python
✔️ 배우기 쉬움(문법, 데이터 처리 간단)
사용하기 쉬운 라이브러리 多
💢중괄호가 없으므로 들여쓰기로 처리
- interactive하게 실행 가능
- python version 3.x를 주로 사용한다
개발 환경 세팅
우리가 사용할 개발툴은
Jupyter notebook(web기반의 개발툴)
✔️ 데이터 분석, 머신러닝, 딥러닝에 적합함
작업의 안정성을 위해 먼저 local에 설정
💢우리는 Anaconda platform내에서 그 안에서 python, Jupyter notebook설치할 것이다
- Anaconda 설치
- Jupyter notebook설치(아나콘다 내에서)
- 실행
🐈⬛먼저 colab부터 알아보자!
구글 드라이브에 colabaratory설치(내 구글 드라이브에서 코랩을 사용할 수 있도록 연동하는것)
1) cell에 코드 작성(컨트롤 엔터로 실행시킬 수 있음)
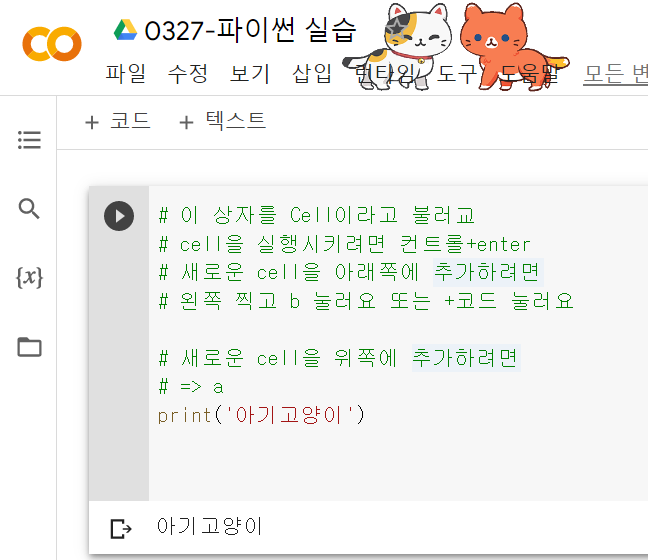
2) 여러 작성법을 알아보자

# python의 built in data type
# 1. Numeric(숫자)
# - 정수
# - 실수
# 2. Sequence
# 3. Text Sequence
# 4. Mapping
# 5. Set
# 6. Bool# 1. Numeric(숫자)
# 정수, 실수, 복소수, 진수
a = 123 #정수
b = 3.141592 #실수
print(type(a)) #class 'int'
print(type(b)) #class 'float'
result = 3/4 #java인 경우 0
print(result) # python은 3.75
# slicing => 슬라이싱은 원본과 결과본의 데이터 타입이 같아요
# print(myList[0:2]) # 슬라이싱의 앞쪽은 포함이고 뒤쪽은 불포함이에요 [ 1, 2 ]
# print(myList[0:1]) # [1] 그냥 1이 아니고 list 1이 나옴
# print(myList[1:]) # [2, 3, [3.14, 2.25, 100], 4, 5] 뒤에 숫자 없으면 끝까지
# print(myList[:2]) # [1, 2] 처음부터 1까지
# print(myList[:]) # 첨부터 끝까지# list의 연산
a = [1,2,3]
b = [4,5,6]
c = a+b
# print(c) # [1, 2, 3, 4, 5, 6] 리스트의 연결
c = a*3 #a+a+a
print(c) # [1, 2, 3, 1, 2, 3, 1, 2, 3]# list는 객체
# 많은 메소드를 가지고 있다
a = [1, 2, 3]
# a.append(4)
# print(a) #[1,2,3,4]
# a.append([4,5]) #맨끝에 밀어넣는거
# print(a) # [1, 2, 3, [4, 5]]# Sequence built in data type 에 대해 알아보고 있어요
# 1. list
# 2. tuple
# 3. range
# tuple은 기본적으로 list와 동일. 그런데 tuple은 read only!
# tuple은 literal로 ()을 이용해요
a = tuple() # literal이 아니라 class를 이용해서 객체를 생성
a = (1,2,3,4) # tuple
# print(type(a)) # <class 'tuple'>
a = (1,) # 요소가 1개짜리 tuple
a = (1,2,3,4)
# print(a[2]) # 3
# print(a[2:3]) # (3,) 결과는 같지만 요소 하나짜리 튜플
# a[3] = 100 # read only 튜플의 값은 바꿀 수 없음
# a = (1,2,3,[4,5,6],7) # 튜플 내 list의 요소는 바꿀 수 있음
# a[3][1] = 100
# print(a)
a = (1, 2, 3)
# tuple은 기호를 생략할 수 있어요
# a = 1,2,3
#a, b, b = 1, 2, 3 # a=1,b=2, c = 3
# 설명한 내용을 제외한 나머지 특성은 모두 list와 유사
a = (1,2,3)
b = list(a)
print(b) #[1, 2, 3]range
# Sequence built in data type 에 대해 알아보고 있어요
# 1. list
# 2. tuple
# 3. range => literal로 쓰지 않아요
a = range(10) # 시작은 0부터 시작, 10까지 1씩 증가하는 숫자의 범위
print(a) # range(0, 10)
# 메모리 낭비될 수 있기 때문에 list와 tuple보다는 range라는 개념으로 갖고 있는다
a = range(2, 20, 2) # 0시작과 1 증가가 default이나, 2부터 2씩 증가해서 20보다 적은 숫자의 범위로 표현# 3. Text Sequence
# 문자열
# literal '',"" 둘 다 사용 가능(default는 '')
# a = '고양이 귀여워'
# print(type(a)) #<class 'str'>
# Text Sequence는 실제로 list
# list의 성질을 그래도 이어받아요
a = '장'
b = '치롱'
print(a+b) # 장치롱문자열도 슬라이싱이 가능
a = '이것은 소리없는 아우성'
# 문자열도 슬라이싱이 가능
# print(a[0]) # 이
# print(a[0:]) # 이것은 소리없는 아우성
# 기억해야 할 특이한 연산자 한개가 있어요
print('소리'in a) # True (자바는 true, 파이썬은 True)
# 문자열은 str class의 객체에요. 그러다보니 굉장히 많은 method를 가지고 있어요
print('이것은 소리없는 {}'.format('아우성')) # 이것은 소리없는 아우성 , 변할 수 있는 부분을 중괄호로 표현
print('이것은 {}없는 {}'.format('소리','아우성'))mapping
# 4. Mapping
# 우리가 흔히 알고 있는 Map 구조(키와 value로 데이터를 저장하는 구조)
# 파이썬에서는 이런 자료 구조를 dictionary라고 불러요
# 당연히 사용하는 class는 dict
# literal로 표현할 수 있어요 => {} : dictionary
# [] : list, () : tuple
a = {'name':'홍길동',
'age':20}
# print(type(a)) # <class 'dict'>
# 자바와 다르게 파이썬의 딕셔터리는 동적으으로 데이터를 추가할 수 있어요
a['주소'] = '서울'
# print(a) # {'name': '홍길동', 'age': 20, '주소': '서울'}
print(a.keys()) # dict_keys(['name', 'age', '주소'])
# 생긴것만 보면 key들을 모아서 리스트로 만들어서 리턴하는거 같아요
# 하지만 진짜 list는 아니고 list와 유사한 자료구조
# 일반적으로 for문을 이용할 때 이런걸 사용해요
# for ~ in ~(리스트, 튜플, list와 유사한 자료구조)
for tmp in a.keys():
print(tmp)
print('호호')
# name
# 호호
# age
# 호호
# 주소
# 호호Anaconda 세팅
❗Anaconda 설치해보자
Anaconda platform
하고자 하는 목적에 따라 각 공간을 따로 잡음
설정방법
1) 가상공간을 생성
data_env라는 공간에 파이썬 3.8버전
2) 공간에 이것저것 설치
① numpy설치
② pandas를 이용해서 데이터 분석
③ matplotlib
3) 개발환경 설치
4) c드라이브에 폴더 만들기
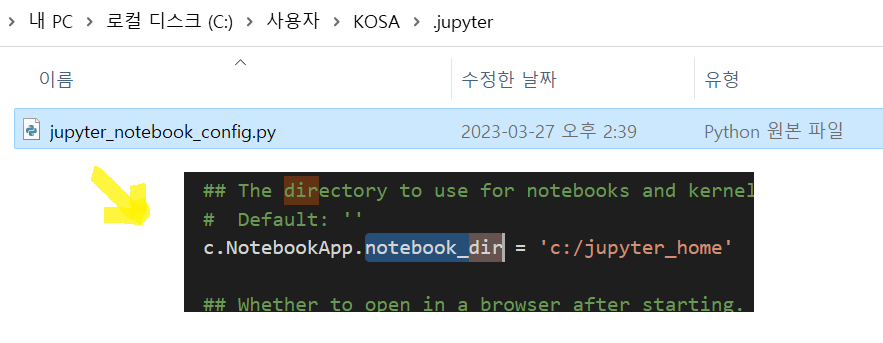
5) 설정파일 생성
- 생성된 파일안에 경로를 지정해주자




Set
# 5. Set
# 우리가 알고 있는 그 Set 이에요
# 순서가 없어요. 중복 배제
# literal로 Set은 => {}
# [], {}(key와 value의 쌍으로 표현), ()
a = {1,2,3,4,1,2,3}
print(a) #{1, 2, 3, 4}
print(type(a)) # <class 'set'>Control statement
# 3. Control statement
# 제어문 (if,for)
area = ['서울','부산','제주']
if '서울' in area:
pass #아무것도 안쓰면 문법적인 오류. 넘어가자는 의미
else:
print('지역에 없어요')# for문
# for문은 2가지 형태로 많이 사용돼요
# 1. for ~ in range()
# 2. for ~ in list, dict
# 반복할 횟수를 명시적으로 지정할 때 많이 사용
# print() : 인자로 들어온 문자열을 출력하고 한줄을 띄워요
# for test in range(5):
# print(test) # 1235 한줄씩 출력됨
# print(test, end='@') # 0@1@2@3@4@
a = ['ㅇㅇㅇ','ㄴㄴㄴ','ㄷㄷㄷ']
for name in a:
print(name)# 함수는 어떻게 만드나요?
# JavaScript
# function myFunc(){
# }
# Java
# 함수가 없어요 클래스 안에 메소드가 있어요
# class{ }
# python에서는 함수를 만들 수 있어요
def myFunc(a,b,c):
return a+b+c
result = myFunc(10,20,30)
print(result) # 60Numpy
# 이제부터 numpy에 대해 알아보자
# 여기서부터는 약간의 코드와 함께 이해를 동반해야함
# 데이터분석, 머신러닝, 딥러닝 이런 분야를 할때
# 가장 시간이 많이 걸리고 잘 해야하는게 무엇일까?
# 데이터 수집과 정제
# Numpy(numerical python)
# pandas(데이터 분석 module)와 metaplotlib(시각화)의
# base가 되는 기본 자료구조를 제공
# numpy는 딱 1개의 자료구조를 우리에게 제공
# ndarray 자료구조를 제공
# n-dimensional array 다차원 배열
# 보다 적은 메모리를 필요로 하고 훨씬 더 빠른 처리를 할 수 있어요
# numpy는 외부 module이기 때문에 당연히 설치해야해요
# conda install numpy
# 설치했으면 그냥 막 쓸 수 있나요?
import numpy as np
a = [1,2,3,4,5] # python의 list
print(a) # [1, 2, 3, 4, 5]
b = np.array([1,2,3,4,5])
print(b) # [1 2 3 4 5]
print(type(b)) # <class 'numpy.ndarray'>
# 기억해야하는 특징이 있어요
# list 안에는 아무거나 막 들어올 수 있어요
c = [1, 3.14, '홍길동', True]
# ndarray는 반드시 같은 데이터 타입끼리만 들어올 수 있어요
d = np.array([1,2,3.14,4,5])
print(d) # [1. 2. 3.14 4. 5. ] 실수화 된다
print(d.dtype) # float64 dtype은 d안에 들어있는 데이터 타입의 속성# ndarray가 list와 가장 크게 차이가 나는건
# 차원을 표현할 수 있다는것
import numpy as np
myList = [[1,2,3],[4,5,6]] #중첩 리스트
print(myList)
arr = np.array(myList)
print(arr)
# [[1 2 3] 차원으로 표현
# [4 5 6]]
print(arr[0,1]) # 0행 1열 = 2
print(arr[0]) # 0행 [ 1 2 3 ]
print(arr[0][1]) # 2# 중요한 속성이 있어요
# 1차원 ndarray를 하나 만들어보아요
arr = np.array([1,2,3,4])
print(arr) # [1 2 3 4]
print(arr.dtype) # int32
print(arr.ndim) # arr몇차원이야? 1
print(arr.shape) # (4,) 튜플의 원소수는 차원수이고 각 차원의 숫자는 해당 자원의 요소수
b = [[1,2],[3,4],[5,6]]
arr = np.array(b)
print(arr.shape) # (3, 2) 3행 2열 이라는 뜻😵💫 x.x

지니야 코딩 해줘