reference: 프로그래머가 몰랐던 멀티코어 CPU 이야기 / 김민장 / Blog2Book
병렬 프로그래밍에서 대표적인 성능 저하 문제 중 하나는 거짓 공유(false sharing) 문제이다.
거짓 공유
실제로 쓰레드 간 공유되지 않은 데이터이지만 캐시 구조의 특성으로 마치 공유되는 것으로 인식되어 불필요한 성능 저하 현상이 있어나는 것이다.
즉 각 소켓(프로세서) 또는 코어가 동일한 캐시 라인 내의 서로 다른 위치의 데이터를 지역 캐시를 통해 참조할 때 거짓 공유가 발생한다. 실제 같은 데이터를 참조하지 않은 상황에도 불구하고 캐시 일관성 유지 프로토콜 통신(버스 트래픽)과 공유 캐시, 메모리로의 write-back으로 인한 오버헤드가 발생한다.
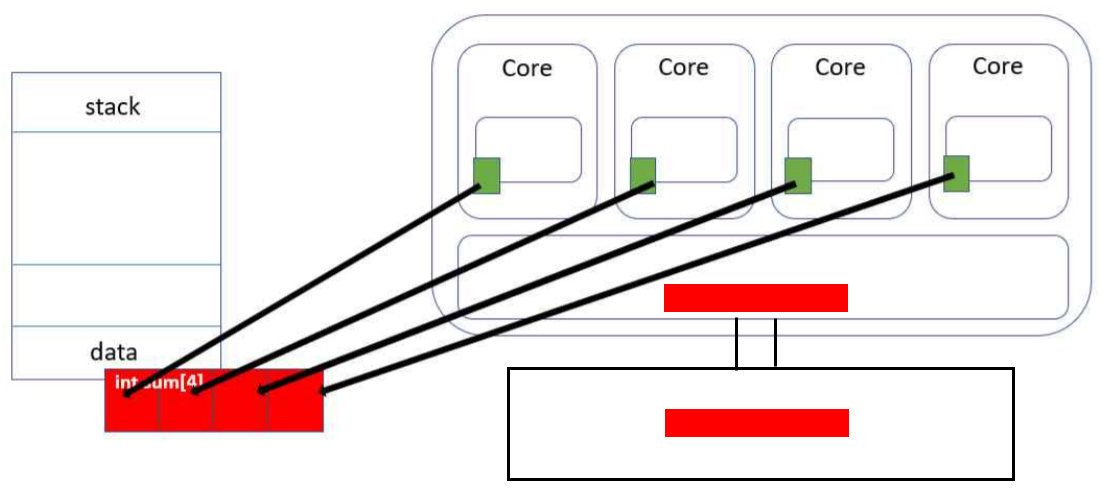
예제 코드
#include <iostream>
#include <thread> // for 멀티 쓰레드 프로그래밍
#include <chrono> // for 시간 측정
using namespace std;
using int64 = long long int;
constexpr int64 NUMBERS = 1000000000LL;
volatile int64 num1 = 0;
volatile int64 num2 = 0;
void job1() {
for (int64 i=0; i<NUMBERS; ++i) {
num1 += 1LL;
}
}
void job2() {
for (int64 i=0; i<NUMBERS; ++i) {
num2 += 1LL;
}
}
int main() {
auto beginTime = chrono::high_resolution_clock::now();
std::thread task1(job1);
std::thread task2(job2);
task1.join();
task2.join();
auto endTime = chrono::high_resolution_clock::now();
chrono::duration<double> elapsedTime = endTime - beginTime;
cout << "num1: " << num1 << endl;
cout << "num2: " << num2 << endl;
cout << elapsedTime.count() << "s" << endl; return 0;
}
// 출처: https://neurowhai.tistory.com/249 [NeuroWhAI의 잡블로그](실행 결과)
num1: 1000000000
num2: 1000000000
8.41568s
두 개의 쓰레드를 생성하고 각각 병렬적으로 각 변수에 1씩 더해가는 코드이다. 직접적으로 공유하는 데이터가 없기에 Mutex가 필요없는 완벽한 병렬성을 가지는 코드이다. 따라서 예상되는 결과를 출력하였다. 실행시간은 8초정도가 소모되었다.
이 코드의 volatile 변수의 메모리상에 정렬(배치) 방식을 64바이트 단위로 만들어보면 다음과 같다.
..
..
constexpr int CACHE_LINE_SIZE = 64; // 캐시 라인 사이즈: 64B
constexpr int64 NUMBERS = 1000000000LL;
alignas(CACHE_LINE_SIZE)volatile int64 num1 = 0;
alignas(CACHE_LINE_SIZE)volatile int64 num2 = 0;
..
..(실행 결과)
num1: 1000000000
num2: 1000000000
2.98771s
실행 속도가 확실히 빨라졌다.
volatile 변수?
valatile로 변수를 선언하면 컴파일러는 해당 변수를 최적화에서 제외하여 항상 메모리 접근을 하도록 만든다.
보통 컴파일러는 최적화를 하여 변동이 없는 변수에 그냥 상수를 할당한다. 예를 들어 gcc의 -o3 옵션 같은 경우가 그렇다.
위와 같은 코드에서 컴파일러의 최적화를 거치면 그냥 i값에 10을 할당해버린다.


패딩 공간이 생김에 따라 성능이 어떻게 좋아질 수 있었을까?
거짓 공유 발생 이유
프로그램에서 task1을 수행하는 1번 쓰레드가 num1을 갱신하고, 2번 쓰레드가 num2를 갱신한다. 그리고 쓰레드가 동작하는 각 코어는 각자의 전용 L1 캐시를 가진다.
캐시는 읽고 쓰는 단위가 4바이트 같은 작은 단위가 아니라 64바이트 같은 캐시 라인 크기만큼 한꺼번에 처리된다. 이 프로그램에서 num1과 num2는 바로 연이어 선언되었기에 컴파일러가 인접한 주소에 놓는 것이 일반적이다. 이에 따라 인접한 주소에 있는 두 변수는 각 코어의 L1 캐시의 같은 라인에 놓일 확률이 매우 놓다.
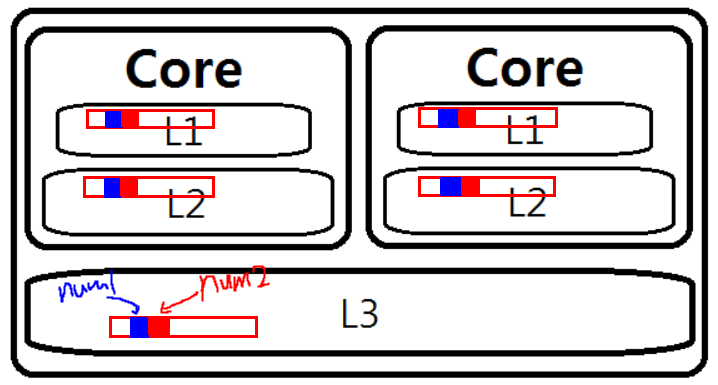
문제는 캐시 일관성(cache coherence)에 있다. 멀티코어에서 캐시는 모든 코어가 항상 최신 내용을 볼 수 있도록 처리한다. 그리고 이는 캐시 일관성 프로토콜(MSI, MESI, MOESI)을 통해 실현된다. 어떤 코어가 한 캐시 라인을 쓰려면 다른 코어가 가진 사본을 모두 무효화시키는 신호을 보낸다. 이것이 바로 거짓 공유의 근본 원인이다. num1, num2는 논리적으로는 전혀 공유가 되지 않고, 물리적으로 같은 캐시 라인에 놓여 있다. 그런데 1번 쓰레드가 num1을 갱신하면 다른 코어가 가지고 있을지도 모르는 이 캐시 라인을 무효화시켜야 한다. 2번 쓰레드의 수행에서도 마찬가지이다. 이러한 방식으로 끊임없이 서로의 캐시 라인을 무효화하고 그에 따라 캐시 미스가 게속 발생하고 만다. 이는 결국 성능 문제로 이어진다.
거짓 공유는 경우에 따라 아주 심각한 성능 문제를 일으킬 수 있다. 특히 과거 공유 캐시(ex, L3)가 없는 멀티코어는 성능 저하가 매우 심했다. L1, L2 캐시가 모두 전용 캐시라면 상대방의 L1, L2 캐시 라인을 모두 없애고, 그 결과 캐시 라인을 읽는 캐시는 최악에는 메모리에서 데이터를 가져 와야 한다. 최근의 멀티코어는 마지막 레벨 캐시가 공유되므로 피해가 상대적으로 적다.
괴거 멀티코어가 아닌 멀티프로세서(멀티소켓) 환경에서 거짓 공유가 일어날을 때도 문제가 마찬가지로 심각했다.
캐시 일관성 프로토콜이 멀티 레벨 캐시에서 어떻게 작동하는지 정확히 알아야 좋지만, 이 책에선 이 설명까지 하지 않는다.
실제로 거짓 공유로 인한 성능 손실이 얼마나 되는지 관찰할 수 있는 실험을 책에서 소개하였다.
위와 비슷한 소스(C언어)를 인텔 Core i7 920 CPU(쿼드코어+하이퍼쓰레딩, L3 공유 캐시)에서 컴파일러 최적화 후 그 속도를 비교해 보았다. 거짓 공유 여부로 25% 정도의 성능 차이를 보였다. 논리적인 잘못은 아무것도 없지만 이런 멀티코어의 캐시 때문에, 물론 극단적으로 과장된 코드지만, 성능이 25% 이상 차이난다는 것은 놀라운 일이다. 과거 Pentium D 같은 공유캐시가 없는 구조는 200% 이상 차이가 날 수도 있다 한다.
위 코드에선 num1, num2 변수를 전역에 선언하였다. 전역 선언 뿐 아니라 malloc이나 new와 같은 동적 할당에서도 일어날 수 있다(힙 영역 또한 쓰레드들은 공유하기에). gcc나 visual c++의 기본 힙 할당자는 멀티쓰레드 환경에 최적화되어 있지 않다. 따라서 멀티쓰레드 환경에서는 이 문제를 고려한 힙 할당자를 쓰는 것이 좋다. 이 문제를 해결한 할당자가 몇 개 소개되어있다. 대표적으로 쓰레드 빌딩 블록(TBB) 라이브러리의 tbbmalloc과 HOARD라는 메모리 할당자가 있다.
멀티쓰레드 환경에서도 성능이 저하되지 않는 확장성(scalability)을 가지는 메모리 할당자는 고성능 멀티쓰레드 프로그램의 필수 조건이다.
