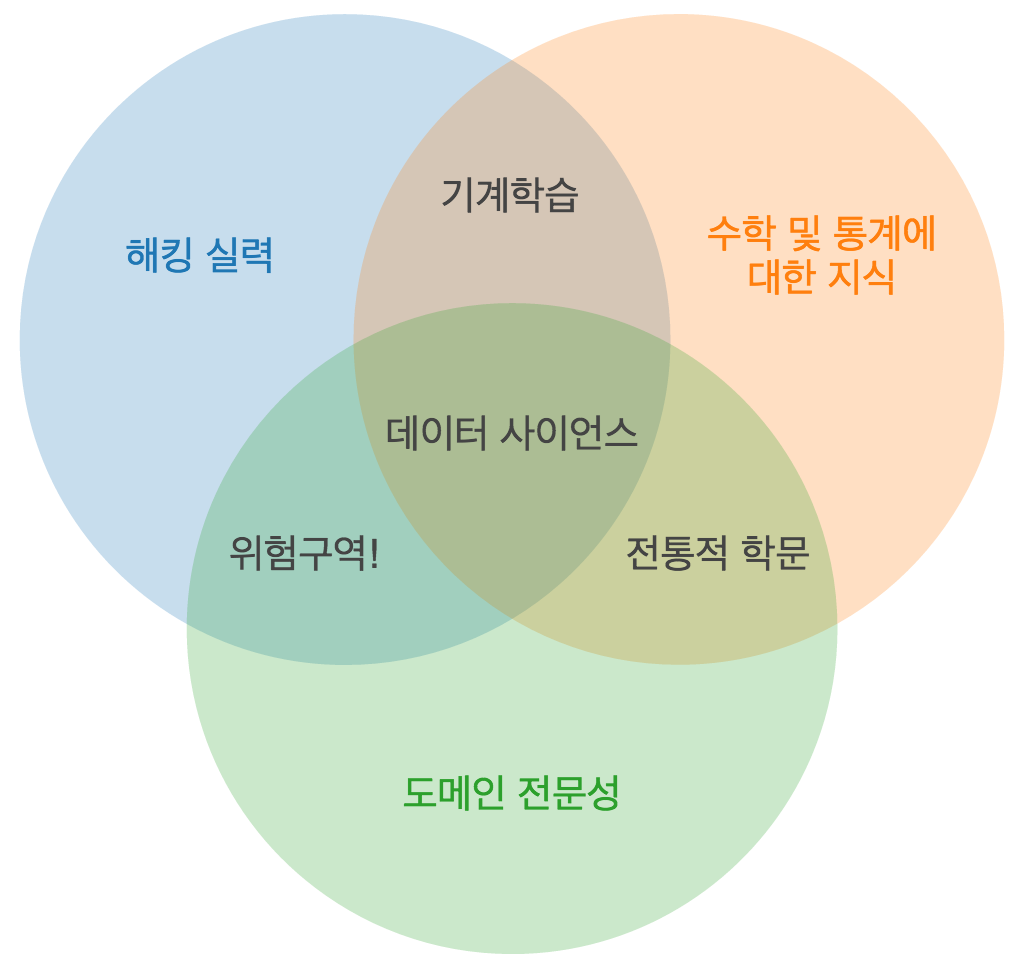
1. 데이터 사이언스
- 다양한 데이터로부터 새로운 지식과 정보를 추출하기 위해 과학적 방법론, 프로세스, 알고리즘, 시스템을 동원하는 융합 분야
- 컴퓨터 과학, 통계학, 수학 등 다양한 학문의 원리와 기술을 활용
[출처]https://kun-hee.tistory.com/103
1. 데이터 사이언스 프로세스
-
문제 정의 : 해결하고자 하는 문제 정의
-
데이터 수집 : 문제 해결에 필요한 데이터 수집
- 웹스크래핑(Web Scraping) : 웹 페이지에서 데이터를 추출하는 기술
- 웹 크롤링(Web Crawling) : 웹 페이지를 자동으로 탐색하고 데이터를 수집하는 기술
- Open API 활용 : 공개된 API를 통해 데이터를 수집
- 데이터 공유 플랫폼 활용 : 다양한 사용자가 데이터를 공유하고 활용할 수 있는 온라인 플랫폼
-
데이터 전처리(정제) : 실질적인 분석을 수행하기 위해 데이터를 가공하는 단계
- 수집한 데이터의 오류제거(결측치, 이상치), 데이터 형식 변환 등
-불완전하거나 오류가 있는 데이터를 제거하여 데이터의 품질을 개선 - 중복데이터 제거
- 분석하기 적절한 형식으로 데이터를 변환
- 패키지 : Numpy, Pandas, Matplotlib
- 수집한 데이터의 오류제거(결측치, 이상치), 데이터 형식 변환 등
-
데이터 분석 : 전처리가 완료된 데이터에서 필요한 정보를 추출하는 단계
-
결과 해석 및 공유 : 의사 결정에 활용하기 위해 결과를 해석하고 시각화 후 공유하는 단계
2. CSV 란?
- 몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일
- 일반적으로 표 형식의 데이터를 CSV 형태로 많이 사용
- 저장, 전송 및 처리 속도가 빠르며, 처리 가능한 프로그램이 다양
3. Numpy
- 다차원 배열을쉽게 처리하고 효율적으로 사용할 수 있도록 지원하는 파이썬 패키지
- 장점
- Numpy 행렬 연산은 데이터가 많을수록 Python 반복문에 비해 훨씬 빠르다.
- 다차원 해렬 자료 구졸르 제공하여 개발하기 편하다.
- 특징
- CPython에서만 사용 가능
- 행렬 인덱싱 기능 제공
4. Pandas
- Numpy의 한계
- 유연성(데이터에 레이블을 붙이거나, 누락된 데이터로 작업)이 부족함
- 그룹화, 피벗 등 구조화가 부족함
- Pandas는 마치 프로그래밍 버전의 엑셀을 다루듯 고성능의 데이터 구조를 만들 수 있음
- Numpy 기반으로 만들어진 패키지로, Series(1차원 배열)과 DataFrame(2차원 배열)이라는 효율적인 자료구조 제공
5. Matplotlib
- Python에서 데이터 시각화를 위해 가장 널리 사용되는 라이브러리
- 다양한 종류의 그래프와 도표를 생성하고 데이터를 시각적으로 표현할 수 있습니다.

데이터 분석에서 백엔드까지...