reference:
- "리눅스 커널 내부구조" / 백승재, 최종무
- "Operating Systems: Three Easy Pieces" / Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau
속도와 효율성을 위해 I/O 시스템 콜(커널)과 표준 C 라이브러리 I/O 함수(stdio 함수)는 디스크의 파일에 작용할 때 데이터를 버퍼링(buffering)함. 버퍼링의 종류는 커널 버퍼링(버퍼 캐시)와 stdio 라이브러리 내의 버퍼링이 있다.
1. 파일 I/O의 커널 버퍼링: 버퍼 캐시 (= 페이지 캐시)
디스크 파일을 가지고 작업할 때, read()와 write() 시스템 콜은 바로 디스크에 접근하지 않는다.
이 시스템 콜들은 단순히 데이터를 사용자 공간 버퍼와, 커널 버퍼 캐시(buffer cache) 내의 버퍼 사이에 데이터를 복사한다.
char buf[] = "abc";
write(fd, buf, 3);위 write 시스템 콜은 사용자 공간 메모리 내의 버퍼로부터 커널 공간 내의 버퍼(in memory, 커널은 항상 메모리에 상주)로 3바이트의 데이터를 전송한다.
write() 리턴하고, 이후에 커널은 디스크에 버퍼의 내용을 쓴다(== flush). write()는 사용자 공간에서 커널 버퍼 캐시로 데이터를 전송한 후에 리턴한다.
이러한 이유로 시스템 콜은 디스크 동작과 동기화되어 있지 않다고 한다.
중간 과정에서 다른 프로세스가 동일한 파일의 동일한 바이트를 읽으려 시도하면, 커널은 파일에 있는 내용 대신, 자동으로 버퍼 캐시에 있는 데이터를 제공한다.
입력의 경우도 마찬가지, 커널은 디스크에서 데이터를 읽고 커널 버퍼에 저장한다.
read() 호출은 이 버퍼가 모두 소진될 때까지 데이터를 가지고 온다.
버퍼가 모두 소진된다는 것은 어느 시점에서 커널이 파일의 다음 세그먼트(블록?)를 버퍼 캐시로 읽어들이는 것을 의미.
(순차적인 파일 접근에서 커널은 보통 읽는 절차가 파일의 다음 블록을 요구하기 전에 버퍼 캐시에 저장되어 있도록 보장하기 위해 미리 읽기read-ahead를 수행.)
이러한 설계의 목적은 시스템 콜 사용 시 느린 디스크 동작을 기다릴 필요가 없게 하여 속도를 향상시키도록 하고자 함이다. 또한 커널이 수행해야만 하는 디스크 전송 수를 줄이면서 효율성을 꾀하는 것이다.
리눅스 커널은 버퍼 캐시의 크게에 대해 고정된 상한선을 내세우지 않음. 커널은 요구되는 만큼 버퍼 캐시를 할당할 것이며, 이때 크기는 가용한 물리 메모리의 크기와 다른 목적으로 요구되는 물리 메모리의 양에 따라서만 제한될 것.
가용 메모리가 부족한 경우, 커널은 수정된 버퍼 캐시 페이지를 디스크에 플러시하고 가용해진 페이지를 재사용한다.
커널 2.4 이후로 리눅스는 더 이상 분리된 버퍼 캐시를 유지하지 않는다. 대신 파일 I/O 버퍼는 "페이지 캐시"에 포함된다. 페이지 캐시는 예를 들어 메모리 매핑된 파일도 담고 있다. 그럼에도 불구하고 유닉스 구현에서 역사적으로 '버퍼 캐시'라는 용어를 흔히 사용한다.
버퍼 크기가 I/O 시스템 콜 성능에 미치는 영향
커널은 하나의 바이트를 1000번 쓰든, 1000바이트를 한 번 쓰든 상관없이 동일한 횟수로 디스크에 접근. 버퍼 캐시가 존재하여 write() 호출이 디스크 동작과 동기화되지 않기 때문이다. 따라서 같은 디스크 접근 횟수라면 시스템 콜이 1000배 많이 호출되는 후자의 작업이 불리하다.
커널은 하나의 바이트를 1000번 쓰든, 1000바이트를 한 번 쓰든 상관없이 동일한 횟수로 디스크에 접근한다. 이는 버퍼 캐시(페이지 캐시)가 존재하고, 버퍼 캐시에서 flush하는 횟수가 같다는 뜻이다.
하지만 전자(하나의 바이트를 1000번 쓰는 작업)는 1000의 시스템 콜(write())을 요구하는 반면, 후자는 한 번의 시스템 호출만을 요구하기에 더 낫다.
디스크 동작보다는 훨씬 빠르지만 시스템 콜 역시 상당한 시간이 걸리는 것은 사실.
write() 시스템 콜이 호출되었을 때 내부적으로 다음과 같은 작업들이 필요하다.
(1) 커널이 시스템 콜 호출을 감지해야함.
(2) 시스템 콜 인자의 유효성 검사.
(3) 사용자 공간에서 커널 공간으로 데이터를 전송(사용자 공간 버퍼 => 커널 버퍼 캐시).
(+) 문맥교환
아래 코드를 살펴보면,
#include <sys/stat.h> // fstat/mkdir/stat과 같은 함수들 정의, mode_t를 위해 상수들 정의(S_IRWXU .. 등)
#include <fcntl.h> // creat(파일 생성)/fcntl(파일 제어)/open(파일 열기)과 같은 함수들 정의, O_CREAT, O_EXCL와 같은 open/fcntl 시스템 콜 속성들에 대한 상수 정의
#include "tipi_hdr.h" // 리눅스 API 프로그래밍 제공 헤더
#ifndef BUF_SIZE
#define BUF_SIZE 1024 // 사용자 공간 버퍼 사이즈: 1024
#endif
int main(int argc, char * argv[]){
int fdIn, fdOut, openflags;
mode_t filePerms; // 파일 접근 권한
ssize_t numRead;
char buf[BUF_SIZE];
if(argc != 3){
printf("PROGRAM INPUT ERR \n");
exit(-1);
}
// 원본 파일 오픈
fdIn = open(argv[1], O_RDONLY);
if(fdIn < 0){
printf("ORIGINAL OPEN ERR \n");
exit(-1);
}
openflags = O_CREAT | O_WRONLY | O_TRUNC; // OR 연산, open()의 생성 속성과 접근 모드 정의 -> 정수 형태
filePerms = 0664; // 파일 접근 권한, 8진수로 표현: 110 110 100
// 복사본 파일 오픈(create)
fdOut = open(argv[2], openflags, filePerms);
if(fdOut < 0){
printf("COPIED OPEN ERR \n");
exit(-1);
}
// 모든 파일 내용 읽기 / 1024 1024 ... 1024 이하
while((numRead = read(fdIn, buf, BUF_SIZE)) > 0){ // 원본 파일에서 읽기
if(write(fdOut, buf, numRead) != numRead){ // 복사할 파일에 쓰기
printf("WRITE ERR \n"); // : 파일 -> 파일 복사
exit(-1);
}
}
// read에서 에러가 발생했었다면 exit
if(numRead < 0 ){
printf("READ ERR \n");
exit(-1);
}
// clase 작업
close(fdIn);
close(fdOut);
return 0;
}"#define BUF_SIZE 1024 // 사용자 공간 버퍼 사이즈: 1024" <= 각기 다른 BUF_SIZE 값으로 실행시키면서 실험을 진행할 수 있다.
위 코드에서 (사용자 공간)버퍼 사이즈의 크기를 변화시키면서 1억 바이트 크기의 파일을 복사(read->write)해본다.
실험 설정
1. 블록 크기가 4096바이트(4KB)인 ext2 파일 시스템에서 바닐라 커널 2.6.30을 사용해 실행
2. 파일 시스템을 마운트 해제(unmount)하고 다시 마운트(remount)함으로써 파일 시스템에 대한 버퍼 캐시가 비었음을 보장
3. 시간 측정은 셸의 time 명령 사용
데이터가 전송되는 전체 양(디스크 동작의 횟수 = flush 횟수)은 여러 버퍼 크기에 모두 동일하기 때문에, 실험 결과는 read()오 write()의 호출에 따른 오버헤드에 좌지우지 된다. 버퍼 크기가 1 바이트일 땐 1억번의 read()와 write() 호출을 한다. 반면 버퍼 크기가 4096바이트일 땐 대략 24,000번의 시스템 콜을 하며, 이는 최적의 성능에 가깝다. (이 시점을 넘어가면 시스템 콜의 부하는 사용자 공간과 커널 공간 사이의 데이터 복사에 요구되는 시간에 비해 무시할 만한 수준이 되기에 주목할 만한 성능 향상은 발생하지 않음.)
요약하자면 파일에서 파일로 큰 데이터를 전송하고, 큰 블록에 데이터를 버퍼링하고, 좀 더 적은 수의 시스템 콜을 수행한다면, 획기적으로 I/O 성능을 향상시킬 수 있다. 같은 횟수의 flush(디스크로의 접근)라면 시스템 콜 호출 횟수를 줄이자는 것이다.
반면 프로세스의 가용 메모리 공간이 줄어든다는 것은 단점이 될 수 있다.
2. stdio 라이브러리 내의 버퍼링
디스크 파일 동작을 실행할 때, 시스템 콜을 줄이기 위해 (응용 레벨에서) 큰 블록에 데이터를 버퍼링하는 것은 C 라이브러리 I/O 함수(ex, fprintf(), fscanf(), fgets(), fputs(), ..)가 하는 동작과 똑같다. 따라서 stdio 라이브러리를 사용하면 write() 출력이나 read()이 입력 데이터를 직접 버퍼링할 필요 없다.
stdio 스트림의 버퍼링 모드 설정 (setbuf())
setvbuf() 함수는 stdio 라이브러리의 버퍼링 방식을 제어한다.
#include <stdio.h>
int setvbuf(FILE *stream, char *buf, int mode, size_t size);stream 인자는 버퍼링이 수정되어야 하는 파일 스트림을 식별. 해당 스트림이 열리고 난 후에, setvbuf() 호출은 그 스트림에서 다른 stdio 함수를 호출하기 전에 실행돼야만 한다. setvbuf() 호출은 명시된 스트림의 향후 모든 stdio 오퍼레이션의 동작에 영향을 미친다. buf와 size 인자는 stream에 사용될 버퍼를 명시한다. 또한 mode 인자는 버퍼링의 형을 명시한다.
void setbuf(FILE *stream, char *buf); // setvbuf의 위 계층에 자리하고, 유사한 동작 실행
void setbuffer(FILE *stream, char *buf, size_t size); // setbuf와 유사하지만, 호출자가 buf의 크기를 명시할 수 있도록 허용stdio 버퍼 플러시
현재 버퍼링 모드에 관계없이, 언제든지 fflush() 라이브러리 함수를 사용해 stdio 출력 스트림에서 데이터를 강제로 쓰게 할 수 있다. 즉 write()를 통해 커널 버퍼로 플러시하는 동작이다. 이 함수는 명시된 stream에 대해 출력 버퍼를 플러시한다.
stdio 버퍼 => 커널 버퍼 (캐시)
#include <stdio.h>
int fflush(FILE *stream);- stream이 NULL이면 fflush()는 모든 stdio 버퍼를 플러시한다.
- fflush() 함수는 입력 스트림에 적용될 수도 있다. 모든 버퍼링된 입력이 버려진다.
- stdio 버퍼는 해당되는 스트림이 닫히면(fclose()) 자동으로 플러시된다.
3. 파일 I/O 커널 버퍼링 제어
출력 파일에 대해 커널 버퍼(페이지 캐시)의 플러시를 강제할 수 있는데, 때때로 이런 동작은 응용 프로그램(예를 들어 데이터베이스 저널링 프로세스)이 작업을 진행하기 전에 실제로 출력이 디스크에 기록됐는지 확인해야 하는 경우에 필수적이다.
커널 버퍼링 제어 관련 SUSv3(유닉스 표준 중 하나)에서 내린 몇가지 정의
SUSv3는 '동기화된 I/O 완료'라는 용어를 "디스크에 성공적으로 전송됐거나 실패했다고 진단된 I/O 오퍼레이션"으로 정의하고, 이 정의는 2가지로 나뉜다. 두 가지의 차이점은 파일을 기술하는 메타데이터를 수반한다.
메타데이터: data for data, 파일 소유자와 그룹, 파일 권한, 파일 크기, 파일의 링크 수, 마지막 파일 접근과 수정, 메타데이터 변경 시간, 파일 데이터 블록 포인터 등의 정보
-
동기화된 I/O 파일 무결성 완료: 동기화된 I/O 데이터 무결성 완료의 상위 집합. 파일 데이터의 차후 읽기 오퍼레이션에 관련이 없더라도 파일 갱신 동안 모든 갱신된 파일 메타데이터는 디스크로 전송됨.
즉, 데이터(버퍼 내용)을 플러시할 뿐 아니라, 파일의 메타 데이터도 갱신 -
동기화된 I/O 데이터 무결성 완료: 예를 들어 쓰기 오퍼레이션 시 수정된 파일 메타데이터 속성이 해당 파일 데이터를 추출하는 데 전송될 필요는 없음.
즉, 데이터(버퍼 내용)만 플러시
파일 I/O 커널 버퍼링 제어를 위한 시스템 콜
fsync()
#include <unistd.h>
int fsync(int fd);fsync() 시스템 콜은 버퍼링된 데이터를 야기하고, 열린 파일 디스크립터와 관련된 모든 메타데이터는 디스크로 플러시되게 한다. fsync() 호출은 그 파일에 동기화된 I/O 파일 무결성 완료 상태를 강제함.
fdatasync()
fsync() 호출은 디스크 디바이스에 전송이 완료된 이후에만 리턴한다.
fdatasync() 시스템 콜은 fsync()와 유사하게 동작하지만, 파일을 동기화된 I/O 데이터 무결성 완료 상태로만 강제한다.
#include <unistd.h>
int fdatasync(int fd);fdatasync()를 사용하면 잠재적으로 fsync()에서 요구되는 두 가지 오퍼레이션에서 한 가지 오퍼레이션으로 디스크 동작의 수가 줄어든다. 예를 들어, 파일 데이터가 변경됐지만 파일 크기는 변경되지 않은 경우 fdatasync() 호출은 데이터만 갱신한다.(최종 수정 타임스탬프 같은 파일 메타데이터 속성의 변경은 동기화된 I/O 데이터 무결성 완료를 위해 전송될 필요가 없다.) 반대로 fsync() 호출은 메타데이터가 디스크로 전송되게 할 것이다.
디스크 I/O 오퍼레이션의 수를 줄이는 것은 성능이 매우 중요하고 타임 스탬프와 같은 특정 메타데이터의 정확한 유지가 필수적이지 않은 응용 프로그램에 유용하다. 이 방식은 파일을 여러 번 갱신하는 응용 프로그램에서 확연한 성능 차이를 만들 수 있다. 이는 파일 데이터와 메타데이터는 일반적으로 디스크의 다른 부분에 위치하고, 두 가지 모두 갱신하려면 디스크에서 앞뒤로 위치를 찾는 동작을 반복해야 하기 때문이다.
sync()
sync() 시스템 콜은 갱신된 파일 정보(ex, 데이터 블록, 포인터 블록, 메타이터 등)를 포함하는 모든 커널 버퍼가 디스크로 플러시되게 한다.
#include <unistd.h>
void sync(void);리눅스 구현에서 sync()는 모든 데이터가 디스크 디바이스(혹은 적어도 디바이스의 캐시로)로 전송되고 난 후에만 리턴한다.
SUSv3는 단순히 I/O 전송을 스케줄링하고, 완료되지 전에 리턴하는 sync() 구현을 허용한다.
이 방식으로 구현한다면 이 함수를 호출하였을 때 시스템에 반영하라는 명령을 내리는 것이라 함수가 끝났다고 실제 디스크에 쓰여졌다는 것을 보장할 수는 없다. 물론 충분한 시간이 흐른 뒤에는 디스크에 반영한다는 것은 보장한다.
모든 쓰기 동기화: O_SYNC
open() 시스템 콜을 호출할 때 O_SYNC 플래그를 명시하면 모든 차후의 출력이 동기화된다.
fd = open(pathname, O_WRONLY | O_SYNC);open() 호출 후에 해당 파일에 대한 모든 write()는 자동적으로 파일 데이터와 메타데이터를 디스크로 플러시한다.(즉 쓰기는 동기화된 I/O 파일 무결성 완료에 따라 실행)
O_SYNC 플래스의 사용(혹은 빈번한 fsync()나 fdatasync(), sync() 호출)은 성능에 상당한 영향을 미칠 수 있다.
새로 생성된 파일에 백만 바이트를 기록하는데 프로그램이 있다. 버퍼 사이즈에 따라 성능을 비교해보면,
1) 1바이트 버퍼의 경우 O_SYNC는 소요되는 시간이 1000배 이상 엄청나게 증가한다. 이 차이는 각 버퍼가 실질적으로 디스크에 전송되는 동안 블록(I/O 작업으로 인해)되는 프로그램의 결과가 된다.
요즘 디스크 디바이스 드라이버에는 큰 내부 캐시가 있고, 기본적으로 O_SYNC는 그저 데이터가 캐시로 전송되게 한다. 디스크 캐시를 끈다면 O_SYNC가 성능에 미치는 영향은 더욱 극단적일 것이다. 1바이트 버퍼 사이즈의 경우 경과시간은 1030초에서 16,000초 근처로 상승하고, 4096 바이트 버퍼 사이즈의 경우 0.34초에서 4초로 증가한다.
(파일 I/O 커널 버퍼링 제어) 요약
요약하자면 커널 버퍼의 플러시를 강제할 필요가 있을 경우, 파일을 열 때 O_SYNC 플래그를 사용하는 대신에, 큰 write() 버퍼 크기를 사용하거나 fsync()나 fdatasync()를 신중하게, 간헐적으로 호출하도록 응용 프로그램을 설계할 수 있을지 여부를 고려해야한다.
4. I/O 버퍼링 요약
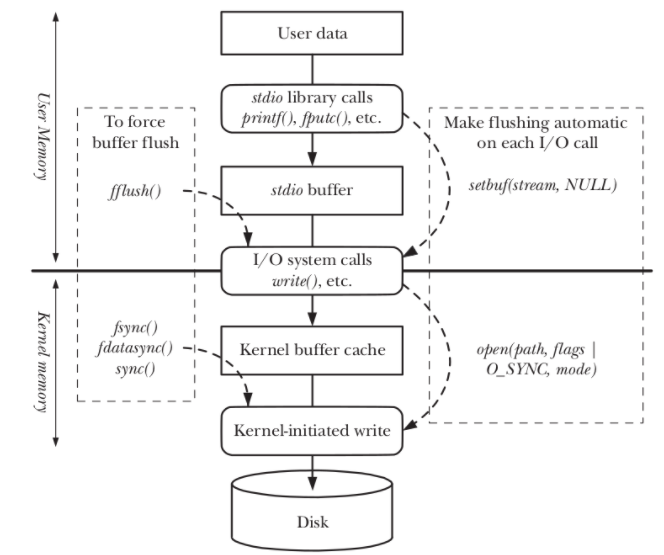
stdio 버퍼의 stdio 라이브러리 함수에 의한 사용자 데이터의 전송은 사용자 메모리 공간에 유지됨을 알 수 있다. 이 버퍼가 채워질 때 stdio 라이브러리는 write() 시스템 콜을 실행하고, 이는 (커널 메모리에 보관된) 커널 버퍼 캐시로 데이터를 전송한다. 결국 커널은 디스크로 데이터를 전송하기 위해 디스크 오퍼레이션을 시작한다.
그림의 왼쪽은 커널 버퍼로 또는 디스크로의 플러시를 강제하는 호출을 보여주며, 오른쪽은 stdio 라이브러리에서 버퍼링(사용자 공간 수준 버퍼링)을 비활성하거나, 출력 시스템 콜을 동기화해 각 write()가 즉시 디스크로 플러시하도록 하여 자동 플러시가 발생하게 하는 호출이다.
