ResNet이라고 불리는 "Deep Residual Learning for Image Recognition" 논문에 내용이다.
Abstract
기존의 깊은 뉴런 네트워크는 학습하기 어렵다. Residual Learning 즉, 잔여 학습을 통해서 학습을 더 쉽게 하고 정확도도 더 높은 모델을 만드는 것이 이 논문의 핵심이다. 실제로 잔여 학습을 통해 ImageNet Test set에서 3.57%의 에러를 줄일 수 있었고, COCO dataset에서도 28%의 기능 향상을 얻을 수 있었다. ResNet은 ImageNet detection, ImageNet localization, COCO detection, COCO segmentation에서 1위를 차지했다.
Introduction
이 연구는 "Is learning better networks as easy as stacking more layers?" 에서 시작된다. 우리는 통상적으로 layer를 깊게 쌓으면 쌓을수록 좋은 결과를 갖는 모델이라고 생각한다. 하지만 실제로는 그렇지 않다.
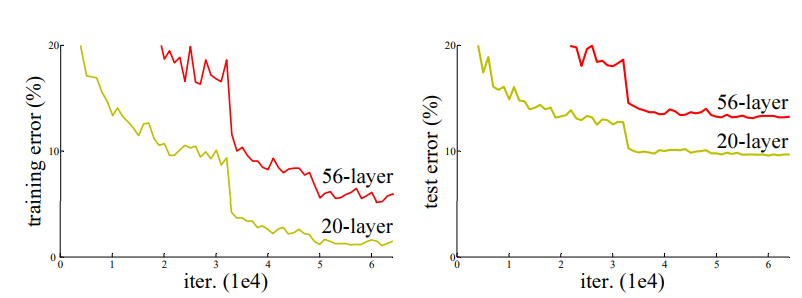
위에 그림을 보면 더 깊은 layer를 가진 56-layer가 더 적은 20-layer에 비해서 training과 test 모두 더 높은 error를 갖는 것을 알 수 있다. 이 문제를 Degradation problem으로 정의하고 있다. 이 논문에서 말하는 Degradation Problem이란 network depth가 증가하면 증가할 수록, accuracy가 saturated되고 성능이 급격히 저하되는 것을 의미한다. (saturated: Activation Function의 구간에서 기울기(gradient)가 0에 가까워지는 현상 -> vanishing gradient를 야기함) 이 문제는 단순히 'overfitting' 때문에 발생하는 문제는 아니라고 얘기하며, 더 많은 layer를 쌓은 deep model이 더 높은 error를 갖는다고 주장한다.
*56-layer가 overfitting이 아닌 이유는 training error와 test error가 모두 낮기 때문.
Degration은 모든 시스템이 optimize하기 쉽지 않다는 것을 나타내므로 shallow architecture와 deep architecture를 비교하려고 한다.학습된 shallow architecture에 identity mapping을 추가하여 단순히 깊게 쌓는 deep architecture를 만들었지만 좋은 solution이 아님을 알았다.
따라서 위 논문에서는 "Residual Learning"이라고 하는 잔여학습 내지 잔차학습이라는 개념을 도입한다.
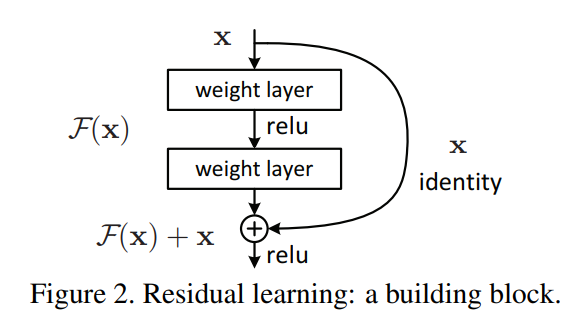
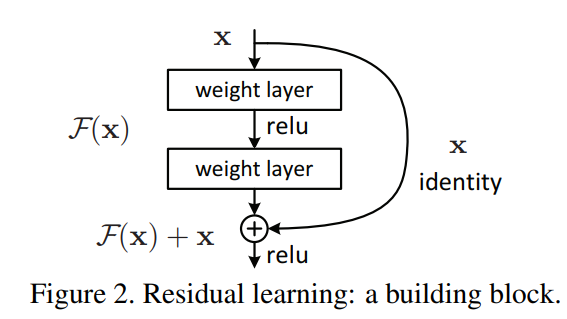
위 그림이 Residual learning을 의미한다. 기존 mapping인 H(x)를 새롭게 정의하여 F(x) := H(x) - x 즉, H(x) := F(x) + x로 mapping하게끔 만든다. 이 residual mapping이 기존의 mapping보다 optimize하기 더 쉬운 것으로 가정한다.
F(x) + x를 "shortcut connection"이라고도 칭하는데, 이는 위 그림과 같이 하나 또는 그 이상의 layer를 건너뛰기 때문이다. 여기서는 단순히 Shortcut connection을 identity mapping을 수행하도록 만들었다.
Shortcut connection은 추가적인 parameter도 computational complexity도 필요하지 않다는 것이 장점이다.
Related Work
Residual Representations와 shortcut connection에 대한 얘기와 관련 다른 논문들에 대한 내용이다.
Deep Residual Learning
Residual Learning
여러개의 비선형 layer들이 점근적으로 complicated function으로 근사 할 수 있다고 가정하면, 그 layer들이 점근적으로 residual function인 H(x)-x를 근사 할 수 있다고 가정하는 것과 같다. 이는 H(x)를 근사할 수 있다면 F(x)인 H(x)-x를 근사하는 것이 가능하다는 얘기이다.
Identity Mapping by Shortcuts
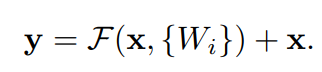
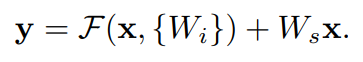
위 논문에서 정의한 building block이다. 2개의 layer인 를 정의한 식이다. (이때, 는 ReLU) 또한 위 식은 x와 F의 dimension이 동일할 때를 의미한다. 만약 dimension이 서로 다르면 아래와 같은 식을 이용해서 dimension을 갖게 만들어준다. (가 dimension을 갖게 만들어주는 역할, projection )
Network Architectures
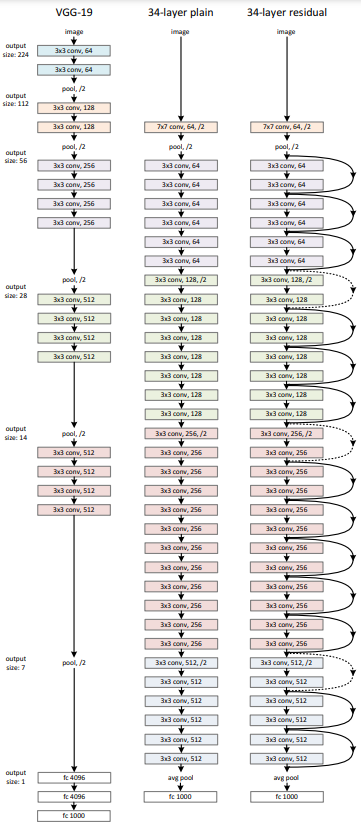
VGG를(위 그림에서 왼쪽) 이용해서 Plain Network를 만들었다. (위 그림에서 가운데)
Conv layer들은 대부분 3x3 filter를 가지며, 동일한 size의 feature map을 갖기 위해서 layer들은 같은 filter 수를 갖게 했다. feature map size가 절반이 되면 filter의 수를 2배로 키워 layer마다 time complexity를 유지했다. stride가 2인 Conv layer를 이용해서 downsampling을 진행했으며 1000개의 class분류를 위해 FC1000을 softmax로 구성하였다.
이와 비교하여 Residual Network도 구성하였는데, 위에서 만든 Plain Network를 기반으로 하여 shortcut connection을 추가하여 만들었다.(위 그림의 오른쪽)
Identity Shortcut은 input과 output이 같은 dimension일 때 바로 사용이 가능하다. 만약 차원이 증가한다면
(A) dimension을 증가시키기 위해서 zero-padding하기; 추가 parameter 없음
(The shortcut still performs identity mapping, with extra zero entries padded for increasing dimensions. This option introduces no extra parameter)
(B) dimension을 같게하기 위해서 위에서 언급한 projection shortcut () 사용하기.
(The projection shortcut in Eqn.(2) is used to match dimensions (done by 1×1 convolutions). For both options, when the shortcuts go across feature maps of two sizes, they are performed with a stride of 2)
Experiments
ImageNet Classification
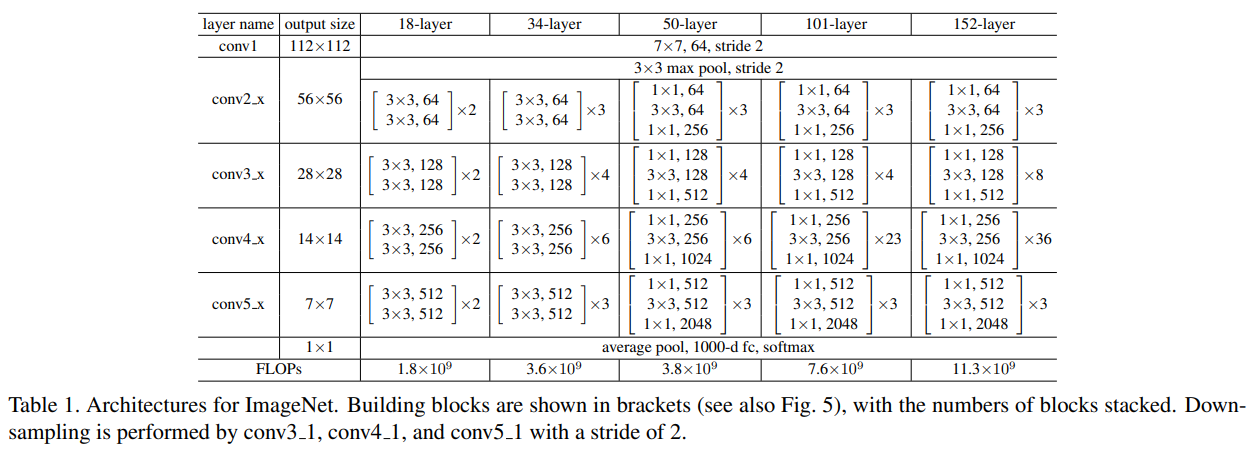
ImageNet에서 사용된 Architecture이다. conv3_1, conv4_1, conv5_1에 의해서 downsampling된다.
Plain Network와 Resiudal Network 모두 18-layer와 34-layer를 사용하였다.
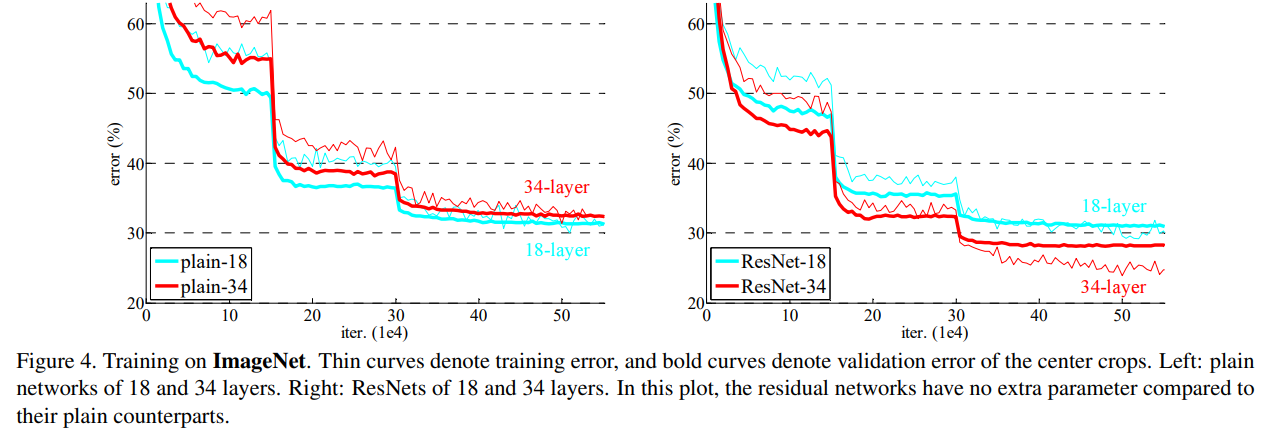
위 그래프는 ImageNet에서 training한 결과이다. 왼쪽이 Plain Network, 오른쪽이 Residual Network이며, 얇은 곡선은 training error를, 굵은 곡선은 validation error를 나타낸다.
Plain Network에서 shallow architecture인 18-layer가 deep architecture인 34-layer보다 error가 더 낮은 것을 알 수 있다.
반면에 Residual Network에서는 더 deep한 34-layer의 error가 더 낮은 것을 알 수 있다.
Plain Network는 Batch Normalization(BN)으로 학습되기 때문에 forward propagated signal이 non-zero varience를 갖도록 보장한다. 다시 얘기해서 optimization이 어려운 이유는 vanishing gradient 때문이 아니다.
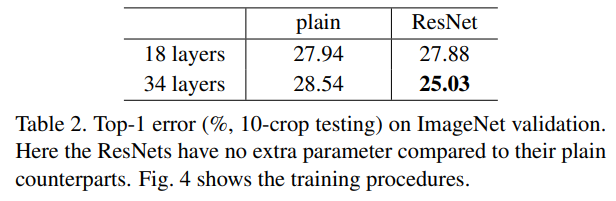
위 Table과 그래프 그림을 통해서 3가지 주요한 관측 결과를 알 수 있다.
-
위에서 얘기했듯이 18-layer ResNet보다 34-layer ResNet의 성능이 더 좋은 것을 알 수 있다. 이를 통해서 더 깊은 network일 수록 더 좋은 성능을 낸다는 우리들의 통념을 깨지 않는다. Depth가 증가할수록 accuracy가 증가하였으므로, degration problem을 잘 조절했음을 알 수 있다.
-
Plain Network와 비교했을 때, 34-layer ResNet은 3.5%의 error 감소를 보인다. 같은 layer에서도 더 좋은 성능을 보였다는 의미이다.
-
18-layer들끼리 비교했을 때(not overly deep), 성능은 비슷하지만 ResNet Network가 더 빨리 수렴하는 것을 알 수 있다. 이는 Stochastic Gradient Descent(SGD)를 사용한 ResNet이 optimization을 쉽게 한다.
Identity vs Projection Shortcut
Parameter-free(Identity shortcut)와 projection shortcut에 대한 비교
(A) zero-padding shortcuts are used for increasing dimensions, and all shortcuts are parameterfree
-> 차원 증가를 위해서 추가 parameter없이 zero-padding사용
(B) projection shortcuts are used for increasing dimensions, and other shortcuts are identity
-> 차원 증가를 위해 projection shortcut()사용, 다른 shortcut들은 identity 사용
(C) all shortcuts are projections
->모든 shortcut들이 projections
결과적으로는 C, B, A 순으로 성능이 좋다. (C > B > A)
A는 residual learning이 이루어지지 않기 때문에 성능이 낮다.
Projection shortcut에 사용되는 extra parameter때문에 B보다 C가 더 좋다고 한다. 하지만 model이 복잡해지는 것을 막기 위해서 이 논문에서는 사용하지 않았다. 대신에 BottleNeck Architecture를 사용하였다.
Deeper Bootleneck Architectures
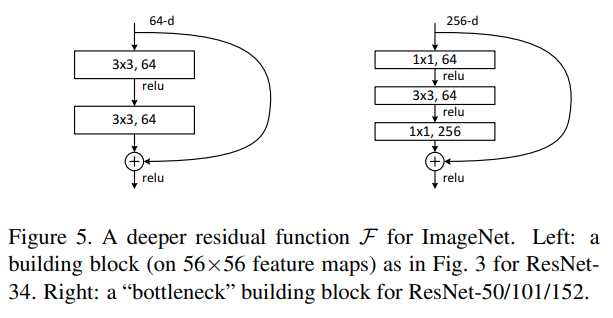
18, 34-layer에서는 왼쪽 그림인 building block을 사용하였고, 50, 101, 152-layer에서는 오른쪽 그림인 "bottleneck" building block을 사용하였다.
Residual Function F를 1x1 -> 3x3 -> 1x1 순서로 block을 구성한다.
첫 번째 1x1 filter에서는 256의 dimension을 64개의 dimension으로 차원 축소를 하는 과정이고 이후 3x3 filter로 공간적인 특징 추출을 진행한다. 이후 다시 1x1 filter로 256개의 dimension으로 확장하는 과정을 진행한다.
다시 한 번 자세히 설명하자면, 1x1 filter의 개수만큼 channel이 생기는데, 여기서 64개이므로 channel이 강제적으로 64개로 축소가 된다. 축소하는 이유는 연산량을 줄이기 위해서이다. 이후, 3x3 convolution으로 공간적인 특징을 추출하고, 이후 원래 dimension인 256으로 확장한다.
이는 연산량을 최소화하기 위해서 사용하는 방법이며 결과적으로 parameter의 수를 감소시키는 효과를 갖는다. 따라서 연산 시간 감소 성능을 얻을 수 있다. (Because of concerns on the training time that we can afford, we modify the building block as a bottleneck design.)
Comparisons with State-of-the-art Methods
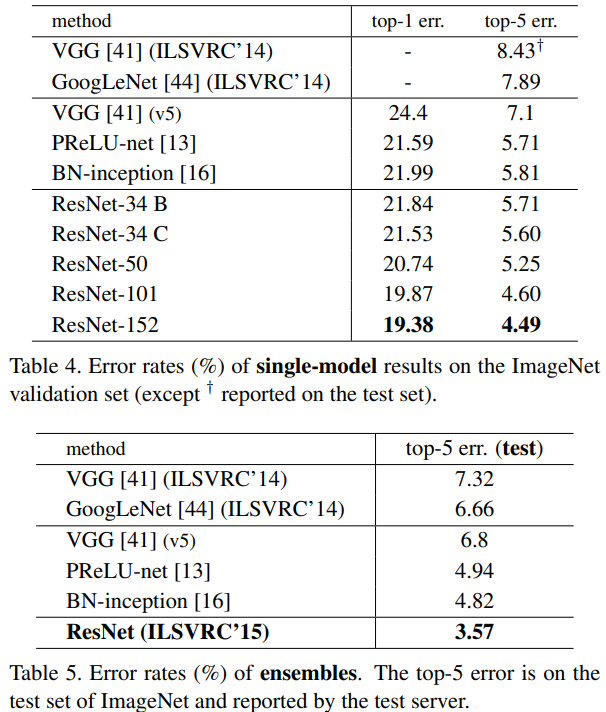
단독으로(single) 사용했을 때와 앙상블(ensembles)기법으로 사용했을 때의 error를 나타낸 것이다. 위에서 만들었던 6가지의 모델을 앙상블 했을 때, 3.57%의 에러를 갖는 것을 확인할 수 있다.
CIFAR-10, Object Detection on PASCAL and MS COCO 위 두 data에서도 잘 적용됐으며 좋은 결과를 얻었음을 알 수 있다.
Conclusion
이 실험은 "과연 깊은 model일수록 성능이 항상 더 좋을까?"에 대한 생각으로부터 출발하였다. 실제로 깊을수록 성능은 그만큼 좋지 않거나 떨어지는 경향이 있다. 이를 극복하기 위해서 Residual Learning()을 도입했고 이를 이용한 Residual Network를 만들었다.(ResNet)
Shallow한 model에는 그냥 block을 사용했지만 50-layer부터 deep한 model에는 "bottleneck block"을 사용하였다. 이는 계산량을 줄이기 위해서 도입되었으며 실제 결과도 그러한 것을 확인할 수 있다.
각 종 실험결과, residual learning을 활용한 ResNet이 VGG를 바탕으로 만든 Plain Network보다 더 좋은 성능을 갖는 것을 확인하였으며, 깊은 model일수록 성능이 더 좋은 것도 확인되었다. Ensemble 기법을 활용하면 성능이 더욱 더 향상되는 것을 알 수 있다.

정말 유익해요