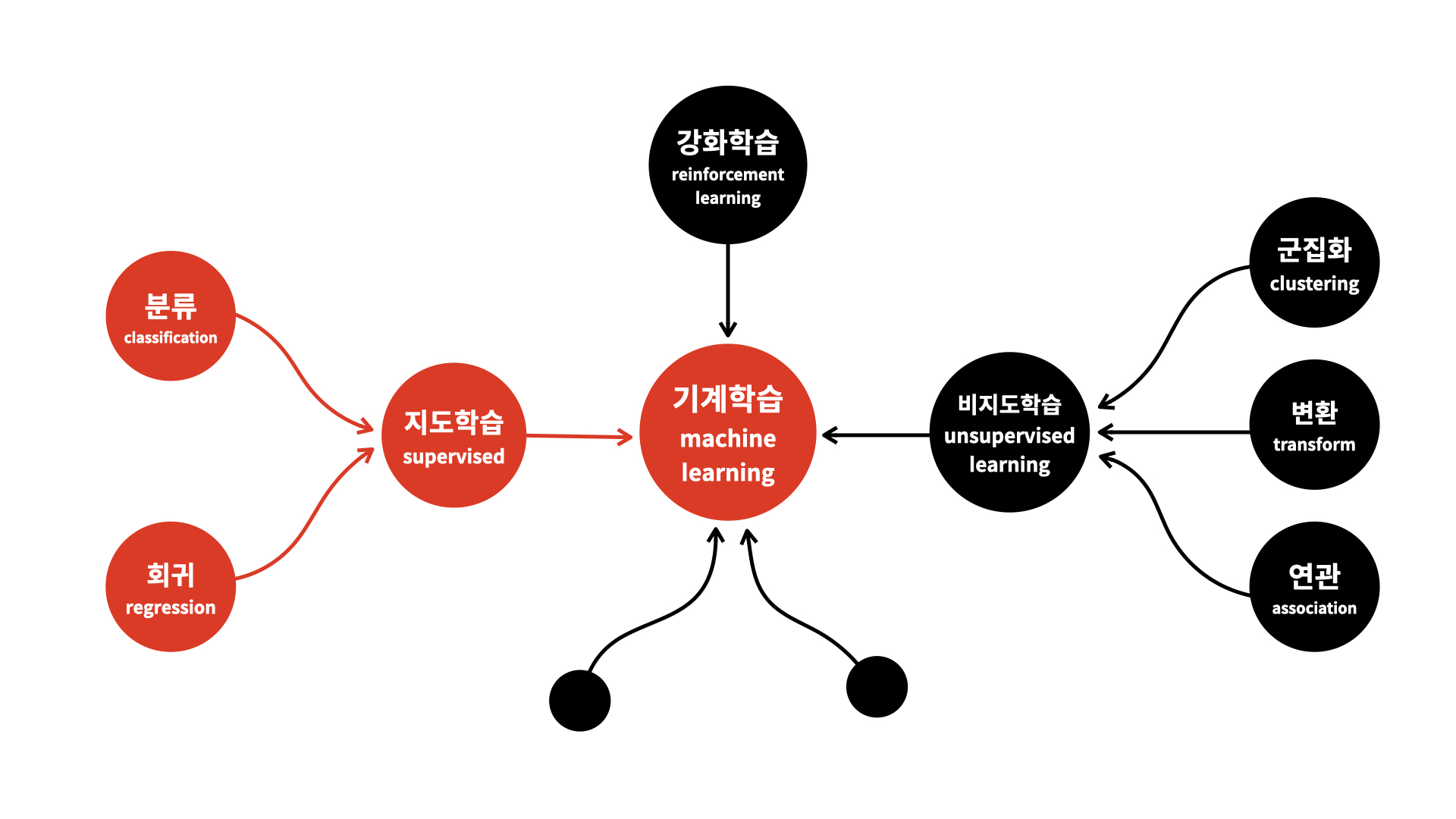
머신러닝
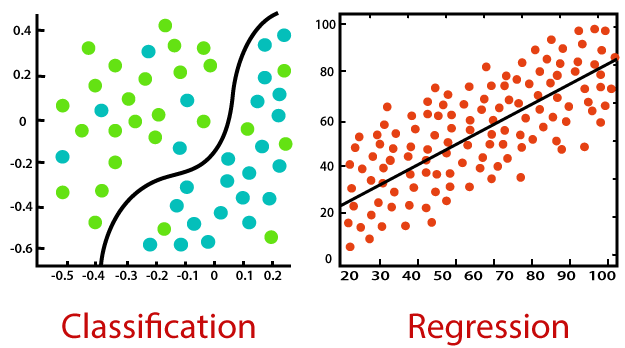
지도 학습의 양대산맥인 분류(Classification)와 회귀(Regression)에 대해 이야기 해보려고 한다.
지도 학습
머신러닝 알고리즘은 크게 지도 학습(supervised learning)과 비지도 학습(unsupervised learning), 강화 학습(Reinforcement learning)으로 나눌 수 있다.
지도 학습은 데이터(입력)와 정답(타깃)을 가지고 모델이 정답을 맞힐 수 있도록 훈련하는 것인데, 훈련을 위해서는 입력 값과 타깃 값이 반드시 필요하다.
회귀(Regression)와 분류(Classification)는 데이터의 타입이 numerical(연속형)이냐, categorical(범주형)이냐에 따라 달라진다.
또한 종속변수와 독립변수가 사용되는데 개념을 설명하자면,
- 독립 변수: 다른 변수에 영향을 미치는 변수
- 종속 변수: 다른 변수들에 영향을 받는 변수
아래의 예시를 통해 이해해보자!
Classification (분류)
입력 데이터를 미리 정의된 여러 개의 클래스(class) 중 하나로 분류하는 것
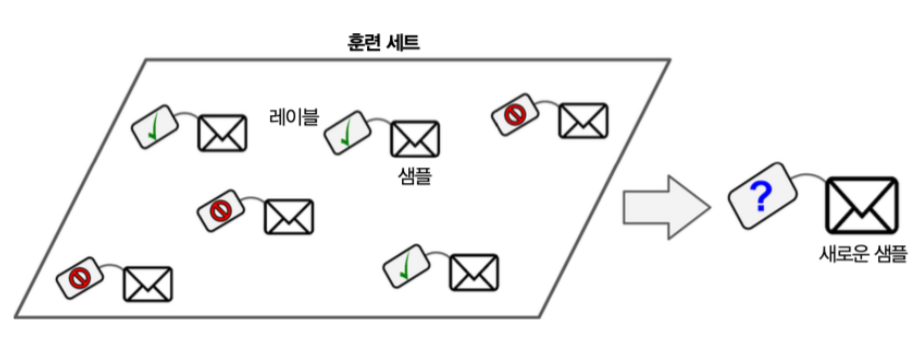
문자를 스팸으로 구분하는 것을 예시로 들 수 있다. 여러 가지 메일과 발송 기관 등을 샘플로 훈련하여 스팸메일인지 아닌지를 분류할 수 있도록 훈련되어야 한다.
- 독립변수: 메일 발신일, 발송 기관
- 종속변수: 스팸 메일 여부
- 훈련 데이터: 메일 구분
스팸 메일 분류, 손글씨 숫자 인식, 질병 진단 등 주어진 입력 데이터를 이산적인 카테고리(범주형)로 분류하기 위해 사용된다.
분류 알고리즘
- 로지스틱 회귀(Logistic Regression)
- 나이브 베이즈(Naive Bayes)
- 결정 트리(Decision Tree)
- 서포트 벡터 머신(Support Vector Machine)
- K-최소 근접(K-Nearest Neighbor) 알고리즘
- 심층 신경망(Deep Neural Network)
- 앙상블 학습(Ensemble Learning)
Regression (회귀)
입력 데이터와 연속적인 출력 변수 간의 관계를 모델링하는 것
특성을 사용하여 타깃의 수치를 예측하는 방법이다.
학생들의 나이에 따른 키의 기록을 예로 들 수 있다.
- 독립변수: 나이
- 종속변수: 키
- 훈련 데이터: 학생들의 나이에 따른 키 기록
학생들의 키 예측, 주택 가격 예측, 판매량 예측, 온도 예측 등 연속적인 값을 예측하는 경우에 회귀를 사용한다.
회귀 알고리즘
- 단순 선형 회귀(Simple Linear Regression)
- 경사 하강법(Gradient Descent)
- 다항 회귀(Polynomial Regression)
- 규제 모델(Regularization)
- 릿지 회귀(Ridege Regression)- 라쏘 회귀(Lasso Regression)
- 엘라스틱넷 회귀(Elastic Net Regression)
- 회귀 트리(Regression Tree)
