[Operating Systems: Three Easy Pieces] 스케줄링 정책
workload: 작업 부하
주어진 시간(기간)에 시스템에 의해 실행되어야 할 작업량
Schecduling Metrics
-
Turnaround time(반환 시간)
: 완료 시간 - 도착 시간
배치 시스템(batching system)에서는 이 반환 시간이 스케줄링 정책에 좋은 메트릭이 된다. -
Response time(응답 시간)
: 처음 실행된 시간 - 도착 시간
인터랙티브 시스템(interactive system)에서는 이 응답 시간이 스케줄링 정책에 좋은 메트릭이다.
(ex, move a mouse, type in a letter, visit a site..) -
Fairness
: 두 프로스세의 종료 시간이 얼마나 비슷한 가 등을 보고 측정 -
Throughput(처리율)
: 단위 시간동안의 작업량
ex) number of completed processes / 1hour -
Deadline(실시간 시스템)
ex) "반환 시간 < 데드라인"을 지켜내는 가
FIFO(FCFS, First Come First Out)
장단점
- 장점: 간단한 정책, 구현하기 용이함
- 단점: 긴 ready 시간을 야기(known as 'convoy effect)
가정
프로세스 A, B, C가 모두 같은 시간에 런 큐에 도착, 알파벳 순으로 실행됨(tie-break rule)

FIFO 정책으로 스케줄링
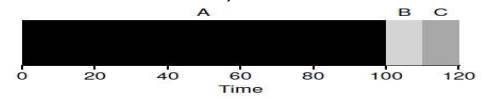
평균 반환 시간(average turnaround time) = (100s + 110s + 120s) / 3 = 110s
평균 반환 시간이 크다는 게 단점이다.
SJF(Shortest Job First) (SPN, Shortest Process Next)
FIFO에서 문제가 된 평균 반환 시간을 줄이기 위한 정책이다. 동시에 도착한 프로세스들간의 실행시간을 비교하여 더 짧은 것을 먼저 실행시킨다.
장단점
- 장점: FIFO 방식보다 평균 반환 시간이 줄어듬. FIFO에서 최적화된 방법
- 단점: 만약 수행 시간이 긴 프로세스가 약간의 근소한 차이 더 빨리 도착한다면?
가정
프로세스 A, B, C가 모두 같은 시간에 런 큐에 도착, 실행 시간이 짧은(shorest job) B와 C를 먼저 실행시킨다.

평균 반환 시간 = (10s + 20s + 120s) / 3 = 50s
문제점
만약 프로세스 A가 약간의 근소한 차이로 먼저 런 큐에 도착하면 별 수 없이 프로세스 A가 먼저 실행되야 되고, 프로세스 B/C는 이를 ready 상태로 길게 남아있어야 한다.
STCF(Shortest Time-to-Completion First) (SRT, Shortest Remaining Time Next)
SJF 정책과 유사하지만 선점형(preemptive) 버전이다.
비선점형(Non-preemptive) 스케줄링
: 하나의 프로세스가 실행을 종료할 때 까지 run 상태를 유지한다.
선점형(preemptive) 스케줄링
: 프로세스가 실행을 종료하지 않아도, 다른 프로세스의 실행을 위해 선점될 수 있다.
현재의 스케줄링 정책들은 대부분 선점형이다.
그리고 이 선점형 스케줄링에는 문맥 교환이 수반된다.

STCF 정책은 선점형이기에 SJF의 장점인 평균 반환 시간을 낮추면서 동시에 SJF의 문제점을 해결할 수 있다.
RR(Round-Robin)
프로세스의 실행을 작은 time slice(scheduling quantum) 내에서만 수행되도록 한다. 만약 time slice가 지나면 같은 런 큐에 ready 상태인 다음 프로세스로 문맥 교환이 된다.
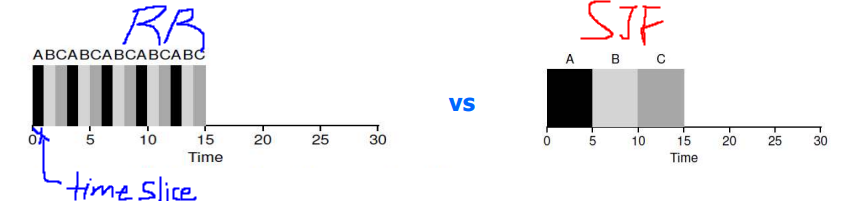
- 장점
: 이 방식을 통해 평균 응답 시간(average respond time)을 낮출 수 있다는 장점이 있다. - 단점
: 하지만 빈번한 문맥 교환으로 발생되는 추가적인 오버헤드는 어쩔 수 없이 수반해야 한다.
Tradeoff of time slice (time quantum)
- small size: 좋은 응답성을 보이지만, 더 높은 문맥 교환 오버헤드가 발생한다.
- large size: 상대적으로 문맥 교환 오버헤드가 줄어든다. 하지만 응답성이 떨어진다.
프로세스의 I/O 요청 시
Busy waiting 방식
단순히 루프를 돌며 I/O 요청이 완료되었는지 확인한다. 루프를 돈다는 것은 I/O 요청 후에도 여전히 CPU를 점유하는 것이므로 의미 없는 작업(체크)으로 CPU 자원을 낭비하고 있는 셈이다.
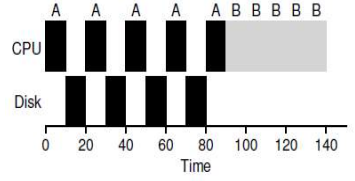
Blocked 방식
I/O 요청이 발생하면 일단 해당 프로세스를 wait 상태로 block 시킨다. 이를 통해 점유하고 있던 CPU를 다른 프로세스가 사용할 수 있도록 하여 전반적인 시스템 자원 낭비를 막게 된다.
추가적으로 DMA 방식이 있다. 이는 HW적 지원이 필요하다.
MLFQ(Multi-Level Feedback Queue)
정리하자면,
FIFO, SJF, STCF는 평균 반환 시간에 유리하며, 평균 응답 시간에는 불리하다. 배치 시스템에 유리할 정책이다.
반면 RR의 경우 평균 응답 시간에는 유리하며, 평균 반환 시간에는 불리하다(+빈번한 문맥교환). 따라서 인터렉티브 시스템에 유리할 정책이다.
이러한 두 분류의 정책 간의 trade-off를 맞추는 정책이 MLFQ이다.
MLFQ 정책에서는 다수의 큐가 존재하며, 각 큐는 다른 우선순위 레벨을 부여받는다.
만약 한 프로세스가 실행 상태가 되면, 가장 높은 우선순위 레벨의 큐에 붙게 된다. 그리고 한 레벨의 큐에선 RR 방식으로 스케줄링 된다.
만약 time-slice를 지나 선점된다면, 하위 레벨의 큐로 이동한다. 그리고 해당 큐가 실행 상태가 되면, 위와 같은 방식으로 반복된다. 이 때 높은 우선순위 레벨의 큐보다 낮은 우선순위 레벨의 큐의 time-slice가 더 길다.
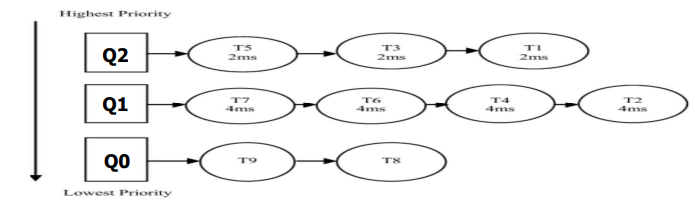
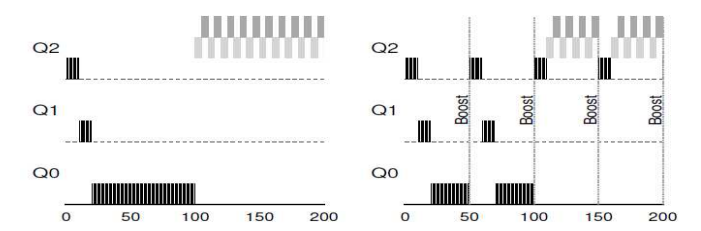
만약 특정 프로세스들이 가장 하위 레벨의 큐에 메달린 상황이고, 계속하여 새로운 프로세스들이 실행되면 기아 상태(startvation)가 일어날 수 있다. 이를 위해 periodic boosting 기법을 통해 가장 높은 우선순위 레벨의 큐로 이동시키면서 해결할 수 있다.
멀티코어 시스템에서의 스케줄링
멀티코어에서의 스케줄링은 각 태스크의 캐시 친화도(cache affinity)를 고려해야 한다.
-
하나의 프로세스가 선점되고, 추후에 다시 실행이 되면, 이전에 선점되었던 CPU에서 다시 실행하는 것이 캐시 친화도 측면에서 더 좋다(+ TLB).
-
새로 생성된 프로세스는 되도록 부모 태스크가 실행 중이던 CPU를 점유하는 것이 낫다. 만약 COW 방식이라면 동일한 메모리 공간에 접근하기 때문이다.
