reference: 프로그래머가 몰랐던 멀티코어 CPU 이야기 / 김민장 / Blog2Book
멀티코어에서 캐시는 각 코어가 쓰는 전용 캐시(private cache)와 여러 코어가 공유하는 공유 캐시(shared cache)가 있다. 각 코어에는 명령어 및 데이터 1차 레벨 캐시가 독립적으로 들어있다. 그리고 L2 캐시 역시 독립 캐시로 구성되어 있다. 그러나 L3 캐시는 일반적으로 모든 코어가 공유하도록 설계되어 있다.
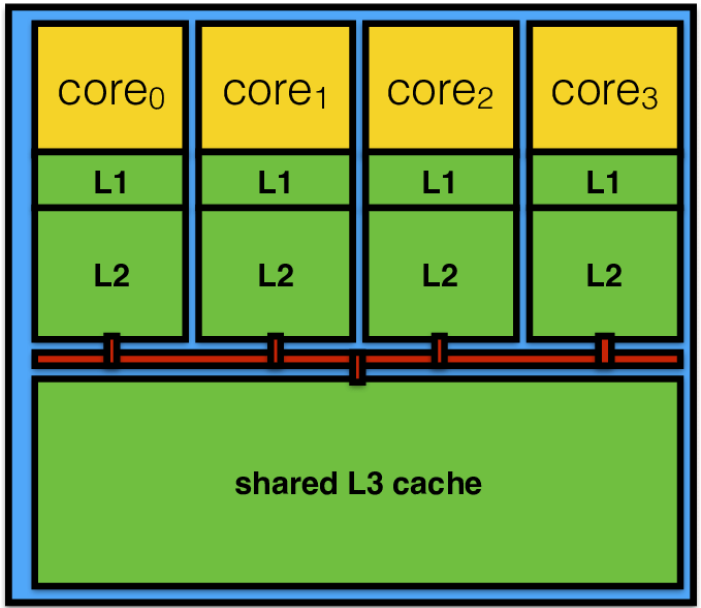
업체마다 구체적인 캐시 정책은 다르다.
캐시 일관성(cache coherency) 문제
멀티코어에는 캐시가 여러 곳에 있어서 문제가 하나 발생하는데, 바로 캐시에 저장된 데이터 사이의 일관성 유지 문제이다. 이른바 캐시 일관성 문제이다. 멀티코어 캐시에서 풀어야 하는 가장 기본적인 문제이다. 최적화만 고려하지 않는다면 캐시 존재 여부를 잊고서도 프로그래밍 할 수 있다. 그러나 캐시 일관성이 없다면 프로그래머가 직접 명시적으로 캐시를 관리해야 하는 어려움이 있다. 일반적인 SMP/CMP 환경에서는 캐시 일관성 지원은 필수적이다.
코어 0과 코어 1이 있고, 각각은 전용 캐시가 존재한다 가정한다. 코어 0이 100번지에 해당하는 데이터를 읽으면 코어 0의 전용 캐시에 데이터가 있게 된다. 이 때 코어 0이 100번지에 새로운 값을 쓴다면 메모리에 갱신되지 않고 코어 0의 캐시에만 최신 값이 있게 될 것이다. 그 이유는 대부분의 캐시(명령어 L1 캐시 제외)는 WRITE-BACK 정책이기 때문이다.
이때 코어 1이 100번지 데이터가 필요하게 되면 코어 1은 100번지 데이터가 갱신되었다는 것을 모른채 최신의 내용을 읽어오지 못할 것이다. 이러한 문제를 예방하고자 HW차원에서 항상 최신 내용을 읽을 수 있게 캐시 일관성을 지원한다.
MSI 스누핑 프로토콜
캐시 일관성은 어떤 주소의 내용을 읽을 때 항상 최신 내용을 읽을 수 있게 한다. MSI 스누핑(snooping) 프로토콜은 캐시 일관성의 가장 고전적인 해법 중 하나이다. 캐시 라인마다 세 가지 일관성 상태인 M(modified), S(shared), I(invalid) 상태를 가질 수 있도록 한다. 그리고 캐시에 접근할 때마다 모든 캐시에게 버스(bus)를 통해 신호를 보내는 스누핑 작업을 한다. 버스는 프로세서 간에 신호를 주고받는 통로이다.
일관성 상태
- invaild: 어떤 캐시 라인의 상태가 유효하지 않다. 읽거나 쓰려면 반드시 값을 요청해야 한다.
- shared: 캐시 라인이 한 곳 이상에서 공유중이다. 또는 자기 자신만 들고 있다. 그러나 이 캐시 라인은 dirty하지 않다. 즉, 쓰여진 적이 없고 읽기만 이루어진 상태다. 또한 메모리도 캐시 라인의 최신 값을 가지고 있다. 여기서 어떤 프로세서가 쓰기를 하려면 반드시 신호를 보내 자신의 캐시 라인을 M 상태로 바꾸면서 다른 캐시 사본은 I(invalid) 상태로 바꿔야 한다.
- modified: 캐시 라인이 어떤 한 프로세서에 의해 고쳐졌음(dirty)을 뜻한다. 메모리에는 이 값이 반영되지 않을 수도 있다. 캐시 라인이 M 상태라면 오직 하나의 코어만 이 캐시 라인을 가지고 있다.
스누핑 예시
1: P1: Read x
2: P1: Write x
3: P3: Read x
4: P3: Write x
5: P1: Read x
6: P3: Read x
7: P2: Read x
1: p1이 x주소의 값을 읽으려함. 캐시라인에 없으므로 캐시미스. 이 데이터를 읽겠다는 스누핑 신호를 버스로 보낸다. 아직 이 데이터를 들고 있는 프로세서가 하나도 없으므로 그냥 메모리에서 이 값을 읽어오고 캐시라인의 상태는 S가 된다.
2: P1이 x에 새로운 내용을 쓰려한다. 값을 쓰려면 이 캐시라인의 상태를 M상태로 업그레이드 해야 한다. 동시에 이 캐시 라인을 무효화하라는 신호를 버스로 보낸다(버스 트래픽 낭비). p2, p3는 아직 캐시 라인이 없어서 아무런 행동을 취할 필요가 없다. 이제 캐시 라인의 최신 상태는 p1이 가지고 있다. dirty 상태이며 캐시 라인이 쫒겨난다면 반드시 메모리에 반영해야만 한다.
3: p3이 x를 읽겠다는 신호를 보낸다. p1은 신호를 듣고서 자신이 이 캐시 라인의 최신 값을 가지고 있음을 확인한다. 그리고 p3에게 데이터를 전송해주겠다고 신호를 보내고 캐시 라인의 내용을 보낸다.(캐시가 데이터를 메모리가 아닌 다른 코어의 캐시로부터 받으므로 이런 것을 cache-to-cache transfer이라고 한다.) 아직 p1이 가진 캐시 라인이 메모리에 반영되지 않았다. 그래서 메모리는 결코 p3의 요청에 응답하지 않는다. 이제 p1이 dirty한 캐시 라인의 내용을 버스로 보낸다. 메모리도 최신 내용을 받아 갱신하고, p3도 요청한 데이터를 받는다. 메모리와 p1, p3 내용이 모두 같다. 이제 p1과 p3가 캐시 라인 x를 공유하므로 p1은 m상태에서 s상태로 내려온다. p3 역시 s상태가 된다.
4: p3이 x에 값을 쓰려한다. 그런데 상태가 s이므로 반드시 m상태로 업그레이드해야 한다. 일단 다른 캐시의 사본을 모두 무효화시키도록 한다. p1은 이 신호를 받아 캐시 라인을 무효화 시킨다(s->i). p3는 m상태로 바꾼 후 값을 x에 쓸 수 있다.
5: p1이 다시 x를 읽으려 한다. 그러나 p1의 캐시 라인은 위 과정에서 p3에 의해 무효화되었다. 따라서 캐시 미스가 발생한다(일관성 미스). p3이 현재 이 캐시 라인의 최신 내용을 가지고 있으므로 메모리를 갱신하고 이 내용을 p1에게 전송하고 자신은 s상태가 된다. p1 역시 s상태이다.
6: p3이 x를 읽고자 한다. p3은 현재 s상태이고, 읽기 작업이라 버스로 신호를 보낼 필요가 없다. 그냥 바로 p3의 캐시에서 데이터를 읽는다.
7: p2가 x를 읽고자 한다. 처음이므로 캐시 미스이다. 그러나 이 값을 가지고 있는 p1, p3가 모두 s상태이고, 메모리 역시 최신 값을 가지고 있다. 메모리가 혹은 p1, p2가 p2에게 x값을 전송한다.
MESI 프로토콜
MSI 프로토콜은 정확히 캐시 일관성을 보장한다. 그러나 무언가 비효율적인 면이 있다. 프로세서나 코어의 갯수가 많아지면 이 버스 스누핑 트래픽도 같이 증가해 병목 지점이 된다. MSI 프로토콜의 가장 큰 단점은 아무도 이 데이터를 공유하지 않았음에도 버스 트래픽이 낭비되는 점이다. 위 MSI 과정의 2번째 예시에서 주소 x가 포함된 캐시 라인을 p1만 쓰고 있는데 쓸데 없이 신호를 보낸다. 오직 자신만이 점유하는데도 상태가 s이기 때문이다. 이러한 부분을 개선하면 싱글코어만이 데이터를 쓰고 읽는데 추가적인 신호 낭비(스누핑 트래픽 감소)를 막을 수 있을 것이다. MESI 프로토콜은 이를 해결한다(추가적인 최적화로 버스에 신호를 보내는 횟수나 메모리 접근 횟수를 줄임).
MESI는 MSI 프로토콜에서 E(Exclusive) 상태를 추가한다. MSI에서 캐시 라인은 오직 자신만이 클린 상태(dirty 비트가 0인)이어도 s상태가 되어야 한다. s상태에서 오직 혼자만이 깨끗한(메모리와 같은) 데이터를 가지고 있는 상태를 분리하고 이를 e상태라 한다. 이로 인해 s상태는 반드시 두 개 이상의 캐시가 사본을 가지고 있는 경우가 된다. 위 MSI 예시의 1단계에서 s상태가 아닌 e상태가 된다. 이러한 차이로 두번째 단계에서 버스에 신호를 보내는 낭비를 막을 수 있다.
MOESI 프로토콜
AMD의 캐시 구조에서 쓰임. Owner 상태 추가.
