reference: "리눅스 커널 내부구조" / 백승제, 최종무
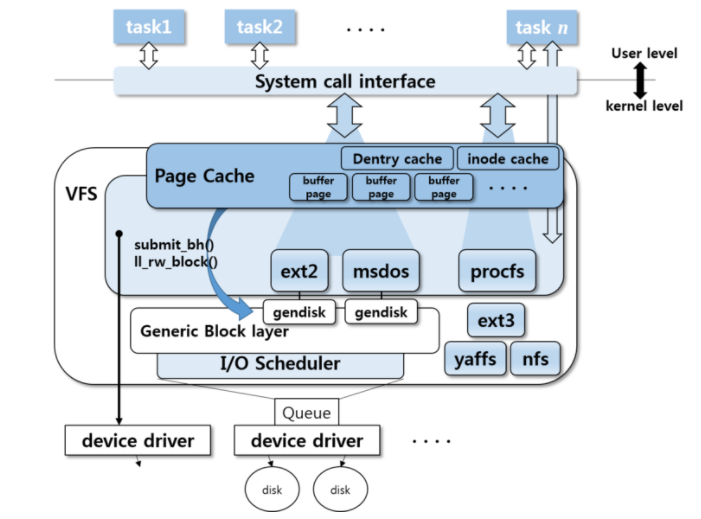
파일시스템에서 논리적인 블록에 대한 read, write 요청이 발생하고, 이 논리적인 블록을 물리적 주소로 변환하는 것이 블록 디바이스 드라이버의 임무이다. 물리적 주소로의 변환은 헤더, 트랙, 섹터 및 몇 개의 섹터를 읽어야하는지에 정하는 것과 같다. 그리고 이 물리적 주소에서 실제 데이터를 메모리(구체적으로 말하자면 커널 페이지캐시 공간)로 읽어온다. 또한 디스크에서 인터럽트가 발생하였을 때 이 사건을 처리하는 것 등을 수행한다.
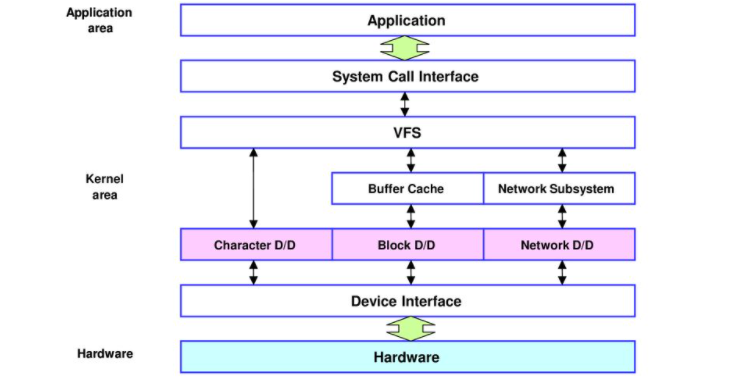
문자 디바이스 드라이버의 read, write 함수는 사용자의 read, write 함수와 1:1로 연결되지만, 블록 디바이스 드라이버는 리눅스의 페이지 캐시와 통신하기에 1:1로 연결되지 않는다. 블록 디바이스는 블록 단위(보통 4KB)로 입출력을 해야하기 때문이다. 예를 들어 사용자가 파일에서 100Byte를 읽기 위해 sys_read()를 호출하였을 때 디스크에선 100B 만큼만 읽지 않고 커널의 페이지 캐시에 4KB만큼을 할당하고, 이 공간에 디스크 내용을 적재한다. 이 후 이 공간에서 사용자가 요청한 100B를 전달한다.
sys_read() => f_op->read() => generic_file_read_iter() => 페이지 캐시 check => (페이지 캐시에 없다면) i_op=>readpage()
일반적으로 메모리(RAM)의 크기는 디스크의 크기보다 작다. 따라서 페이지 캐시 내의 데이터는 언젠가 페이지 교체 정책에 의해 디스크로 플러시(flush)되어야 하는데 이 때 호출되는 함수가 submitbh() 또는 ll_rw_block()이다.
source: https://heotory.tistory.com/8_
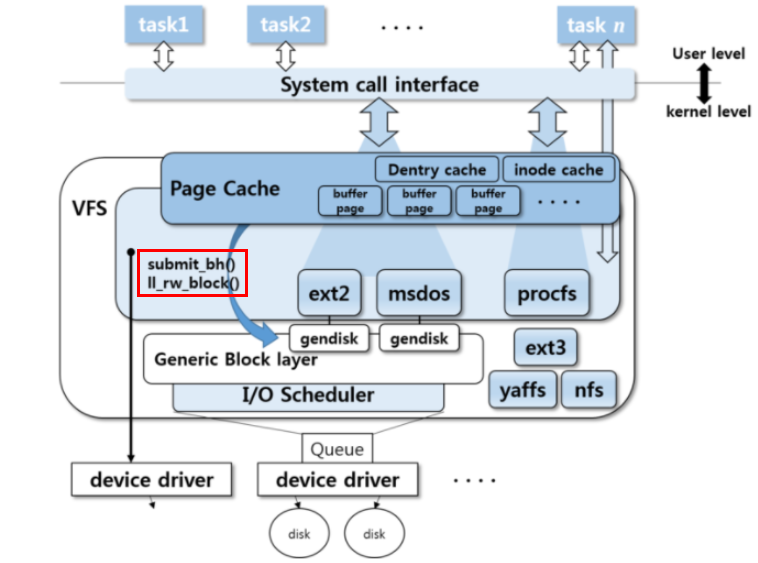
디스크에 몇 번째 섹터에 어떻게 기록할 것인가는 실제 파티션위에 동작하는 파일시스템이 결정한다. 파일시스템에 의해 데이터를 기록할 디스크 상 위치가 결정되었다면 이를 블록 디바이스 드라이버로 내려보내야 한다. 이때 사용되는 함수는 generic_make_request() 함수이다. 이 함수는 I/O 요청을 bio 구조체에 담는다.
일반적인 하드디스크의 경우 디스크 I/O는 데이터 전송을 위한 지연시간이 존재한다. 따라서 대부분의 운영체제는 발생된 I/O 요청을 그대로 블록 디바이스 드라이버로 보내는 대신, 성능 향상을 위해 I/O 요청 순서를 바꾸거나 병합하는 I/O 스케줄링 기법을 사용한다.
리눅스는 대표적으로 4가지의 I/O 스케줄러가 구현되어 있다. => CFQ, Deadline, Anticipatory, NOOP.
1) Completely Fair Queuing(CFQ): 기본적으로 64개의 큐를 유지. 태스크의 PID 해쉬값을 인덱스로 하여 I/O 요청을 각 큐에 나누어 저장한다. 각 큐에서 공평하게 I/O 요청을 꺼내어 디바이스 드라이버의 큐에 넣는다.
2) Deadline: 이 정책에서는 블록번호로 정렬되어 있는 R/W sorted 큐와, deadline으로 정렬되어 있는 R/W deadline 큐를 유지하며, deadline 큐에 있는 읽기 요청과 쓰기 요청이 완료되어야 하는 시간(deadline)을 지정함으로써 특정 I/O 요청이 병합이나 순서 변경 등의 이유로 장시간 대기하는 것을 방지한다.
3) Anticipatory: deadline 정책과 비슷한데 시스템 성능 향상을 위해 두 가지 기법이 추가되었다. 자세한 설명 생략.
4) NOOP: 이름과 같이 아무 일도 하지 않는(?) 정책이다. 일반적인 하드디스크와 달리 I/O 스케줄링으로 인한 성능향상이 적은 SSD등의 저장장치가 존재하기 때문이다.
I/O 스케줄링 과정을 거쳐 실제 블록 디바이스 드라이버로 보낼 I/O 요청들이 결정되었다면, I/O 요청은 블록 디바이스 드라이버의 큐에 담기게 된다. 큐에 들어오는 요청은 크게 read와 write로 나뉠 수 있으며 일반적으로는 read, write 요청을 각각 최대 128개씩 담을 수 있다. I/O 스케줄러가 I/O 요청을 블록 디바이스 드라이버의 큐에 넣은 후 blk_queue_make_request()에서 지정된 드라이버의 함수를 호출함으로써 드라이버가 I/O 작업을 수행하게 된다.
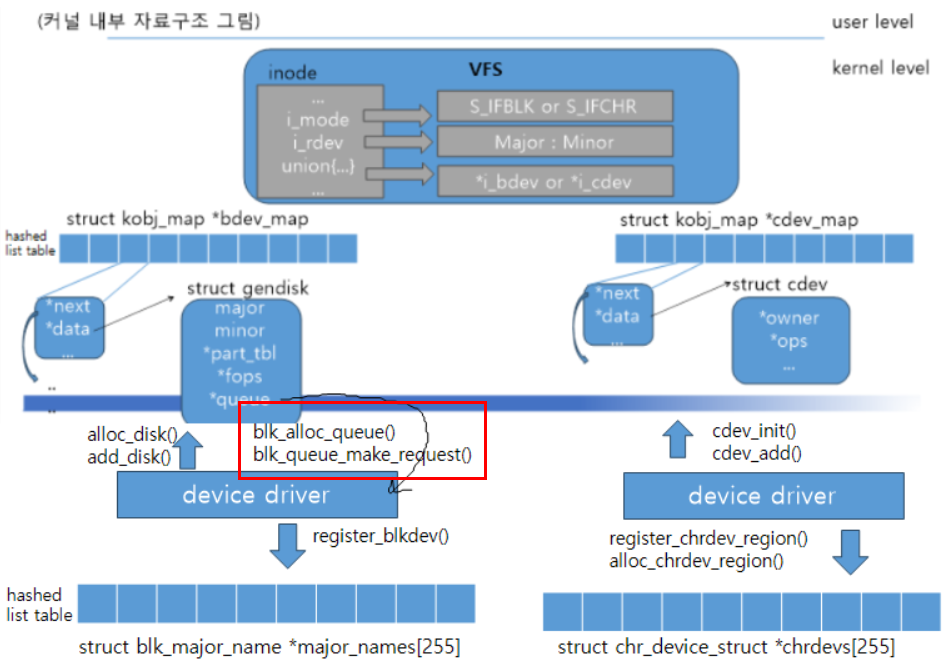
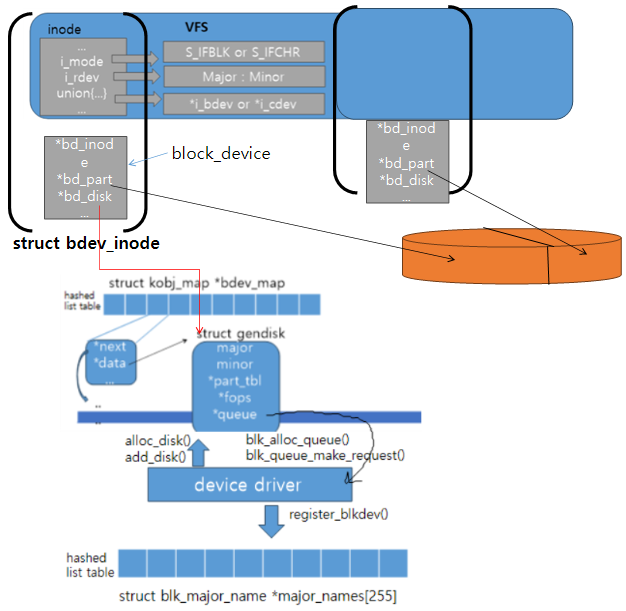
리눅스는 하나의 디스크(드라이버)를 gendisk 구조체를 통해 관리하며, 디스크가 여러 개의 파티션으로 나뉘어져 있는 경우 각각의 파티션은 hd_struct 구조체로 관리된다. gendisk 구조체는 해당 디스크에 데이터 read, write 요청을 보낼 수 있는 큐를 가리키고 있다.
블록 장치 파일은 bdev라는 이름의 특수 파일 시스템에 의해 관리되며, 주 번호, 부 번호를 이용하여 해당 장치파일의 block_device 구조체를 찾을 수 있게 한다. 이 파일 시스템의 디렉터리 엔트리는 bdev_inode로 표현되는데, 이 구조체는 VFS의 inode 구조체와, 각 블록장치 파일 당 하나씩 존재하는 block_device 구조체로 구성되어 있다. block_device 구조체 내에는 자신과 연관된 파티션과 gendisk 구조체를 가리키는 필드 등이 존재한다.
마운트 과정($ mount /dev/sda1/ ./mntdir)
'커널은 주 번호, 부 번호를 이용해 bdev 파일 시스템으로부터 block_device 구조체를 얻는다. 또한 이와 연결된 gendisk의 queue에 읽기 요청을 보냄으로써 슈퍼 블록 등 실제 디스크의 내용을 확인하여 마운트 작업을 완료.
