Cache는 왜 필요할까?
웹 서버 부하 완화 및 웹 페이지 로드 성능 개선
발 퀄..
만약 서울에서 뉴욕에 존재하는 변하지 않는 똑같은 데이터를 웹 서버에서 받아온다고 했을 때, CDN을 사용 하지 않고 가져온다고 하면 얼마나 긴 시간이 걸릴까?
그리고 굳이 이 데이터는 변하지 않는데 서버에서 DB를 통해 가져와야할까?
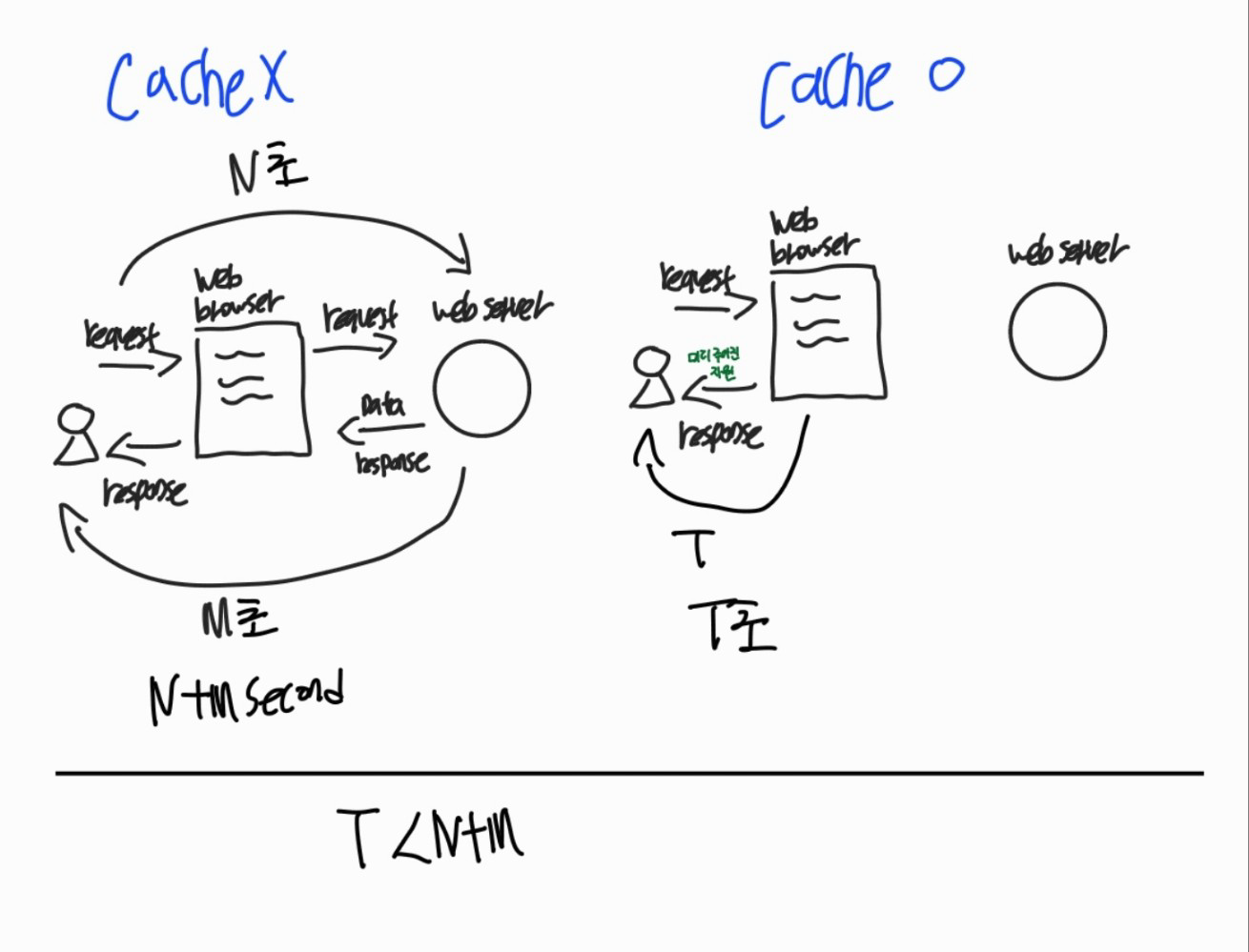
Cache를 사용하지 않는다면 서울에서 뉴욕에 있는 웹 서버까지 요청하는 시간 N초 + 뉴욕에서 서울로 데이터를 반환하는 시간 M초 즉 N+M초가 걸릴 것이다.
Cache를 사용하여 Web Browser에 해당 데이터를 저장해놓는다면, 사용자가 웹 브라우저에게 요청하고 받아오는 시간 T초만 걸릴 것이다.
장점
- N+M초보다 T초는 당연히 빠를 것이다.
- 네트워크를 사용하지 않는다.
- 서버 자원도 활용하지 않는다.
웹서버 측면
- 반복 : 웹 서버는 매번 똑같은 100MB 짜리 고양이 영상을 만들어서 웹 브라우저에게 만들어준다.
- 반복적인 서버자원(CPU, Memory) 소비 문제 = 모든 유저의 요청에 대한 반복 연산
- 이전에 만들어놓았던 100MB 짜리 고양이 영상을 재사용한다면?
- 서버자원(CPU, Memory) 여유 = 반복되는 모든 유저의 요청 간단히 처리 가능
- 불특정 다수의 웹 브라우저에게도 캐시된 자원 제공 가능
- 웹 브라우저 캐시는 웹 브라우저 유저만 캐시된 자원을 활용할 수 있었음
HTTP Cache 종류
역시나 발퀄..
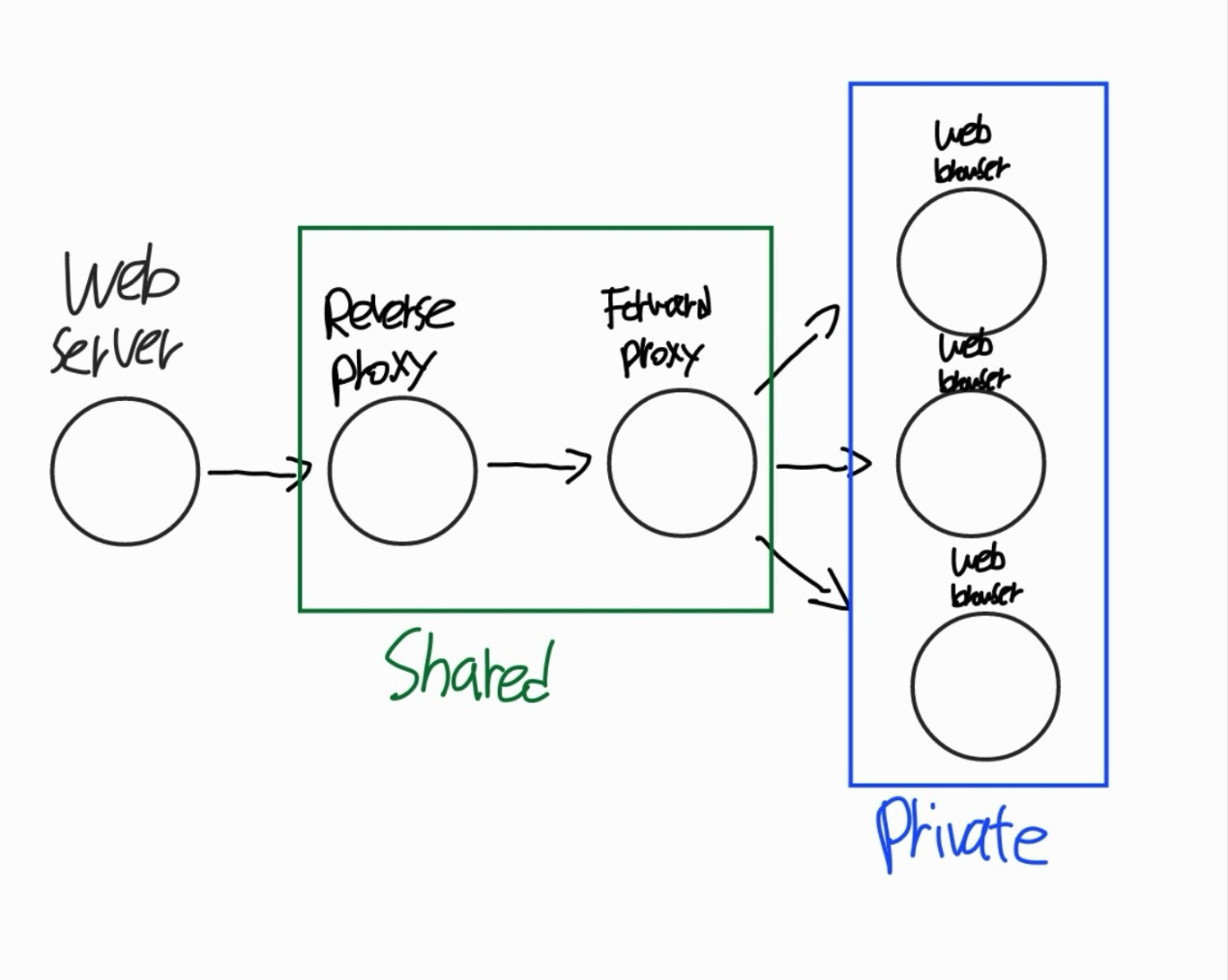
1. Shared: 임시 중간 저장소가 웹 브라우저와 웹 서버 사이에 있다면, 모든 웹 브라우저 유저 다수를 위한 것
- 당근에서 천안시 신부동에 있는 사람들의 커뮤니티 데이터는 Shared에 저장하지 않을까?
2. Private: 임시 중간 저장소가 웹 브라우저에 있다면, 유저 한명만을 위한 것
- 당근에서 로그인 데이터는 각 유저마다 Web Browser에 Private에 저장하지 않을까?
HTTP Cache 동작 원리
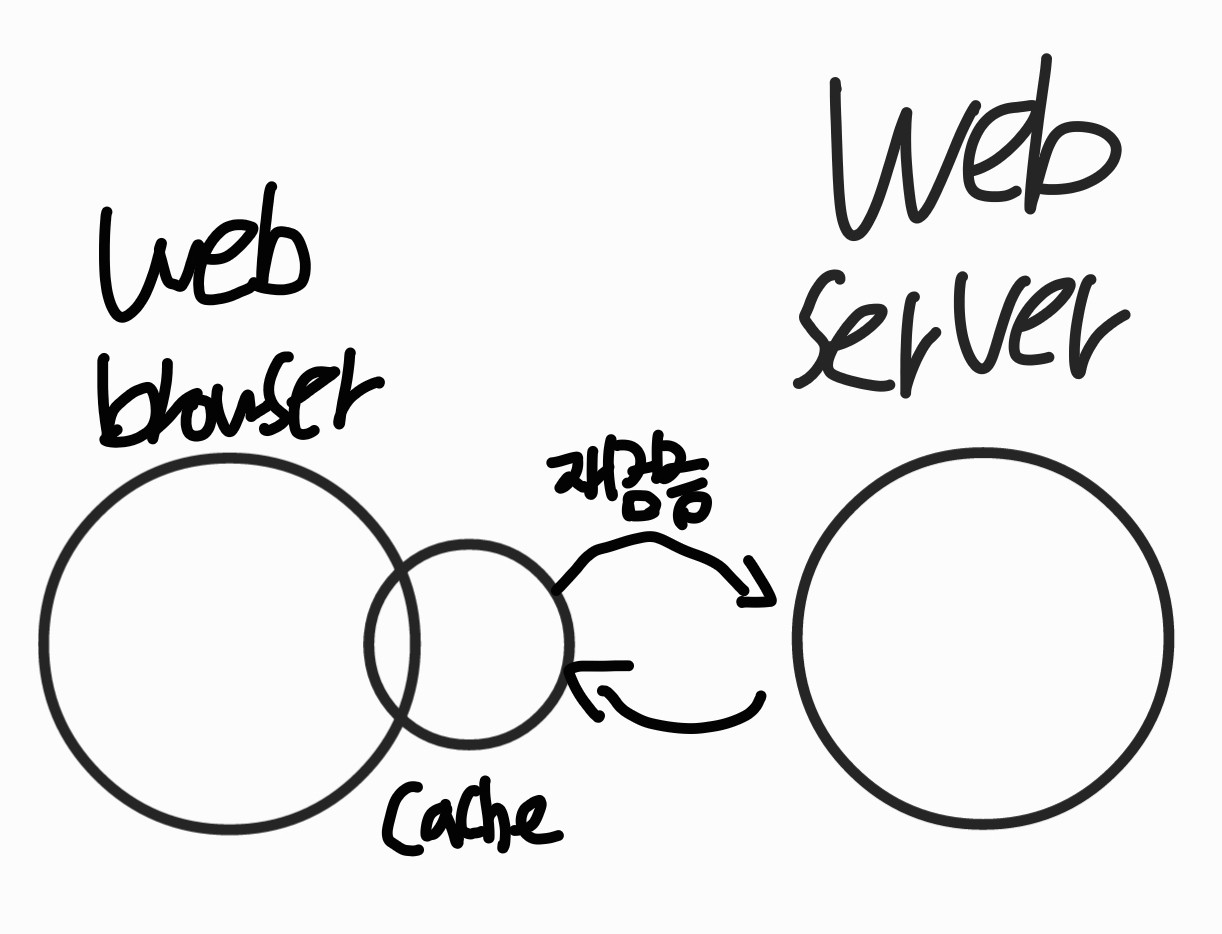
캐시는 준실시간성을 보장해야한다.
- 준실시간: 특정 주기나 기준에 따라 재검증을 해주어야한다.
- 재검증: 웹 서버가 특정한 주기나 기준에 따라 캐시한 데이터가 오래됐는지 검증
- 재검증 주기: 얼마 간격으로 재검증할지 웹서버에서 결정한다.
- 자주 바뀌는 데이터인지, 자주 안바뀌는 데이터인지 결정한다.
- 재검증 기준: 캐시해놓은 데이터가 오래됐는지 여부를 원본 주인인 웹서버가 판단 기준
- 수정일: Last-Modified
- 고유값: ETag ex)Hash-based
- 재검증 주기: 얼마 간격으로 재검증할지 웹서버에서 결정한다.

FE