
06-2 문자 함수
UPPER, LOWER, INITCAP
UPPER(문자열): 괄호 안 문자 데이터를 모두 대문자로 변환하여 반환LOWER(문자열):괄호 안 문자 데이터를 모두 소문자로 변환하여 반환INITCAP(문자열): 괄호 안 문자 데이터 중 첫 글자는 대문자로, 나머지 문자를 소문자로 변환 후 반환
SELECT ENAME, UPPER(ENAME), LOWER(ENMAE), INITCAP(ENAME)
FROM EMP;SELECT *
FROM EMP
WHERE UPPER(ENAME) = UPPER('scott');SELECT *
FROM EMP
WHERE UPPER(ENAME) LIKE UPPER('%scott%');LENGTH
LENGTH(문자열): 문자열 데이터 길이 반환LENGTHB(문자열): 문자열 데이터 바이트 수 반환
SELECT LENGTH('한글'), LENGTHB('한글')
FROM DUAL;| LENGTH('한글') | LENGTHB('한글') |
|---|---|
| 2 | 4 |
SUBSTR
SUBSTR(문자열 데이터, 시작 위치, 추출 길이)
문자열 데이터의 시작 위치부터 추출 길이만큼 추출한다. 시작 위치가 음수일 경우에는 마지막 위치부터 거슬러 올라간 위치에서 시작한다.SUBSTR(문자열 데이터, 시작 위치)
문자열 데이터의 시작 위치부터 문자열 데이터 끝까지 추출한다. 시작 위치가 음수일 경우에는 마지막 위치부터 거슬러 올라간 위치에서 끝까지 추출한다.- 즉,
CLERK이라는 데이터를 SUBSTR으로 반환할 때C는 -5,L은 -4,E는 -3,R은 -2,K는 -1의 위치이다.
SELECT JOB, SUBSTR(JOB, -LENGTH(JOB))
FROM EMP;| JOB | SUBSTR(JOB, -LENGTH(JOB)) |
|---|---|
| CLERK | CLERK |
INSTR
문자열 데이터 안에 특정 문자나 문자열이 어디에 포함되어 있는지를 알고자 할 때 사용
INSTR([대상 문자열 데이터(필수)],
[위치를 찾으려는 부분 문자(필수)],
[위치 찾기를 시작할 대상 문자열 데이터 위치(선택, 기본값은 1)],
[시작 위치에서 찾으려는 문자가 몇 번째인지 지정(선택, 기본값은 1)])SELECT INSTR('HELLO, ORACLE!', 'L') AS INSTR_1,
INSTR('HELLO, ORACLE!', 'L', 5) AS INSTR_2,
--- 5번 글자 O부터 L을 찾음
INSTR('HELLO, ORACLE!', 'L', 2, 2) AS INSTR_3,
--- 2번 글자 E부터 시작해서 두 번째 L을 찾음
FROM DUAL;INSTR함수로 사원 이름에 문자 S가 있는 행 구하기
SELECT *
FROM EMP
WHERE INSTR(ENAME, 'S') > 0;LIKE연산자로 사원 이름에 문자 S가 있는 행 구하기
SELECT *
FROM EMP
WHERE ENAME LIKE '%S%';REPLACE
REPLACE([문자열 데이터 또는 열 이름(필수)],
[찾는 문자(필수)],
[대체할 문자(선택)])SELECT '010-1234-5678' AS REPLACE_BEFORE,
REPLACE('010-1234-5678', '-', ' ') AS REPLACE_1,
REPLACE('010-1234-5678', '-') AS REPLACE_2;| REPLACE_BEFORE | REPLACE_1 | REPLACE_2 |
|---|---|---|
| 010-1234-5678 | 010 1234 5678 | 01012345678 |
LPAD, RPAD
LPAD([문자열 데이터 또는 열 이름(필수)],
[데이터 자릿수(필수)],
[빈 공간에 채울 문자(선택)])
RPAD([문자열 데이터 또는 열 이름(필수)],
[데이터 자릿수(필수)],
[빈 공간에 채울 문자(선택)])SELECT 'Oracle',
LPAD('Oracle', 10, '#') AS LPAD_1,
RPAD('Oracle', 10, '*') AS RPAD_1,
LPAD('Oracle', 10) AS LPAD_2,
RPAD('Oracle', 10) AS RPAD_2,
FROM DUAL;| Oracle | LPAD_1 | RPAD_1 | LPAD_2 | RPAD_2 |
|---|---|---|---|---|
| Oracle | ####Oracle | Oracle**** | ____Oracle | Oracle____ |
CONCAT
SELECT CONCAT(EMPNO, ENAME),
CONCAT(EMPNO, CONCAT(' : ', ENAME))
FROM EMP
WHERE ENAME = 'SCOTT';| CONCAT(EMPNO, ENAME) | CONCAT(EMPNO, CONCAT(' : ', ENAME) |
|---|---|
| 7788SCOTT | 7788 : SCOTT |
SELECT EMPNO || ENAME,
EMPNO || ' : ' || ENAME
FROM EMP
WHERE ENAME = 'SCOTT';
-- CONCAT 함수와 유사TRIM, LTRIM, RTRIM
TRIM
LEADGIN옵션 : 왼쪽에 있는 글자를 지움TRAILING옵션 : 오른쪽에 있는 글자를 지움BOTH옵션 : 양쪽의 글자를 모두 지움
TRIM([삭제 옵션(선택)]
[삭제할 문자(선택)]
-- 삭제할 문자 옵션 생략할 경우, 공백 삭제
FROM [원본 문자열 데이터(필수)])SELECT TRIM(' ##Oracle## ') AS TRIM_1,
TRIM('#' FROM '##Oracle##') AS TRIM_2,
TRIM(LEADING '#' FROM '##Oracle##') AS LEADING,
TRIM(TRAILING '#' FROM '##Oracle##') AS TRAILING,
TRIM(BOTH '#' FROM '##Oracle##') AS BOTH
FROM DUAL;| TRIM_1 | TRIM_2 | LEADING | TRAILING | BOTH |
|---|---|---|---|---|
| ##Oracle## | #Oracle# | #Oracle## | ##Oracle# | #Oracle# |
LTRIM, RTRIM
-- 삭제할 문자 옵션 생략할 경우, 공백 삭제
LTRIM([원본 문자열 데이터(필수)], [삭제할 문자 집합(선택)])
RTRIM([원본 문자열 데이터(필수)], [삭제할 문자 집합(선택)])-- 삭제할 문자 집합의 '조합'으로 시작하는 문자가 있으면 삭제!
SELECT LTRIM('<_Oracle_>', '_<') AS LTRIM,
RTRIM('<_Oracle_>', '>_') AS RTRIM
FROM DUAL;| LTRIM | RTRIM |
|---|---|
| Oracle_> | <_Oracle |
06-3 숫자 함수
ROUND
- 특정 숫자를 반올림한 결과를 출력
- 반올림 위치 옵션 생략할 경우 소수점 첫 번째 자리에서 반올림 수행
ROUND([숫자(필수)], [반올림 위치(선택)])SELECT ROUND(1234.5678, 0) AS ROUND_0,
-- 소수점 첫째자리에서 반올림
ROUND(1234.5678, 1) AS ROUND_1,
-- 소수점 둘째자리에서 반올림
ROUND(1234.5678, 2) AS ROUND_2,
-- 소수점 셋째자리에서 반올림
ROUND(1234.5678, -1) AS ROUND_MINUS1,
-- 자연수 첫째자리에서 반올림
ROUND(1234.5678, -2) AS ROUND_MINUS2
-- 자연수 둘째자리에서 반올림
FROM DUAL;| ROUND_0 | ROUND_1 | ROUND_2 | ROUND_MINUS1 | ROUND_MINUS2 |
|---|---|---|---|---|
| 1235 | 1234.6 | 1234.568 | 1230 | 1200 |
TRUNC
- 지정된 자리에서 숫자를 버림 처리
- 버림 위치 옵션 생략할 경우 소수점 첫 번째 자리에서 버림 처리
TRUNC([숫자(필수)], [버림 위치(선택)])SELECT TRUNC(1234.5678, 0) AS TRUNC_0,
-- 소수점 첫째자리부터 버림
TRUNC(1234.5678, 1) AS TRUNC_1,
-- 소수점 둘째자리부터 버림
TRUNC(1234.5678, 2) AS TRUNC_2,
-- 소수점 셋째자리부터 버림
TRUNC(1234.5678, -1) AS TRUNC_MINUS1,
-- 자연수 첫째자리부터 버림
TRUNC(1234.5678, -2) AS TRUNC_MINUS2
-- 자연수 둘째자리부터 버림
FROM DUAL;| TRUNC_0 | TRUNC_1 | TRUNC_2 | TRUNC_MINUS1 | TRUNC_MINUS2 |
|---|---|---|---|---|
| 1234 | 1234.5 | 1234.56 | 1230 | 1200 |
CEIL, FLOOR
CEIL([숫자(필수)]): 입력된 숫자와 가까운 큰 정수 반환FLOOR([숫자(필수)]): 입력된 숫자와 가까운 작은 정수
SELECT CEIL(3.14),
CEIL(3.14),
CEIL(-3.14),
FLOOR(-3.14)
FROM DUAL;| CEIL(3.14) | CEIL(3.14) | CEIL(-3.14) | FLOOR(-3.14) |
|---|---|---|---|
| 4 | 3 | -3 | -4 |
MOD
MOD([나눗셈 될 숫자(필수)], [나눌 숫자(필수)])SELECT MOD(15, 6),
MOD(10, 2),
MOD(11, 2)
FROM DUAL;| MOD(15, 6) | MOD(10, 2) | OD(11, 2) |
|---|---|---|
| 3 | 0 | 1 |
06-4 날짜 함수
SELECT SYSDATE AS NOW,
SYSDATE-1 AS YESTERDAY,
SYSDATE+1 AS TOMORROW
FROM DUAL;| NOW | YESTERDAY | TOMORROW |
|---|---|---|
| 02-APR-24 | 01-APR-24 | 03-APR-24 |
ADD_MONTHS
ADD_MONTHS([날짜 데이터(필수)], [더할 개월 수(정수)(필수)])- SYSDATE와 ADD_MONTHS 함수로 3개월 후 날짜 구하기
SELECT SYSDATE,
ADD_MONTHS(SYSDATE, 3)
FROM DUAL;| SYSDATE | ADD_MONTHS(SYSDATE, 3) |
|---|---|
| 02-APR-24 | 02-JUL-24 |
- 입사 10주년이 되는 사원들 데이터 출력하기
SELECT EMPNO, ENAME, HIREDATE,
ADD_MONTHS(HIREDATE, 120) AS WORK10YEAR
FROM EMP;- 입사 32년 미만인 사원 데이터 출력하기
SELECT EMPNO,
ENAME, HIREDATE, SYSDATE
FROM EMP
WHERE ADD_MONTHS(HIREDATE, 384) > SYSDATE;MONTHS_BETWEEN
MONTHS_BETWEEN([날짜 데이터1(필수)], [날짜 데이터2(필수)])SELECT EMPNO, ENAME, HIREDATE, SYSDATE,
MONTHS_BETWEEN(HIREDATE, SYSDATE) AS MONTHS1,
MONTHS_BETWEEN(SYSDATE, HIREDATE) AS MONTHS2,
TRUNC(MONTHS_BETWEEN(SYSDATE, HIREDATE)) AS MONTHS3
FROM EMP;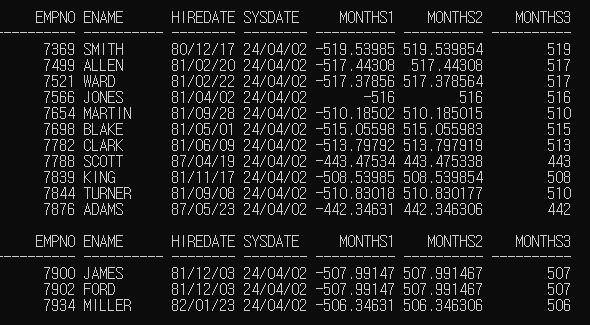
NEXT_DAY, LAST_DAY
특정 날짜를 기준으로 돌아오는 요일의 날짜를 출력
NEXT_DAY([날짜 데이터(필수)], [요일 문자(필수)])특정 날짜가 속한 달의 마지막 날짜를 출력
LAST_DAY([날짜 데이터(필수)])SELECT SYSDATE,
NEXT_DAY(SYSDATE, '월요일'),
LAST_DAY(SYSDATE)
FROM DUAL;| SYSDATE | NEXT_DAY | LAST_DAY |
|---|---|---|
| 24/04/02 | 24/04/08 | 24/04/30 |
ROUND, TRUNC (날짜 데이터)
날짜 데이터를 입력 데이터로 사용할 때는 소수점 위치 정보를 입력하지 않고 포맷 값을 지정함
CC,SCC
네 자리 연도의 끝 두 자리를 기준으로 사용SYYY,YYYY,YEAR,SYEAR,YYY,YY,Y
날짜 데이터의 해당 연/월/일의 7월 1일을 기준CC,SCC
네 자리 연도의 끝 두 자리를 기준으로 사용
(2016년이면 2050 이하이므로, 반올림할 경우 2001년으로 처리)SYYYY,YYYY,YEAR,SYEAR,YYY,YY,Y
날짜 데이터의 해당 연·월·일의 7월 1일을 기준 (2016년 7월 1일 일 경우, 2017년으로 처리)IYYY,IYY,IY,I
ISO 8601에서 제정한 날짜 기준년도 포맷을 기준Q
각 분기의 두 번째 달의 16일 기준MONTH,MON,MM,RM
각 달의 16일 기준WW
해당 연도의 몇 주(1~53번째 주)를 기준IW
ISO 8601에서 제정한 날짜 기준 해당 연도의 주(week)를 기준W
해당 월의 주(1~5번째 주)를 기준DDD,DD,J
해당 일의 정오(12:00:00)를 기준DAY,DY,D
한주가 시작되는 날짜를 기준HH,HH12,HH24
해당일의 시간을 기준MI
해당일 시간의 분을 기준
ROUND
SELECT SYSDATE,
ROUND(SYSDATE, 'CC') AS FORMAT_CC,
ROUND(SYSDATE, 'YYYY') AS FORMAT_YYYY,
ROUND(SYSDATE, 'Q') AS FORMAT_Q,
ROUND(SYSDATE, 'DDD') AS FORMAT_DDD,
ROUND(SYSDATE, 'HH') AS FORMAT_HH
FROM DUAL;
TRUNC
SELECT SYSDATE,
TRUNC(SYSDATE, 'CC') AS FORMAT_CC,
TRUNC(SYSDATE, 'YYYY') AS FORMAT_YYYY,
TRUNC(SYSDATE, 'Q') AS FORMAT_Q,
TRUNC(SYSDATE, 'DDD') AS FORMAT_DDD,
TRUNC(SYSDATE, 'HH') AS FORMAT_HH
FROM DUAL;
06-5 (명시적) 형 변환 함수
TO_CHAR
날짜, 숫자 데이터를 문자 데이터로 변환해 주는 함수
- 원하는 출력 형태로 날짜 출력하기
TO_CHAR([날짜 데이터(필수)], '[출력되길 원하는 문자 형태(필수)]')CC: 세기YYYY,RRRR: 연(4자리 숫자)YY,RR: 연(2자리 숫자)MM: 월(2자리 숫자)MON: 월(언어별 월 이름 약자)MONTH: 월(언어별 월 이름 전체)DD: 일(2자리 숫자)DDD: 1년 중 며칠(1~365)DY: 요일(언어별 요일 이름 약자)DAY: 요일(언어별 요일 이름 전체)W: 1년 중 몇 번째 주(1~53)
SELECT TO_CHAR(SYSDATE, 'YYYY/MM/DD HH24:MI:SS') AS 현재날짜시간
FROM DUAL;| 현재날짜시간 |
|---|
| 2024/04/03 09:16:57 |
SELECT SYSDATE,
TO_CHAR(SYSDATE, 'MM') AS MM,
TO_CHAR(SYSDATE, 'MON') AS MON,
TO_CHAR(SYSDATE, 'MONTH') AS MONTH,
TO_CHAR(SYSDATE, 'DD') AS DD,
TO_CHAR(SYSDATE, 'DY') AS DY,
TO_CHAR(SYSDATE, 'DAY') AS DAY
FROM DUAL;| SYSDATE | MM | MON | MONTH | DD | DY |
|---|---|---|---|---|---|
| 24/04/03 | 04 | 4월 | 4월 | 03 | 수 |
- 특정 언어에 맞춰서 날짜 출력하기
TO_CHAR([날짜 데이터(필수)], '[출력되길 원하는 문자 형태(필수)]'),
'NLS_DATE_LANGUAGE = language`(선택))SELECT SYSDATE,
TO_CHAR(SYSDATE, 'MM') AS MM,
TO_CHAR(SYSDATE, 'MON', 'NLS_DATE_LANGUAGE = JAPANESE') AS MON_JPN,
TO_CHAR(SYSDATE, 'MON', 'NLS_DATE_LANGUAGE = ENGLISH') AS MON_ENG,
TO_CHAR(SYSDATE, 'MONTH', 'NLS_DATE_LANGUAGE = JAPANESE') AS MONTH_JPN,
TO_CHAR(SYSDATE, 'MONTH', 'NLS_DATE_LANGUAGE = ENGLISH') AS MONTH_ENG,
TO_CHAR(SYSDATE, 'DD') AS DD,
TO_CHAR(SYSDATE, 'DY', 'NLS_DATE_LANGUAGE = JAPANESE') AS DY_JPN,
TO_CHAR(SYSDATE, 'DY', 'NLS_DATE_LANGUAGE = ENGLISH') AS DY_ENG,
TO_CHAR(SYSDATE, 'DAY', 'NLS_DATE_LANGUAGE = JAPANESE') AS DAY_JPN,
TO_CHAR(SYSDATE, 'DAY', 'NLS_DATE_LANGUAGE = ENGLISH') AS DAY_ENG
FROM DUAL;| SYSDATE | MM | MON_JPN | MON_ENG | MONTH_JPN | MONTH_ENG | DD | DY_JPN | DY_ENG | DAY_JPN | DAY_ENG |
|---|---|---|---|---|---|---|---|---|---|---|
| 24/04/03 | 04 | 4月 | APR | 4月 | APRIL | 03 | 水 | WED | 水曜日 | WEDNESDAY |
- 시간 형식 지정하여 출력하기
HH24: 24시간으로 표현한 시간HH,HH12: 12시간으로 표현한 시간MI: 분SS: 초AM,PM,A.M.,P.M.: 오전, 오후 표시
SELECT SYSDATE,
TO_CHAR(SYSDATE, 'HH24:MI:SS') AS HH24MISS,
TO_CHAR(SYSDATE, 'HH24:MI:SS AM') AS HHMISS_AM,
TO_CHAR(SYSDATE, 'HH:MI:SS P.M.') AS HHMISS_PM
FROM DUAL;| SYSDATE | HH24MISS | HHMISS_AM | HHMISS_PM |
|---|---|---|---|
| 24/04/03 | 09:36:07 | 09:36:07 오전 | 09:36:07 오전 |
- 숫자 데이터 형식을 지정하여 출력하기
9: 숫자의 한 자리를 의미함(빈 자리를 채우지 않음)0: 빈 자리를 0으로 채움을 의미함$: 달러($) 표시를 붙여서 출력함L: L(Locale) 지역 화폐 단위 기호를 붙여서 출력함.: 소수점을 표시함,: 천 단위의 구분 기호를 표시함
SELECT SAL,
TO_CHAR(SAL, '$999,999') AS SAL_$,
TO_CHAR(SAL, 'L999,999') AS SAL_L,
TO_CHAR(SAL, '999,999.00') AS SAL_1,
TO_CHAR(SAL, '000,999,999.00') AS SAL_2,
TO_CHAR(SAL, '000999999.99') AS SAL_3,
TO_CHAR(SAL, '999,999,00') AS SAL_4
FROM EMP;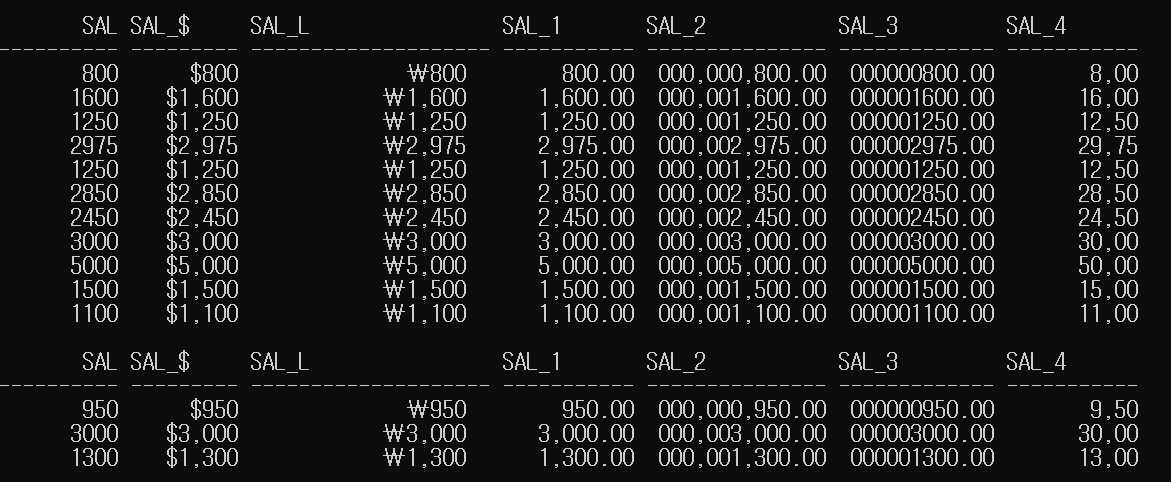
TO_NUMBER
문자열을 지정한 형태의 숫자로 인식하여 숫자 데이터로 변환
TO_NUMBER([문자열 데이터(필수)], '[인식될 숫자 형태(필수)]')SELECT TO_NUMBER('1,300', '999,999') - TO_NUMBER('1,500', '999,999')
FROM DUAL;| TO_NUMBER('1,300','999,999')-TO_NUMBER('1,500','999,999') |
|---|
| -200 |
TO_DATE
문자열 데이터를 날짜형 데이터로 변환
TO_DATE([문자열 데이터(필수)], '[인실될 날짜 형태(필수)]')- TO_DATE 함수로 문자 데이터를 날짜 데이터로 변환하기
SELECT TO_DATE('2018-07-14', 'YYYY-MM-DD') AS TODATE1,
TO_DATE('20180704', 'YYYY-MM-DD') AS TODATE2
FROM DUAL;| TODATE1 | TODATE2 |
|---|---|
| 18/07/14 | 18/07/04 |
- 1981년 6월 1일 이후에 입사한 사원 정보 출력하기
SELECT *
FROM EMP
WHERE HIREDATE > TO_DATE('1981/06/01', 'YYYY/MM/DD');
- 여러 가지 형식으로 날짜 데이터 출력하기
SELECT TO_DATE('49/12/10', 'YY/MM/DD') AS YY_YEAR_49,
TO_DATE('49/12/10', 'RR/MM/DD') AS RR_YEAR_49,
TO_DATE('50/12/10', 'YY/MM/DD') AS YY_YEAR_50,
TO_DATE('50/12/10', 'RR/MM/DD') AS RR_YEAR_50,
TO_DATE('51/12/10', 'YY/MM/DD') AS YY_YEAR_51,
TO_DATE('51/12/10', 'RR/MM/DD') AS RR_YEAR_51
FROM DUAL;| YY_YEAR_49 | RR_YEAR_49 | YY_YEAR_50 | RR_YEAR_50 | YY_YEAR_51 | RR_YEAR_51 |
|---|---|---|---|---|---|
| 2049/12/10 | 2049/12/10 | 2050/12/10 | 2050/12/10 | 2051/12/10 | 2051/12/10 |
06-6 NULL 처리 함수
NVL 함수의 기본 사용법
열 또는 데이터를 입력하여 해당 데이터가 NULL이 아닐 경우 데이터를 그대로 반환하고, NULL인 경우 지정한 데이터를 반환
NVL([NULL인지 여부를 검사할 데이터 또는 열(필수)],
[앞의 데이터가 NULL일 경우 반환할 데이터(필수)])SELECT EMPNO, ENAME, SAL, COMM, SAL+COMM,
NVL(COMM, 0),
SAL+NVL(COMM, 0)
FROM EMP;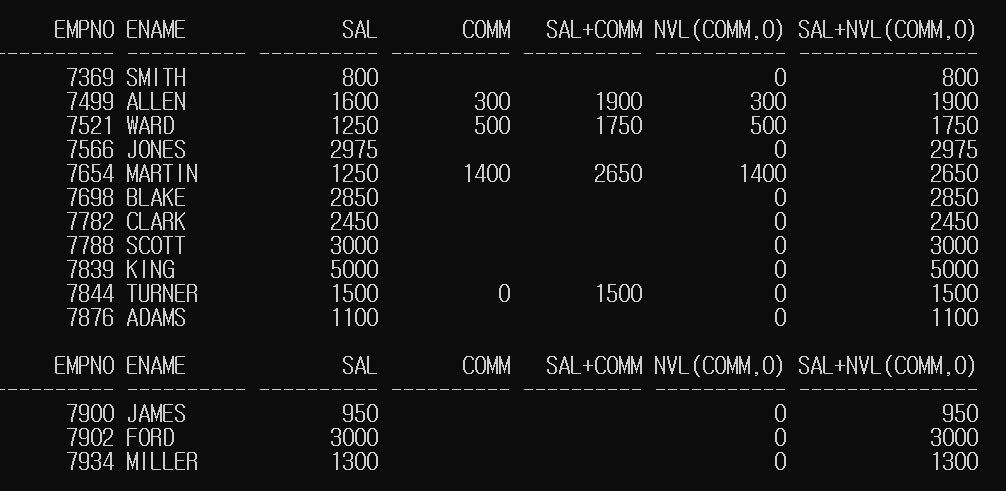
NVL2 함수의 기본 사용법
열 또는 데이터를 입력하여 해당 데이터가 NULL이 아닐 때와 NULL일 때 출력 데이터를 각각 지정
NVL([NULL인지 여부를 검사할 데이터 또는 열(필수)],
[앞 데이터가 NULL이 아닐 경우 반환할 데이터 또는 계산식(필수)],
[앞 데이터가 NULL일 경우 반환할 데이터 또는 계산식(필수)])SELECT EMPNO, ENAME, COMM,
NVL2(COMM, 'O', 'X'),
NVL2(COMM, SAL*12+COMM, SAL*12) AS ANNSAL
FROM EMP;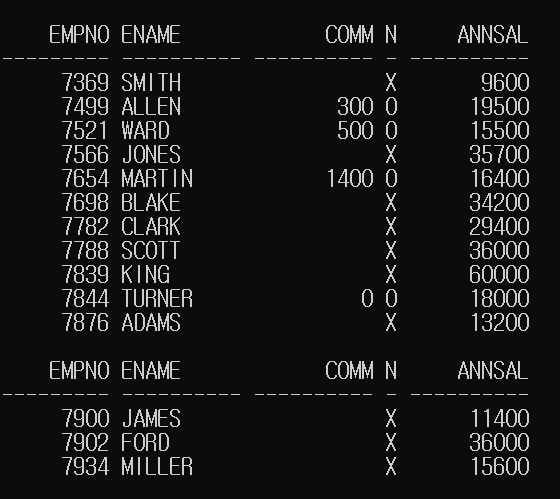
06-7 DECODE 함수와 CASE문
DECODE
특정 열 값이나 데이터 값에 따라 어떤 데이터를 반환할지 정할 수 있음
DECODE([검사 대상이 될 열 또는 데이터, 연산이나 함수의 결과],
[조건1], [데이터가 조건1과 일치할 때 반환할 결과],
[조건2], [데이터가 조건2와 일치할 때 반환할 결과],
...
[조건n], [데이터가 조건n과 일치할 때 반환할 결과],
[위 조건1~조건n과 일치한 경우가 없을 때 반환할 결과])SELECT EMPNO, ENAME, JOB, SAL,
DECODE(JOB,
'MANAGER', SAL*1.1,
'SALESMANE', SAL*1.05,
'ANALYST', SAL,
SAL*1.03) AS UPSAL
FROM EMP;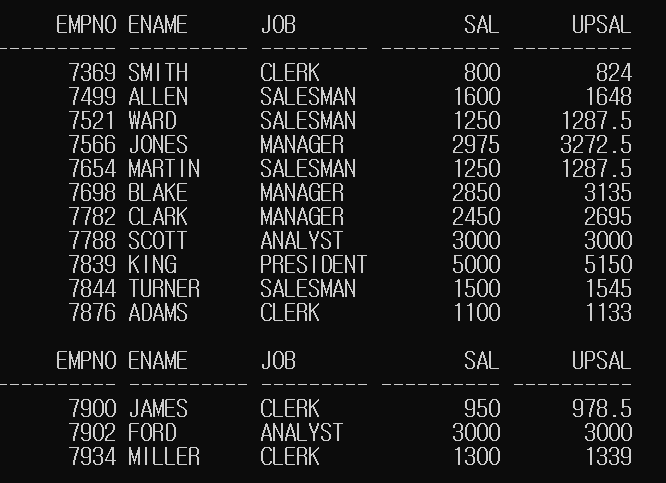
CASE
CASE [검사 대상이 될 열 또는 데이터, 연산이나 함수의 결과(선택)]
WHEN [조건1] THEN [조건1의 결과 값이 true일 때, 반환할 결과]
WHEN [조건2] THEN [조건2의 결과 값이 true일 때, 반환할 결과]
...
WHEN [조건n] THEN [조건n의 결과 값이 true일 때, 반환할 결과]
ELSE [위 조건1~조건n과 일치하는 경우가 없을 때 반환할 결과]- 기준 데이터가 있을 때
SELECT EMPNO, ENAME, JOB, SAL,
CASE JOB
WHEN 'MANAGER' THEN SAL*1.1
WHEN 'SALESMAN' THEN SAL*1.05
WHEN 'ANALYST' THEN SAL
ELSE SAL*1.03
END AS UPSAL
FROM EMP;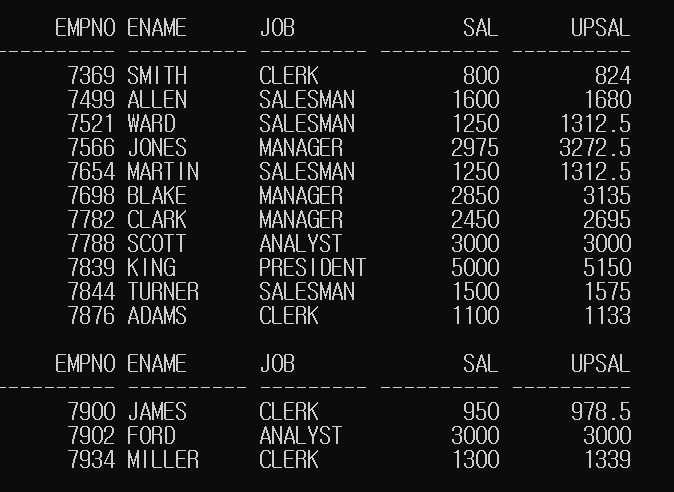
- 기준 데이터가 없을 때
SELECT EMPNO, ENAME, COMM,
CASE
WHEN COMM IS NULL THEN '해당사항 없음'
WHEN COMM = 0 THEN '수당 없음'
WHEN COMM > 0 THEN ' 수당 : ' || COMM
END AS COMM__TEXT
FROM EMP;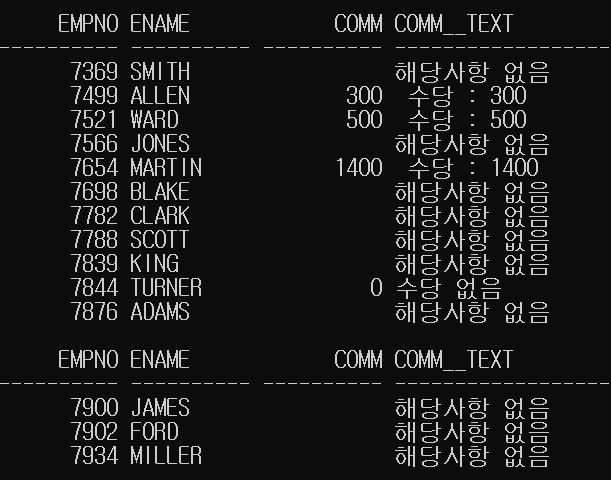

열심히 살겠습니다