인프런 강의 자료를 기반으로 정리한 딥러닝 컴퓨터 비전 공부 내용을 정리한 내용입니다.
Localization, detection, segmentation의 차이

- classification: 딥러닝 기법을 사용하여 주어진 입력 데이터가 어떤 클래스에 속하는지 분류하는 기술
- localization: 하나의 이미지 안에 단 하나의 object위치를 bounding box로 찾는 것.
- detection: 하나의 이미지 안에 여러 개의 object(bounding box)가 있고, 각각을 detect하는 것입니다.
- segmentation: 하나의 이미지에 여러개의 object를 pixel값으로 detect하는 것.
-> 즉, localization, detection, segmentation은 object의 위치를 찾아낸다는 특징이 있다.
-> localization, detection은 bounding box를 사용하여, 내부 object를 판별한다. 따라서 bounding box regression(box의 좌표값을 예측), classification 두개의 문제를 판별해야 한다.
obejct detection history
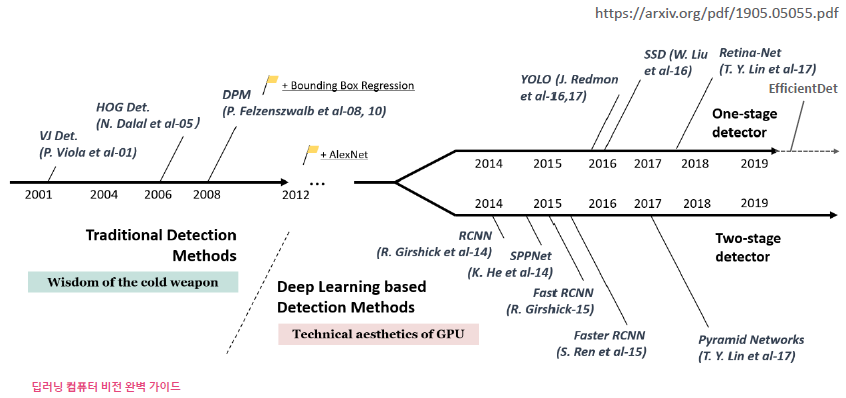
2014년에 RCNN이 처음 소개되면서, 객체 검출에서 two-stage detector 방식이 대두되었다. 이 방식은 객체가 있을 만한 위치를 먼저 찾아놓고, 그 위치에서 객체를 검출하는 방식으로, 매우 뛰어난 성능을 보여주지만, 그만큼 연산 시간이 많이 소요되어 실시간 적용에는 어려움이 있다. 이후, RCNN 시리즈 및 Pyramid Networks 등의 모델을 통해 two-stage detector의 성능과 수행 시간이 개선되고 있다.
one-stage detector의 대표적인 기법인 YOLO version 1이 2015년에 소개되었으나, 수행 시간에 집중한 나머지 성능이 좋지 않았다. 이후, SSD가 one-stage detector로서 개선된 성능과 수행 시간을 보여주었으며, RetinaNet, EfficientDet 및 YOLO 버전 시리즈 등을 통해 향상된 예측 성능과 우수한 수행 시간을 가진 모델이 소개되었다.
Object detection의 주요 구성 요소

-
Region Proposal
: 입력 이미지에서 Object가 있을 만한 위치를 찾아내는 과정이다. -
Detection을 위한 Deep learning 네트워크 구성
: 일반적으로 pretrained 딥러닝 모델을 사용하여 Feature Extraction(학습 이미지의 특징 추출)을 한다. 이 과정을 backbone과정이라고 한다.
Feature Pyramid Network (FPN)은 입력 이미지에서 Object Proposal을 생성하기 위해 여러 단계의 Feature Maps를 생성하는 모듈이며, 이 과정을 neck이라고 한다. 이 모듈은 Backbone으로부터 전달된 Feature Maps를 가지고, Object Proposal과 Classification, Localization을 위한 정보를 추출한다. -
Network Prediction
: Neck에서 생성된 Feature Maps를 입력으로 받아, Object Detection의 최종 결과를 출력하는 모듈로 head라고 불린다. head는 크게 classification head와 regression head의 두가지 구성 요소로 나눌 수 있다. Classification Head는 Neck에서 생성된 Feature Maps를 입력으로 받아, 각각의 Object Proposal이 어떤 클래스에 속하는지를 분류하는 모듈이다. Regression Head는 Neck에서 생성된 Feature Maps와 Classification Head를 통해 판별된 클래스 정보를 입력으로 받아, 각 Object Proposal의 Bounding Box를 정확하게 조정하는 모듈이다. -
Detection을 구성하는 기타 요소
IOU (Intersection over Union): Object Detection에서 사용되는 두 개의 Bounding Box가 얼마나 겹치는지를 측정하는 지표.
NMS (Non-Maximum Suppression):Object Detection에서 사용되는 post-processing 기법 중 하나. 같은 Object를 검출하는 여러 개의 Bounding Box 중에서 가장 확률이 높은 Box만을 선택하고, 나머지 Box는 제거하는 기법
mAP(Mean Average Precision): Object Detection 모델의 정확도를 평가하는 지표. Precision과 Recall의 조합으로 계산되며, 모든 클래스에 대해 평균적으로 산출
Anchor box: Anchor Box는 Object Detection에서 사용되는 기법 중 하나. Anchor Box는 입력 이미지 상에서 Object가 있을 가능성이 있는 위치를 미리 정의한 사각형을 말한다.
object detection의 난제
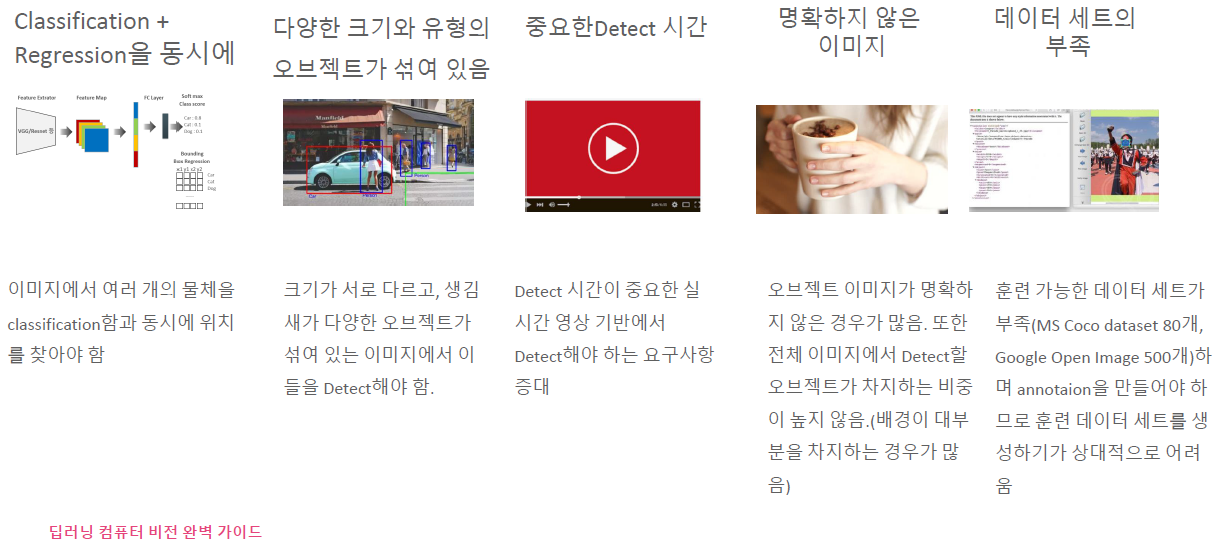
-
classification과 regression을 동시에 해야하므로, loss함수가 두가지를 모두 줄이도록 최적화된 함수를 적용해야 된다.
-
다양한 크기와 유형의 오브젝트가 섞여있다. 일반적으로 딥러닝이서는 input 이미지의 크기가 같으나, object detection에서는 다르다.
-
중요한 detect 시간: 실시간 영상 기반에서 detect시간이 중요해지지만, 정확도 성능을 올리려면 많은 연산이 필요하므로 성능과 trade-off관계에 있다.
