reference:
- "리눅스 커널 내부구조" / 백승재, 최종무
- "Operating Systems: Three Easy Pieces" / Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau
실시간/일반 태스크, 스케줄링 우선순위
여러 개의 태스크들 중 다음에 수행시킬 태스크를 선택하여 CPU라는 자원을 할당하는 과정을 스케줄링이라 한다. 리눅스의 태스크는 실시간 태스크와 일반 태스크로 나뉘며 각각을 위해 별도의 스케줄링 알고리즘이 구현되어 있다.
리눅스는 140단계의 우선순위를 제공한다.
0~99단계: 실시간 태스크가 사용
100~139단계: 일반 태스크가 사용
따라서 실시간 태스크는 항상 일반 태스크보다 우선하여 실행된다.
런 큐와 태스크
일반적으로 운영체제는 스케줄링 수행을 위해 수행 가능한 상태의 태스크를 자료구조를 통해 관리한다. 이를 리눅스에선 런 큐(Runqueue)라 한다.
운영체제 구현에 따라 런 큐는 한 개 혹은 여러 개가 될 수 있다.(자료구조의 모양이나 관리 방법도 달라짐.) 리눅스의 런 큐는 'sched.h' 파일 내에 struct rq 라는 이름으로 정의되어 있다. 부팅이 완료된 이후 각 CPU 별로 하나씩의 런 큐가 유지된다.
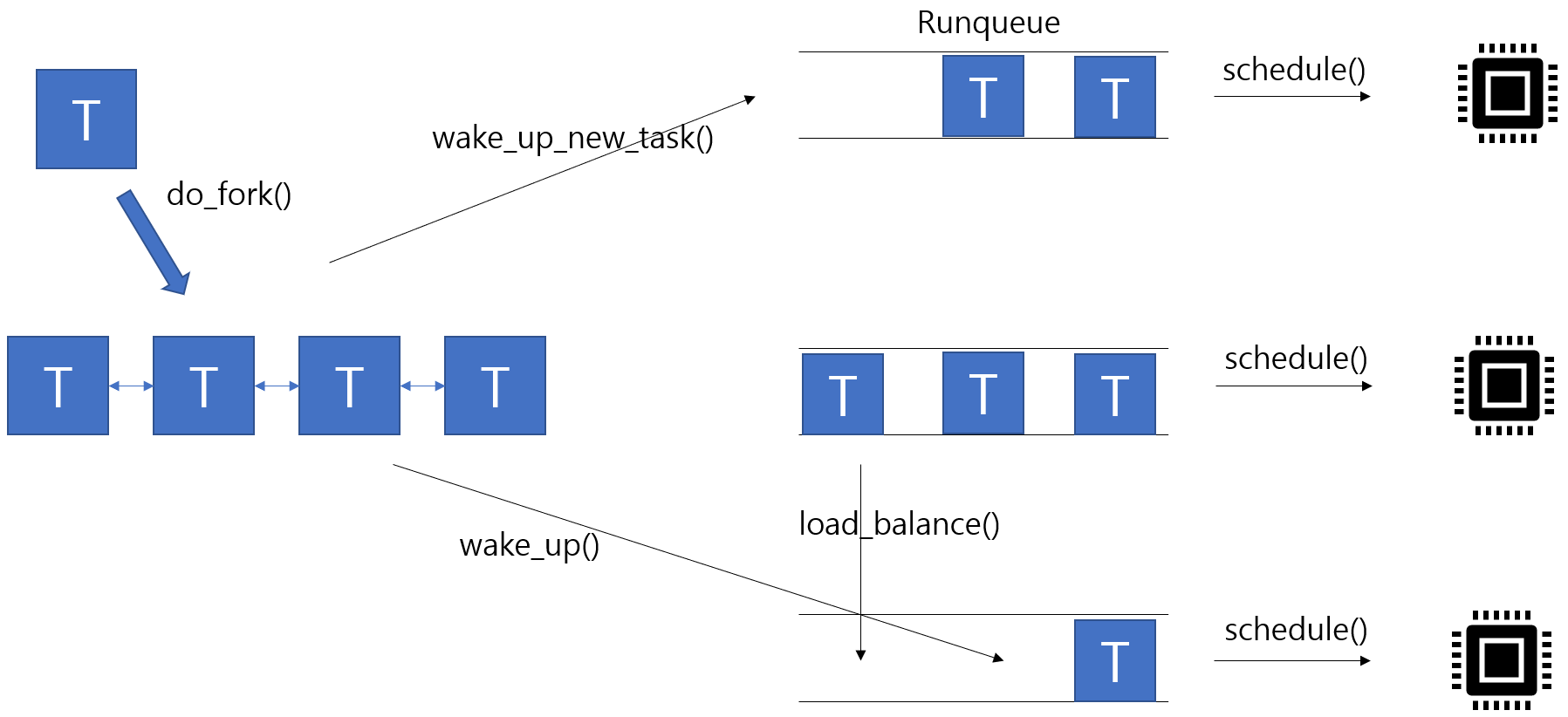
1) 태스크가 처음 생성되면 init_task를 헤드로 하는 이중 연결리스트에 삽입. 결국 리눅스 시스템에 존재하는 모든 태스크들은 이 리스트(tasklist)에 연결됨.
2) 이 중 TASK_RUNNING(ready) 상태인 태스크는 시스템에 존재하는 런 큐 중 하나에 소속됨. wake_up_new_task()는 새로 생성되어 TASK_RUNNING(ready) 상태가 된 태스크를 런 큐로 삽입시킴.
3) wake_up() 함수는 이벤트를 대기하다 깨어나서 런 큐로 삽입되는 과정을 보임.
- 다중 CPU 환경에서 런 큐가 여러 개 일때, 새로 생성된 태스크는 부모 태스크가 존재하던 런 큐로 삽입된다. 더 높은 캐시 친화도(cache affinity)"를 얻을 수 있기 때문.
- 대기 상태에서 깨어난 태스크는 대기 전에 수행되던 CPU의 런큐에 삽입된다. 이 또한 캐시 친화도를 위해서 이다.
task_struct 자료 구조 내 cpus_allowed 필드에 태스크가 수행될 수 있는 CPU의 번호가 들어있고, 이를 이용해 삽입될 런큐를 결정한다.
새로 생성된 태스크의 cpus_allowed 필드는 wake_up_new_task()가 수행될 때 부하 균등(load balance)을 고려하여 수정된다.
CPU의 태스크 선택 고려사항
스케줄러가 수행되면 해당 CPU의 런큐에서 다음에 수행시킬 태스크를 고른다. 이 때 두 가지 고려사항이 존재.
(1) 어떤 태스크를 선택할 것인가? 리눅스는 일반 태스크를 위해 CFS(Completely Fair Scheduler)를 사용, 실시간 태스크를 위해서는 FIFO, RR, DEADLINE 정책 제공.
(2-1) 런 큐간의 부하가 균등하지 않은 경우 어떻게 할 것인가? 리눅스에서는 부하 균등(load balancing)기법 제공하며 load_balance() 함수가 이를 담당. 이 함수는 특정 CPU가 매우 바쁘고, 다른 CPU가 여유로울 때 태스크를 이주(migration)시켜 시스템 전반의 성능 향상을 시도한다.
(2-2) 그렇다면 어느 CPU로 이주시킬 것인가?
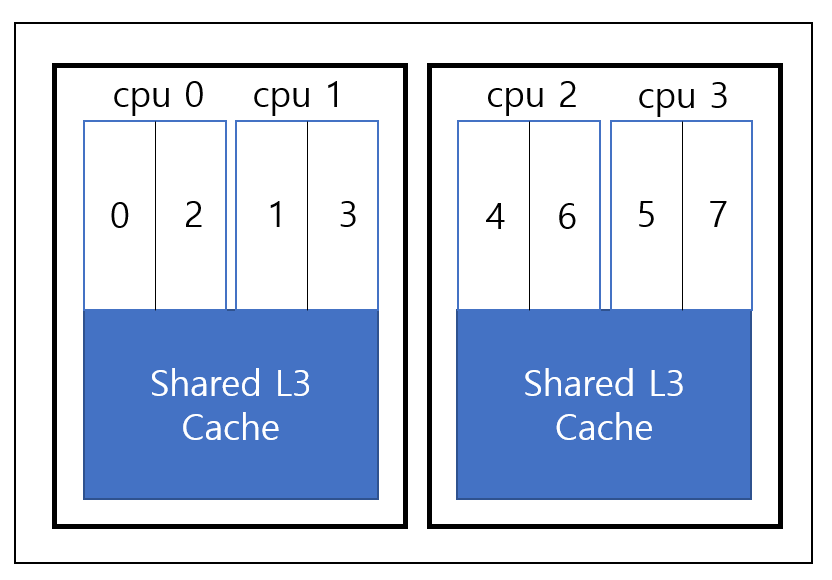
위 그림은 하이퍼 쓰레딩(hyper-threading)을 지원하는 듀얼 코어 칩이 두 개 장착되어 있는 시스템 상태이다. 리눅스가 정상적으로 부팅하게 된다면, 0~7번까지 총 8개의 논리적 CPU가 존재하는 것으로 인식할 것이다.
만약 0번 CPU에서 태스크를 이주시키려 한다면 하이퍼 쓰레딩으로 인해 논리적으로 존재하는 2번 CPU가 태스크 이주에 의한 성능 저하를 최소화 시킬 수 있다.
만약 2번 CPU 마저 부하가 높아 다른 CPU를 물색해야 한다면 L3 캐시를 공유하고 있는 1번 또는 3으로의 태스크 이주가 성능 저하를 최소하 시킬 것이다.
이러한 관리를 위해 리눅스는 struct sched_group, struct sched_domain 이라는 자료 구조로 관리한다.
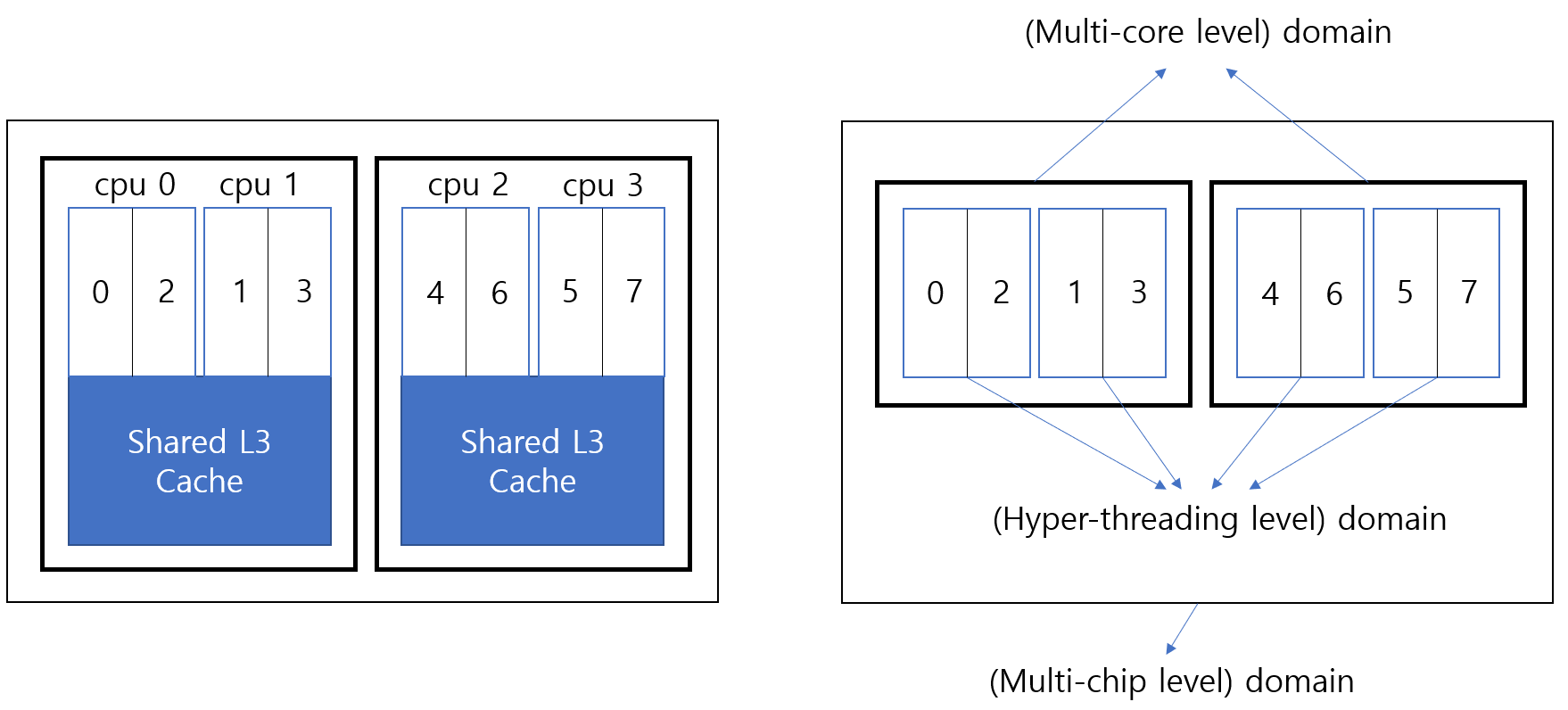
위 그림에서 8개의 논리적인 CPU와 같이 최소 연산 단위를 '그룹'이라 부르며, 이를 위해 struct sched_group이라는 자료 구조를 사용한다. 또한, '그룹'을 하드웨어적인 특성에 따라 '도메인'으로 분류하며, 이는 각 레벨별로 struct sched_domain이라는 자료 구조로 관리된다. 이를 통해 태스크의 이주 대상 CPU 선정하는데 검색을 가능케 한다.
위 설명과 그림은 SMP(Symmetric Multi Processor) 구조의 시스템을 위한 리눅스의 경우에 해당.
한편 NUMA(Non-Uniform Memory Access) 구조의 시스템에서는 load_balance() 함수에서 CPU 부하 뿐 아니라 메모리 접근 시간 차이 등도 고려해야 한다.
load_balance() 함수는 tick 타이머 인터럽트에 기반하여 주기적으로 호출되거나, 특정 CPU의 런큐가 비게 되는 경우, 혹은 실시간 태스크 전이에 의해 호출됨.
