Concurrency(병행성): Thread and Lock - Intro
Intro
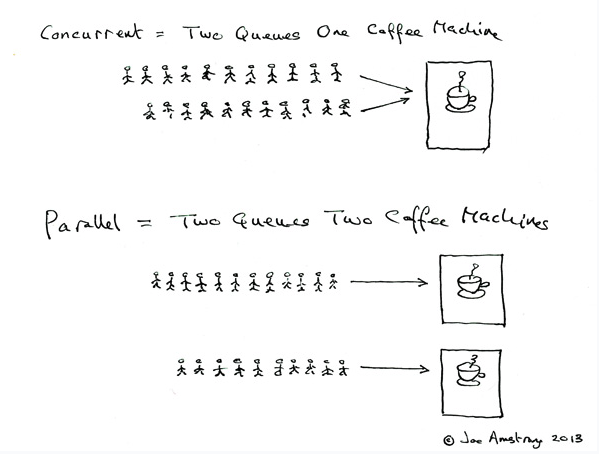
병행성(Concurrency)와 병렬성(Parallelism)의 차이점
source: https://nesoy.github.io/articles/2018-09/OS-Concurrency-Parallelism
병행성(concurrency)
"동시에 실행되는 것처럼 보이는 것"
- 논리적 레벨 / SW 성질로 실현 (by CPU/메모리 가상화)
- 싱글 코어
- 싱글 코어 상에서 물리적으로 병렬이 아닌 순차적으로 동작한다.
- 실제로는 Time-sharing 기법으로 CPU로 나눠 사용함으로써 사용자가 동시에 실행되는 것처럼 느낀다.
(about multi-thread)
- 여러 자원들을 공유한다. ex) 스택을 제외한 주소 공간
- 경쟁 상태(race condition)와 같은 이슈가 있다.
- 병행성을 잘 유지하기 위해 상호 배제(mutex)와 데드락(dead lock) 방지에 신경을 써야한다.
병렬성(Parellelism)
"실제로 동시에 작업이 처리됨"
- 물리적 레벨 / HW 성질로 실현
- 멀티 코어
- 물리적으로 병렬로 동작이 가능하다.
- 거짓 공유(false sharing)와 같은 이슈가 있다.
CPU 가상화
- 다양한 프로그램들을 논리적으로 동시에 실행하게 해준다.
- 가상의 CPU를 여러 개 가지고 있다는 illusion을 준다. 예를 들어 Time-sharing 기법이 있다.
메모리 가상화
- 물리적 메모리를 여러 프로세스가 공유하도록 한다. 서로의 메모리 접근을 막는 isolated 방식이다.
- 각 프로세스가 독립적이고 거대한 주소 공간을 가지고 있다는 illusion을 준다. 예를 들어 가상 메모리(virtual memory) 기법이 있다.
쓰레드(Thread)
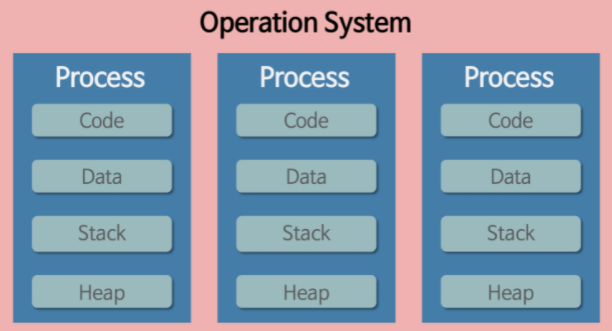
자원을 어떻게 공유하냐에 따라 크게 프로세스(process) 모델과 쓰레드(thread) 모델이 나뉜다.
자원(컴퓨터 자원)이란 크게 다음과 같다.
- CPU: 레지스터(context), 스케줄링 객체(대상)
- Address space: code, data, heap and stack
- Files: 비휘발성 데이터, I/O 디바이스
source: https://gmlwjd9405.github.io/2018/09/14/process-vs-thread.html
프로세스 모델
프로세스끼리는 자원을 배타적으로(독립적으로) 사용한다.
예를 들어 fork() 시스템 콜을 통해 프로세스를 생성하면, 이 프로세스는 모든 자원을 새로 생성한다.
장점은 isolation이 유지된다는 것이고, 단점은 데이터 sharing이 까다롭고 (프로세스)생성이 느리다는 것이다(heavy-weight).
장점과 단점은 프로세스의 그것과 역이라 생각하면 된다.
빠른 생성(light-weight)과 데이터 공유가 편리하다는 것이 장점이고, 단점은 isolation이 떨어진다는 것이다.
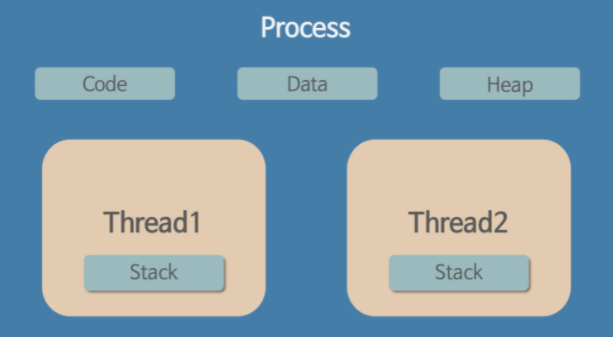
쓰레드 모델
쓰레드 간에는 자원을 공유한다. 주소 공간의 code, data, heap 그리고 파일들을 공유할 수 있다.
하지만 특정 자원은 배타적으로 사용하는데, 레지스터나 stack 공간은 각 쓰레드가 독립적으로 사용한다.
예를 들어 pthread_create() 시스템 콜을 통해 쓰레드를 생성하면 stack과 같은 개별 공간이 따로 생성된다.
프로세스와 쓰레드 모델 중 특별히 어느 것이 더 우월하다는 없다. S/W 개발 시 상황과 요구조건에 맞게 적절히 사용하면 된다. 아주 극단적으로 예를 들자면, 공유하는 영역이 많다면 멀티쓰레드 프로그래밍이 필요할 것이고, 쓰레드간 보호 또는 고립이 중요하다면 멀티 프로세스 프로그래밍이 필요할 것이다.
쓰레드와 병행성의 관계
쓰레드는 다른 표현으로 제어의 흐름(flow of control)이라고도 한다. 하나의 제어 흐름은 다른 제어의 흐름(동일한 프로세스에서 파생)과 스택 영역을 제외한 주소 공간과 파일 등을 공유한다.
반면 프로세스는 이러한 제어의 흐름들과 자원(주소 공간, 파일 등)로 이루어져 있다 볼 수 있다.
쓰레드든 프로세스든 동시에 동작하게 할 수 있고, 이를 멀티 쓰레드(프로세스) 프로그래밍이라 한다. 여기서 여러 개의 쓰레드들이 동작한다는 것은 런타임 도중 주소 공간을 공유할 수 있다는 뜻이고, 이는 곳 공유의 문제가 발생할 수 있다는 뜻이다. (여러 개의 프로세스는 서로의 주소 공간을 공유하지 않기에 이러한 문제가 발생하지 않는다. IPC에 대한 고려는 잠시 생각하지 않는 것으로..)
여러 개의 쓰레드가 싱글 코어에서 실행되든, 멀티 코어에서 실행되든 자원을 공유하게 되고 이는 경쟁 상태(race condition)으로 이어질 수 있다는 것이다. 결국 병행성을 잘 제어해주어야 한다는 의미이다.
-> "enforce to access shared data in a synchrinized way"
쓰레드 관리(Thread management)
- 멀티 쓰레드는 다른 말로 '멀티 스택'이다.
"several stacks in an address space"
(스택은 '쓰레드 지역 스토리지'라고도 불린다.)- 스케줄링 객체(scheduling entity)는 프로세스/쓰레드와 같이 독립적인 스케줄링 객체이다. 스케줄러 관점에선 프로세스나 쓰레드나 사실 같은 스케줄링 객체이다.
- 쓰레드가 스케줄링 될 땐 문맥 교환을 쓰레드 레벨에서 진행한다.
- 쓰레드 레벨: TCB(Thread Control Blcok), 특정한 쓰레드에 대한 정보를 관리하기 위해 필요
- 프로세스 레벨: PCB(Process Control Block), 리눅스에선 task_struct 자료구조로 관리된다.
앞으로 공부할 내용들
1. Concurrency(병행성)
Heart of problem: un-controlled schedule
공유 자원에 있어 스케줄링 제어가 안된다면 문제가 발생함.
관련 키워드: Race condition(경쟁 상태), Mutual exclusion(상호 배제), Atomicity(원자성), ..
2. Thread API & Mutex (쓰레드 관련 API)
Thread vs Process
관련 키워드: creation, completion, mutex(mutual exclusion)
3. Locks
Evaluation method
Building method: Four atomic operations
Spin vs Sleep
4. Locked DataStructure
thread-safe 자료구조
list, queue, hash ..
