OLAP vs OLTP
| Aspect | OLTP | OLAP |
|---|---|---|
| Primary goal | Execute transactions | Analyze data |
| Query type | Short, simple (INSERT, UPDATE, SELECT) | Long, complex (JOIN, GROUP BY, aggregations) |
| Data volume | Small per transaction | Very large datasets |
| Read/Write pattern | Frequent reads & writes | Mostly read-only |
| Latency | Milliseconds | Seconds to minutes |
| Concurrency | Very high | Low to medium |
| Transactions | Full ACID support | Usually limited or none |
| Schema design | Highly normalized (3NF) | Denormalized (Star/Snowflake) |
| Storage layout | Row-oriented | Column-oriented |
| Index usage | Many indexes | Minimal indexes |
| Typical workload | User actions, payments | Reports, dashboards, analytics |
Data Storage
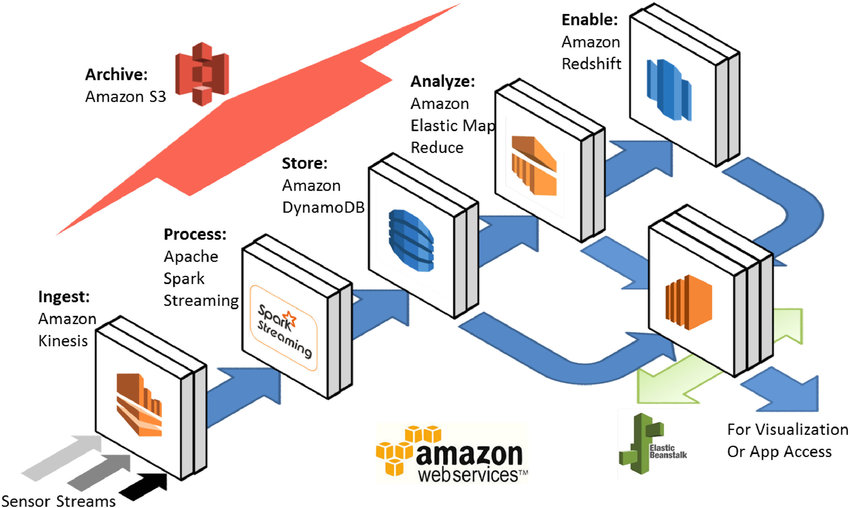
S3 is in a Data Lake Layer
Redshift is in a Data warehouse layer
Hadoop Ecosystem vs AWS
| Hadoop Component | Role | AWS Equivalent | Notes |
|---|---|---|---|
| HDFS | Distributed file system | Amazon S3 | De facto replacement for HDFS |
| YARN | Resource & job scheduling | EMR / EKS / ECS Plane | |
| MapReduce | Batch processing engine | EMR (legacy) | Mostly replaced by Spark |
| Hive | SQL on Hadoop | Amazon Athena | Presto-based SQL engine |
| Hive Metastore | Metadata catalog | AWS Glue Data Catalog | Shared metastore |
| Spark | Distributed compute engine | EMR / Glue / EKS | Glue = serverless Spark |
| HBase | Wide-column NoSQL | DynamoDB | Conceptual equivalent |
| Kafka | Streaming platform | MSK / Kinesis | |
| Flume | Log ingestion | Kinesis Firehose | |
| Sqoop | RDBMS ↔ HDFS transfer | AWS DMS | |
| Oozie | Workflow scheduler | Step Functions | |
| ZooKeeper | Distributed coordination | Self-managed | No direct AWS replacement |

Cloud Security, Pentesting, AWS