들어가며
본격적인 구현에 앞서 논문에서 제안하고 있는 주요 알고리즘인 DSA에 대해서 심도있게 알아보고 어떤 형태의 입,출력 값을 주어야할지 정확하게 알아봐야한다.
DSA 알고리즘
DSA는 Dynamic Spatial Attention의 줄임말로 동적인 공간정보(아마 움직임이 아닐까)에 대한 Attention을 수행하는 알고리즘이라고 유추할 수 있다.
구현을 목표로하는 논문이 'show attend and tell neural image caption generation with visual attention'에서 많은 아이디어를 가져왔는데 차이점은 image caption의 경우 이전 단어를 통해 이미지의 attention weight을 부여한 반면 본 논문은 Fast-RCNN을 통해 이미지의 attention weight을 부여했다는 차이가 있다. 또한 video인 만큼 frame 사이의 시,공간적인 정보가 중요한데 그래서 Dynamic Spatial이라는 말이 붙은 듯 하다.
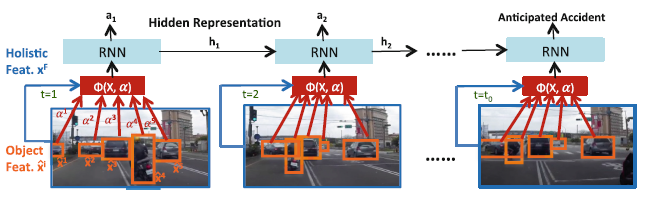
Fast-RCNN을 통해 인식된 주요 정보들(Car, Pedestrian, Traffic sign)을 각각 X라고 설정한다. 그리고 X에 대한 Attention weight을 곱해 LSTM의 Input으로 활용하는 것이 DSA의 주요 개념이다. 즉, 시,공간적인 정보를 다루는 LSTM 모델이 이미지의 어느 부분에 집중해야하는지를 알려주는 것이라고 할 수 있다.
DSA 알고리즘은 다음과 같다
- 이전 LSTM Cell에서 나온 h_(t-1)과 현재 프레임의 Object X를 Attention model에 넣는다. 이때 Attention model은 학습해야하는 임의의 모델로 다음과 같다.
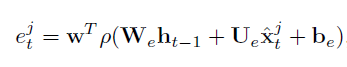
- Attention model는 e_t(unnormalized attention weight)을 출력하는데 이를 softmax에 넣어 alpha_t(attention weight)을 구한다.
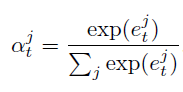
- alpha_t와 현재 프레임의 X값을 Dynamic weighted sum function에 넣어 현재 LSTM Cell의 Input 값을 생성한다.
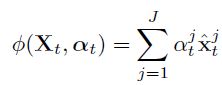
- 이 후 생성된 Input으로 LSTM을 수행한다. (X 자리에 생성된 Input 대입)
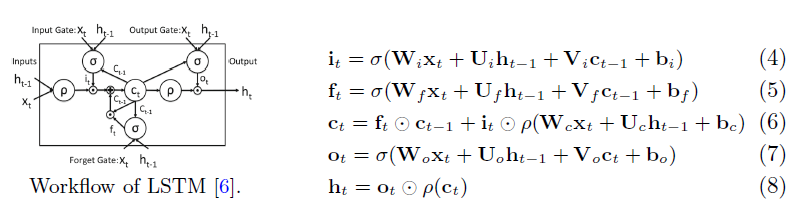
DSA의 Input : Fast-RCNN
그렇다면 DSA의 초기 Input 값인 X는 어떤 형태로 주어져야할까?
이를 이해하기 위해서는 Fast-RCNN에 대한 개념이 필요하다
Faster-RCNN
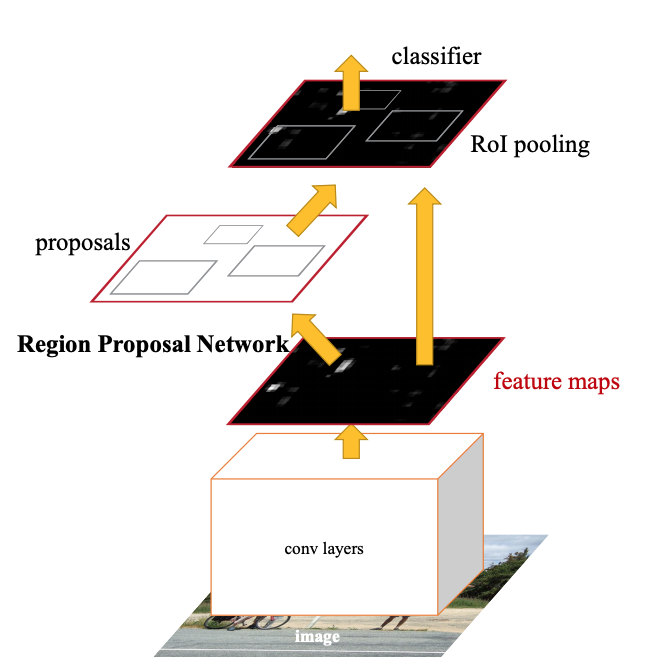
Faster-RCNN은 가장 유명한 Object detection 모델 중 하나이다.
Faster-RCNN에서는 RPN이다. 간단하게 이야기하자면 RPN에서 Objects들이 위치하고 있는 지역의 후보군을 추리고 각 후보군에 대한 features들을 추출하여 해당 위치에 objects들이 있는지, bounding box가 잘 그려져 있는지를 판별한다.
우리 프로젝트의 경우 Pytorch에서 제공하는 Resnet FPN 기반 Faster-RCNN을 사용하기 때문에 밑의 그림과 같은 구조의 모델을 사용한다.
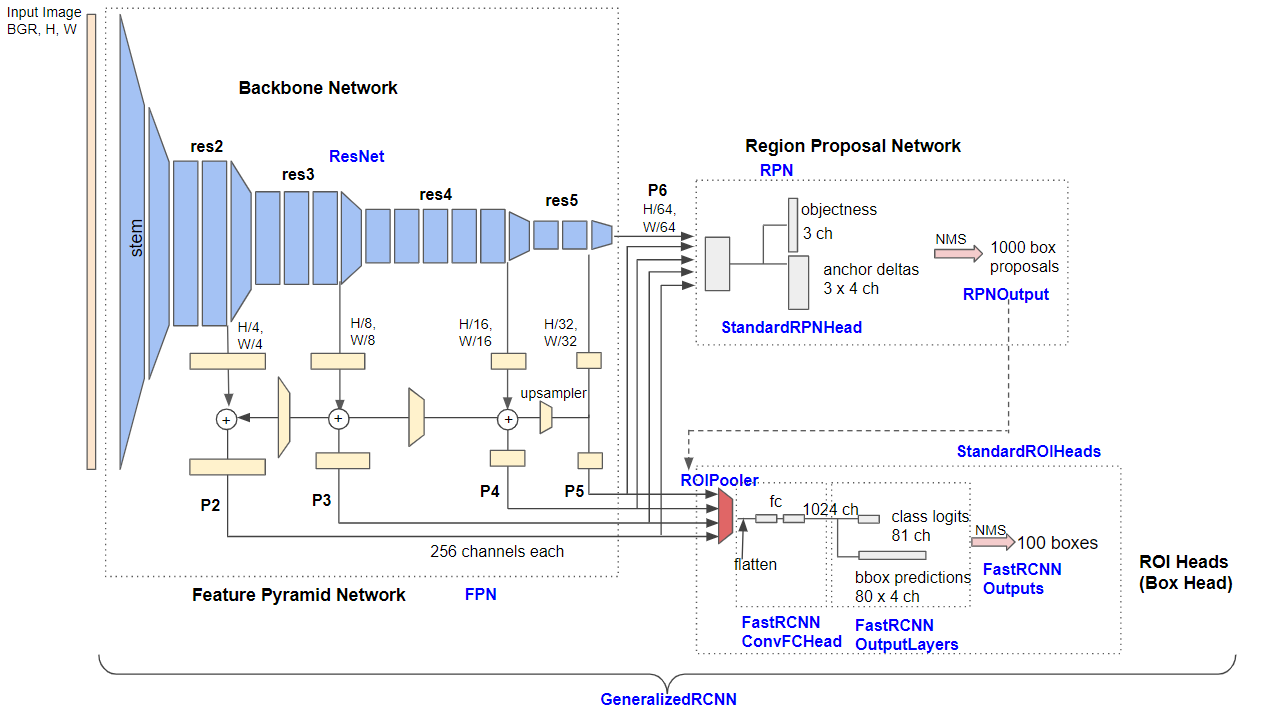
우리가 DSA 구현을 위해 뽑아주어야하는 Features는 RPN을 거쳐 나온 후보 Regions 각각의 features들인 것이다. 해당 features들을 뽑기 위해서는 bbox predictions, class logits를 판별하기 전 features들을 가져와야한다. 이 후 LSTM의 Cell에 시간대별로 각 Regions들의 features를 Input 값으로 입력, 학습하게 된다.
다음 글에서는 실제 dataset 구성에 맞는 학습 알고리즘을 설명하고 구현하겠다.
