reference:
- "리눅스 커널 내부구조" / 백승재, 최종무
- "Operating Systems: Three Easy Pieces" / Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau
프로세스
프로세스의 정의는 "실행중인 프로그램" 또는 "스케줄링 대상 객체"라 할 수 있다.
프로그램은 lifeless한 것이고, 디스크에 상주하고 있을 뿐이다. 이 프로그램이 메모리에 로드되어 CPU를 통해 실행될 수 있을 때 이를 프로세스라 한다.
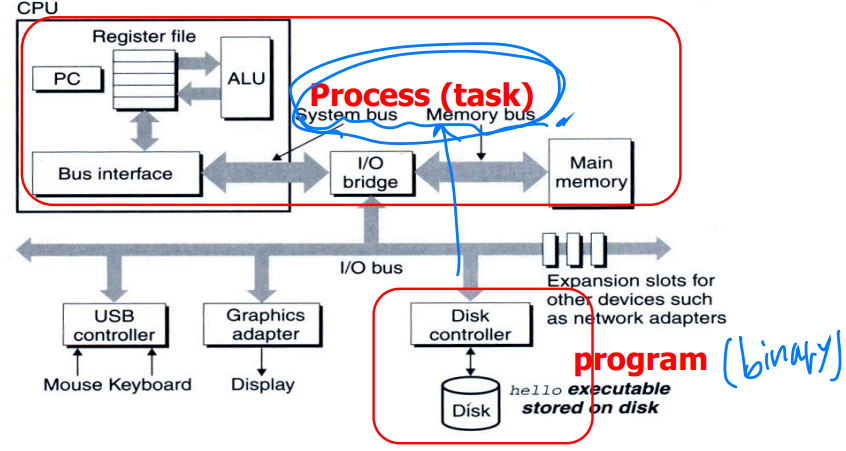
CPU를 추상화한 객체로서의 프로세스
운영체제 입장에서 프로세스는 CPU를 추상화한 객체라고도 할 수 있다. 그리고 이러한 추상화를 통해 여러 프로그램이 각각의 CPU를 가지고 동시에 실행되는 illusion을 실현시킬 수 있다. 바로 다수의 프로세스의 "시분할(Time sharing)" 기법을 통해서이다.
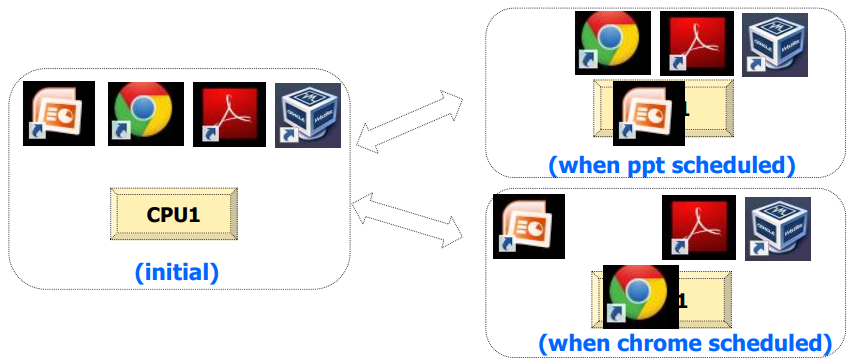
이 시분할 방식의 메커니즘은 문맥 교환이며, 어떻게 문맥 교환을 시킬 것과 관련된 정책을 스케줄링 정책이라고도 한다.
-
문맥 교환(context switch)
: 하나의 주어진 CPU 위 실행 상태의 프로세스 하나를 중지시키고, 다른 대기중인 프로세스를 실행시키는 것 -
스케줄링 정책
: historical information, workload, 또는 성능 지표(metric) 등이 고려된 여러 스케줄링 정책이 있다. 스케줄링이란 실행중인 프로세스를 선점시켜 문맥 교환을 통해 다른 프로세스를 실행시키는 것 또는 그러한 과정의 계획을 뜻한다.
용어 정리
- 태스크(task): 자원소유권의 단위
- 쓰레드(thread): 수행의 단위
- 프로세스(process): "task + thread(s)"로 표현되기도 한다. 디스크에 상주하고 있던 프로그램이 로드된 후 실행되기를 기다리는, 또는 실행 중인 객체를 뜻한다.
(a.k.a active entity) - 프로그램(program): 디스크에 저장되어 있는 실행 가능한 형태의 파일(바이너리 기계 명령어 + 수행에 필요한 자료들의 집합(data))이다.
즉, "바이너리 기계어 + 데이터 집합"
(a.k.a passive entity)
실행 파일(실행 가능 오브젝트 파일)은 그저 디스크에 저장되어 있는 수동적인 존재. 파일 형태로 존재하는 이 프로그램이 수행되기 위해서는 커널로부터 CPU등의 자원을 할당받을 수 있는 동적인 객체가 되어야 하는데, 이 동적인 객체가 바로 "프로세스".
PCB(Process Control Block, 프로세스 제어 블록)
PCB는 각 프로세스 제어를 위한 OS가 관리하는 자료구조로, 리눅스의 경우 'task_struct'라는 자료구조를 사용한다.
이 자료구조는 다양한 정보를 담고 있다. 크게 프로세스 자체 정보, CPU 관련 정보, 메모리 관련 정보, I/O 관련 정보이다.
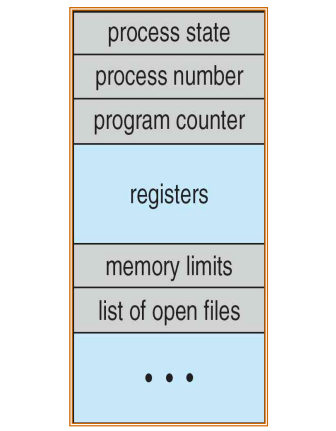
-
프로세스 정보
: 프로세스 상태 정보, 프로세스 ID(pid) -
CPU 관련 정보
: 프로세스의 명령어 수행을 위해 CPU 레지스터에 패치되어야 할 정보들을 담는다. 즉 PC(Program Counter) 레지스터에 패치될 '현재 수행될 명령어 위치'와 SP(Stack Pointer) 레지스터에 담길 '현재 스택 프레임 주소' 등이 있다.
이러한 정보들은 문맥 교환 시 필요한 정보들이다.
-
Memory 관리를 위한 정보
: (1) base/limit 레지스터, (2) 세그멘트 관련 정보, (3) 페이지 관련 정보(페이지 테이블) 등을 나타내는 데이터들도 PCB가 가지고 있어야 한다. -
I/O 관련 정보
: 파일 디스크립터 테이블, 참조하는 장치 파일 등과 같은 파일 관련 정보들도 PCB가 가지고 있어야 한다.
리눅스의 task_struct

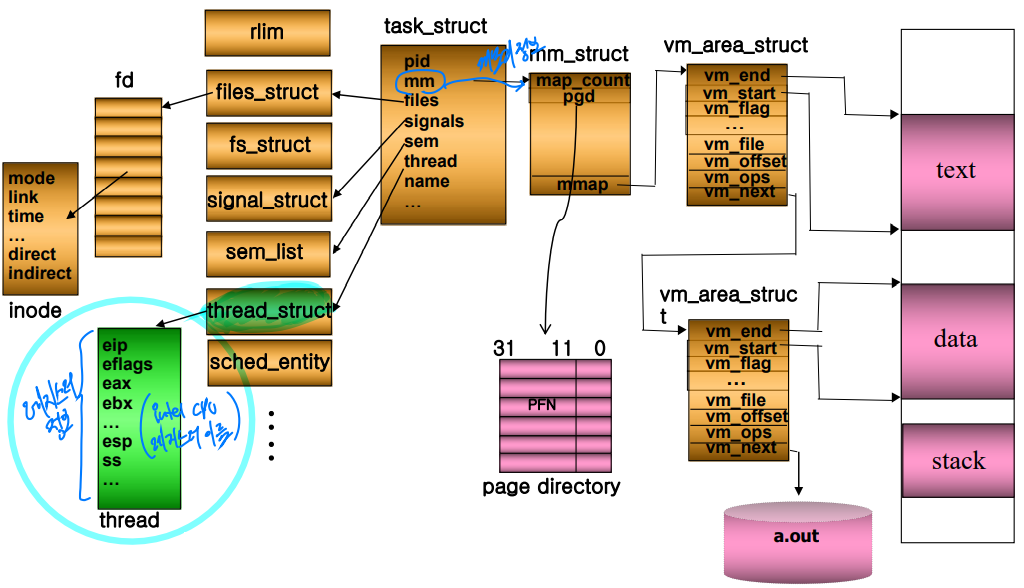
리눅스의 'task_struct' 관련 포스팅: https://velog.io/@jinh2352/Linux-5-%EB%A6%AC%EB%88%85%EC%8A%A4%EC%9D%98-%ED%83%9C%EC%8A%A4%ED%81%AC-%EB%AA%A8%EB%8D%B8
프로그램이 로드될 때의 과정
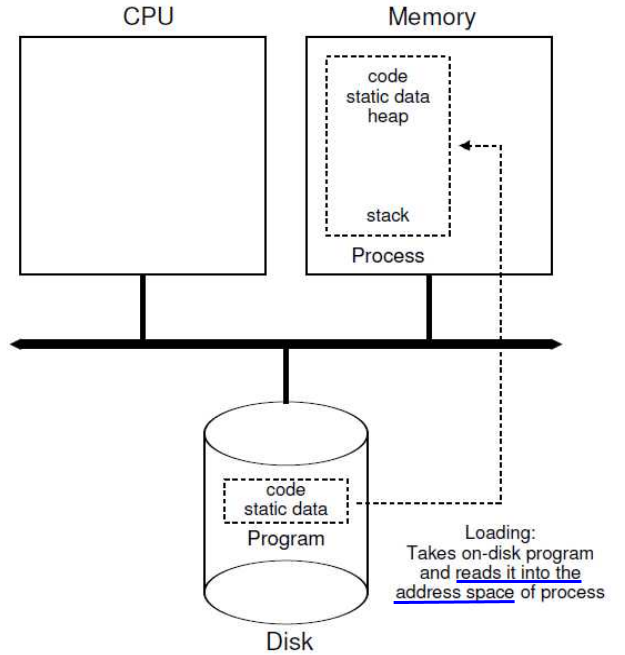
로드란 디스크 상 프로그램이 메모리로 올라가는 것을 뜻한다. 먼저 프로그램의 'Code' 부분과 'static/global' 데이터가 주소 공간(프로세스 독립적인 가상의 메모리 공간)에 로드된다. 이는 디스크 상의 실행가능 포멧(executable format)을 기반으로 한다. 예를 들어 ELF, PE, BSD 등이 있다.
그리고 파일 디스크립터 0/1/2에 대한 초기화를 진행한다. 파일 디스트립터 0/1/2는 각각 표준 입력/출력/에러와 맵핑된다. 그리고 이외 I/O, 시그널 관련 구조를 초기화 한다.
반면 스택, 힙 공간은 프로그램 실행 시 동적으로 할당된다.
로드 후 프로세스 객체로서 처음 패치가 되면 엔트리 포인트로 CPU 제어가 Jump 하게 되며(PC 레지스터에 이 엔트리 포인트가 담김), 이는 이 프로그램의 main() 함수 포인터를 뜻한다.
사용자(또는 개발자) 입장의 프로세스 구조
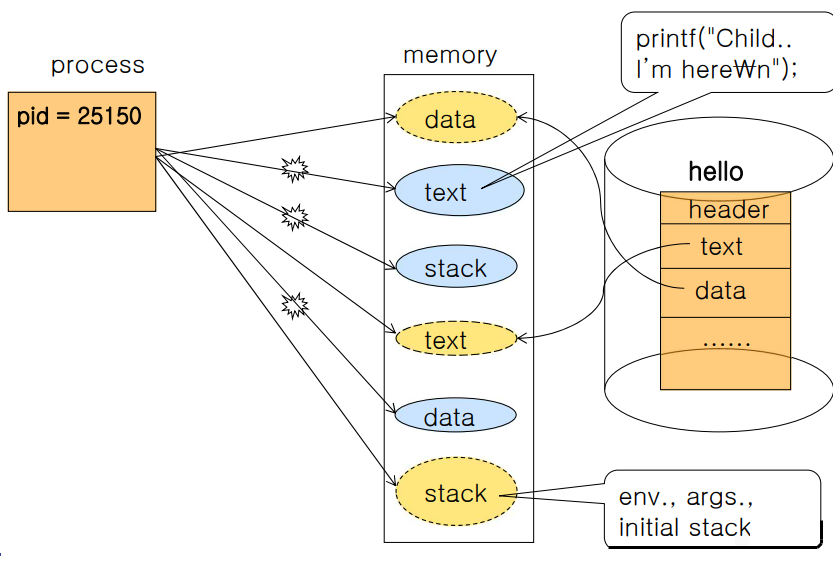
프로세스의 생김새를 논할 떈 보통 가상 주소 공간에서의 모양을 이야기한다.
사용자 프로세스가 수행되기 위해선 여러 가지 자원들을 커널로부터 할당 받아야 하는데, 각각의 프로세스별로 주어지는 가상 주소 공간 역시 이러한 자원 중 하나이다.
32bit CPU의 경우 운영체제는 4GB 크기의 가상공간을 할당해준다. 이중 0~3GB의 공간을 사용자 공간으로 하고, 나머지는 리눅스 커널 공간으로 사용한다.
64bit CPU의 경우 2^64 = 16EB 크기의 가상 공간 중 약 128TB의 공간을 사용자 공간으로 사용.
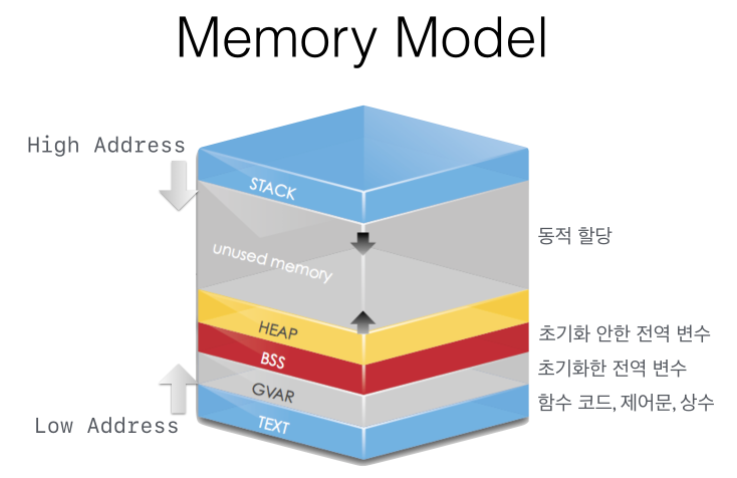
- 텍스트(코드) 영역: CPU에서 직접 수행되는 명령, 함수
- 데이터 영역: 전역 데이터 또는 정적 변수를 위한 공간
- 힙 영역: 프로세스 수행 중 malloc()/free() 등의 함수를 사용하여 동적으로 메모리 공간을 할당받는 곳
- 스택 영역: 함수의 지역변수, 인자, 함수의 리턴 주소 등 스택 프레임에 포함되는 데이터들을 위한 공간
리눅스에선 위 각 영역을 세그먼트(segment)라 부르고, 가상 메모리 객체(vm_area_struct)라는 자료구조로 관리한다.

프로세스와 쓰레드의 생성과 수행
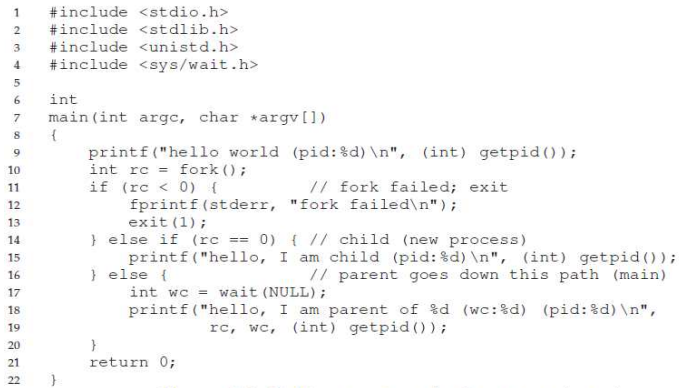
fork() 시스템 콜
부모 프로세스의 코드에서 fork() 시스템 콜을 호출하면 새로운 프로세스(자식)가 생성된다.
부모 프로세스에겐 0 이상의 값을 반환하고, 새로이 생성된 (자식)프로세스에겐 0의 값을 반환한다.
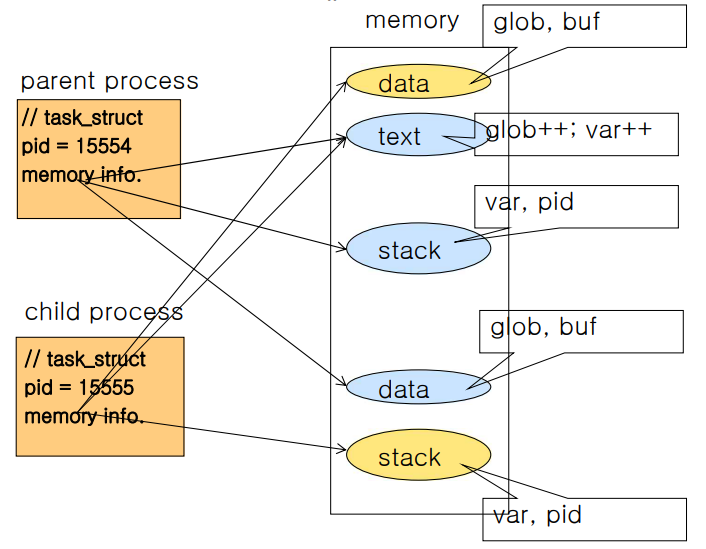
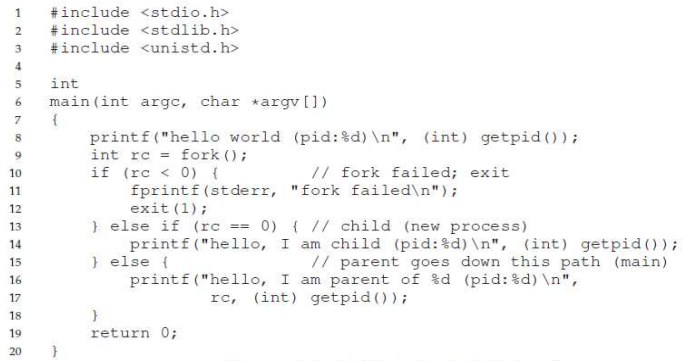
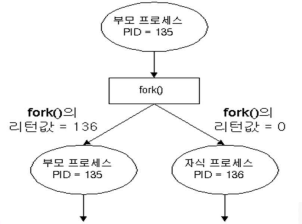
fork() 후 주소 공간 확인 예시
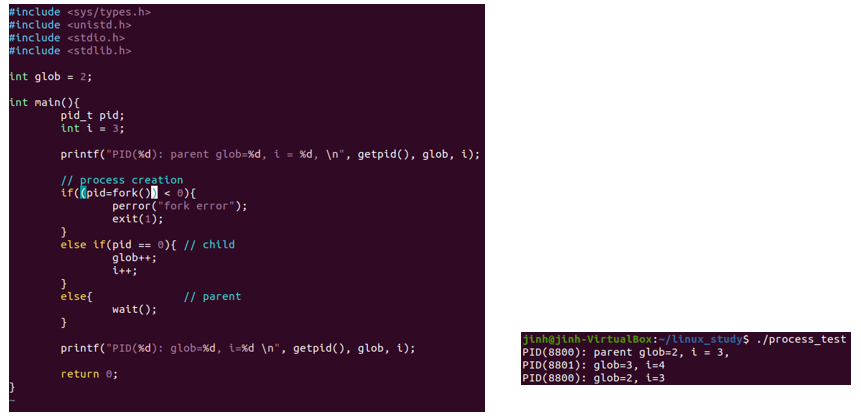
그림의 코드와 실행 결과를 통해 알 수 있는 것은 프로세스가 생성되면 주소 공간을 포함하여 지 프로세스을 위한 모든 자원들이 새로이 할당됨을 알 수 있다.
자식 프로세스의 연산 결과는 자식 프로세스 주소 공간의 변수에만 영향을 줄 뿐 부모 프로세스 주소 공간의 변수에는 영향이 없다.
how about threads?
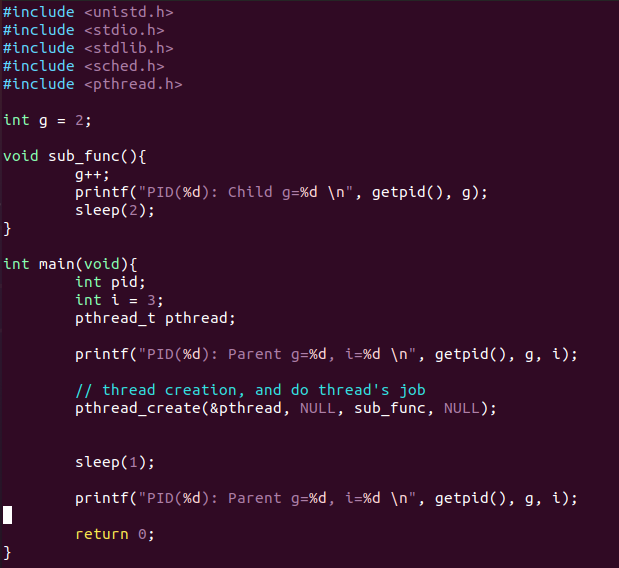
실행 결과

쓰레드는 자신을 생성한 태스크와 동일한 pid를 갖는다. 그리고 이 쓰레드는 함수의 끝을 만나면 종료된다. 위 그림들을 종합하면 다음과 같은 사실을 알 수 있다.
첫 째,
- 새로운 프로세스를 생성하면, 생성된 프로세스(자식 프로세스)와 생성한 프로세스(부모 프로세스)는 서로 다른 주소 공간을 갖는다.
- 새로운 쓰레드를 생성하면 생성된 쓰레드(자식 쓰레드)와 생성한 쓰레드(부모 쓰레드)는 서로 같은 주소 공간을 공유한다.
둘 째,
- 한 프로세스에 여러 쓰레드가 동작할 수 있다. 여러 쓰레드가 동작하는 모델을 다중 쓰레드 시스템이라 한다.
- 쓰레드 생성은 새로이 모든 자원을 생성해주어야 하는 프로세스에 비해 생성 비용이 적다.
셋 째,
- 자식 쓰레들에서 결함이 발생하면 그것은 부모 쓰레드로 전파된다. 반면 자식 프로세스에서 발생한 결함은 부모 프로세스로 전파되지 않는다.
=> 결국 쓰레드 모델은 '자원 공유'에 적합하고, 프로세스 모델은 '결함 고립'에 적합한 프로그래밍 모델.
wait() 시스템 콜
wait() 시스템 콜을 호출하면 자식 프로세스가 실행을 종료할 때가지 기다린다(block 상태).
이를 통해 프로세스 간 동기화(synchronization)을 맞출 수 있다.
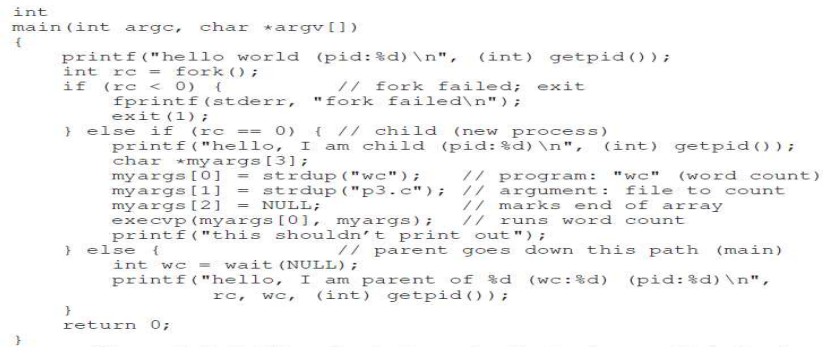
exec() 시스템 콜
exec()은 기존에 사용하던 프로세스의 주소 공간을 모두 없애고, 요청된 바이너리를 기반으로 새로운 주소 공간을 생성한다.
exec()은 프로그램을 로드하는 시스템 콜이라 할 수 있다.
마치 프로세스 객체가 새로운 프로그램에 대한 실행 객체로 탈바꿈한 것과 같다.
태스크 수행을 위한 execl() 시스템 콜
이전 프로세스 생성과 수행 예제의 프로그램(process_test 실행 파일)을 사용하여 execl() 시스템 콜 예제를 들었다.
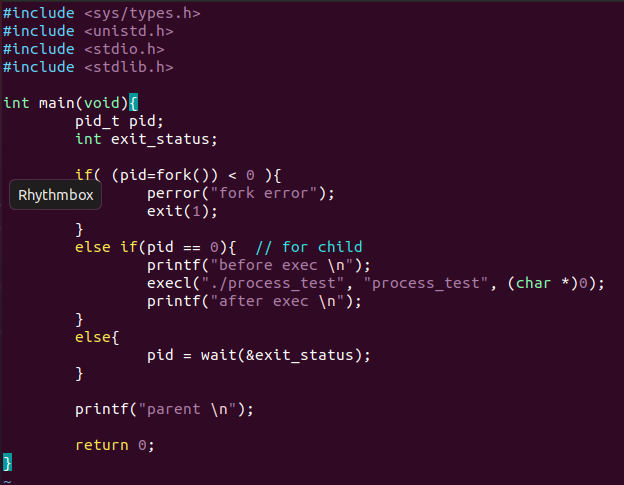
실행 결과
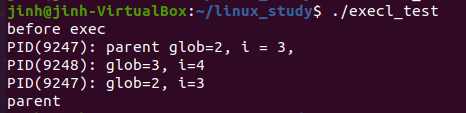
수행 흐름을 설명하면 다음과 같다. 우선 fork() 시스템 콜을 통해 새로운 프로세스를 생성하고, 생성된 프로세스에서 "before exec"이라는 문자열을 출력하고 execl() 시스템 콜을 호출하여 이전에 생성하였던 실행 파일인 'process_test' 바이너리 파일을 수행하도록 하였다. execl()이 성공적으로 수행되면 프로세스의 수행 이미지(텍스트, 데이터, 스택 등)가 기존의 것(execl_test)에서 새로운 것(process_test)으로 바뀌며, 이 때문에 "after exec"을 출력하는 printf() 함수가 수행되지 않는다.
fork() 이 후 바로 exec()이 된다면 손해?
fork() 이 후 바로 exec()이 호출되면 결국 fork() 때 수행했던 부모 프로세스의 주소 공간을 복사하여 자식 프로세스의 주소 공간을 따로 만들어 주었던 작업이 불필요한 작업이 되고 만다. 이 단점을 해결하기 위해 제공되는 것이 vfork()이다.
fork()와 vfork()의 차이
둘 다 프로세스를 생성하는 함수이다.
- fork(): 부모 프로세스의 주소 공간을 복사하여 자식 프로세스의 주소 공간을 따로 만든다.
- vfork(): 일단 같은 주소 공간을 가리키게 함. 예를 들어 fork()를 통해 자식 프로세스의 주소 공간이 만들어 진 후 자식 프로세스에 execl()이 호출되었다 가정해보자. execl()은 기존에 사용하던 프로세스의 주소 공간을 모두 없애고, 요청된 바이너리를 기반으로 새로운 주소 공간을 생성한다. fork() 이 후 곧바로 execl()이 호출되었다면, 이러한 새로운 주소 공간 생성이 불필요한 작업이 되는 것이다. 이러한 불필요성을 막기 위해 vfork()를 사용한다.
최근 리눅스는 COW(Copy on Write) 기법을 통해 fork()로부터 야기되는 주소 공간 복사 비용을 줄임.
