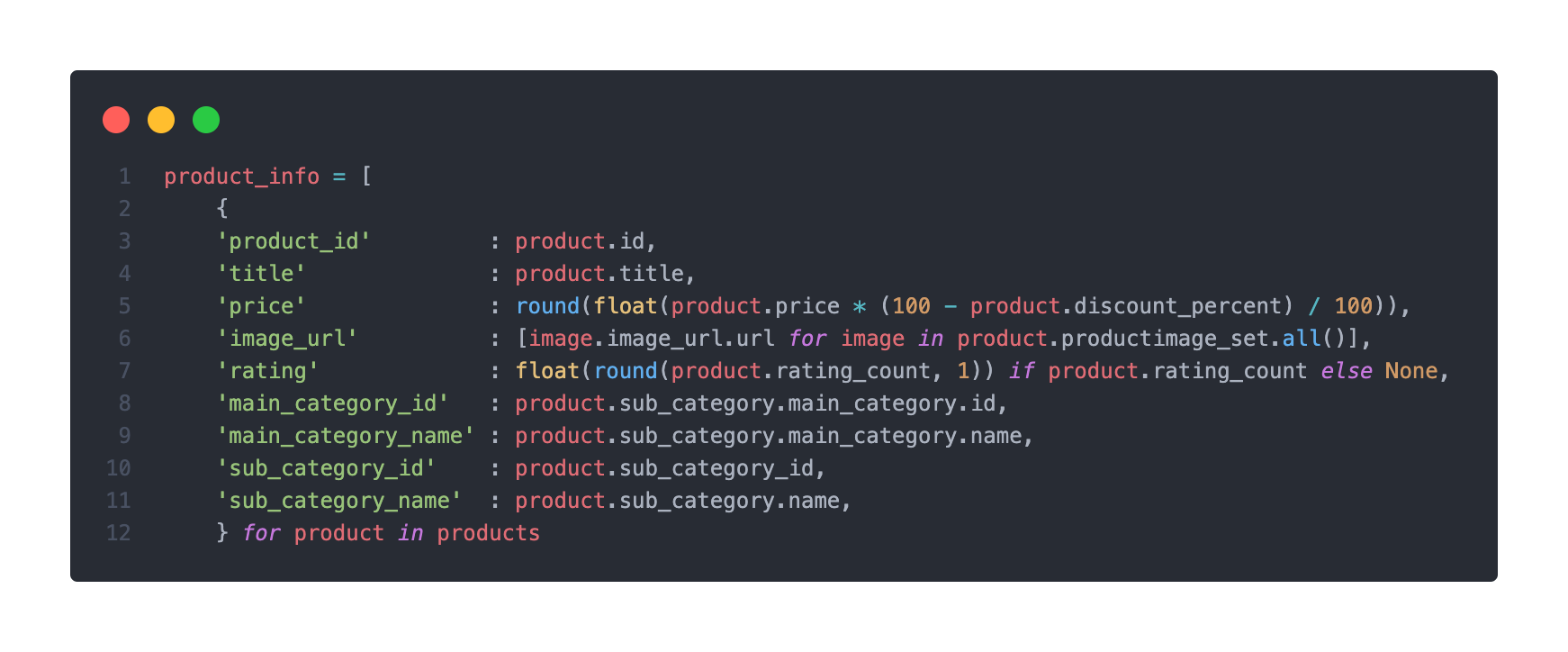
products에 담겨진 객체들을 기준으로 list에 담기
annotate 표현식
앞의 Atchapedia 프로젝트에서의 aggregate와 함께 정말 자주 사용되는 표현식이다.
Q 객체와 함께 쓰이는 경우가 정말 잦은데, 간단히 말하자면 기존 테이블에 새로운 row를 가상으로 추가하는 것이다.
annotate을 사전적으로 해석하면 "주석을 달다"인데, 정말 잘 어울리는 단어가 아닐까 싶다.
위 예시를 보면 알 수 있지만, Product 테이블에는 원래 평점 평균을 나타내는 데이터가 없다.
평점 평균을 계산하려면 Review 테이블에 있는 rating 데이터를 product_id를 통해 전부 조회하여 평균을 계산해야 한다.
하지만 annotate을 쓰면 정말 간단하게 해결이 가능하다.

앞서 사용한 코드를 다시 보자면,
우리가 Q 객체를 통해 필터링한 객체들의 rating 데이터를 review 테이블에서 조회하여 평균을 구하고, rating_count라고 이름을 지어 새로운 row를 만든 것이다.

이제 Product 테이블에는 rating_count라는 row가 주석이 달린 것처럼 새로 생겼으므로, 일반적으로 데이터를 불러오듯이 불러올 수 있는 것이다.
결과 예시

이제 위 url을 해석할 수 있다.
main_category_id=1(1번 메인 카테고리인 아웃도어의)sub_category_id=1(1번 서브카테고리인 서핑을)order=-price(가격 비싼 순으로 필터링해주세요)
Take Away
order_by의 기준은 오름차순
order_by는 기본적으로 내림차순으로 나열해준다.
즉 1-2-3-4-5-6... 식으로 진행된다.
그러니 위에서 ?order=price을 받게되면 가격을 오름차순으로 받게 되므로 싼 순서로 보여주고
?order=-price를 받게되면 가격을 내림차순으로 받게 되므로 비싼 순서대로 보여주게 된다.
