
이벤트 버스와 카프카의 성능 비교를 공부하던 중 제로 카피가 무엇인지 궁금하여 정리한 내용입니다.
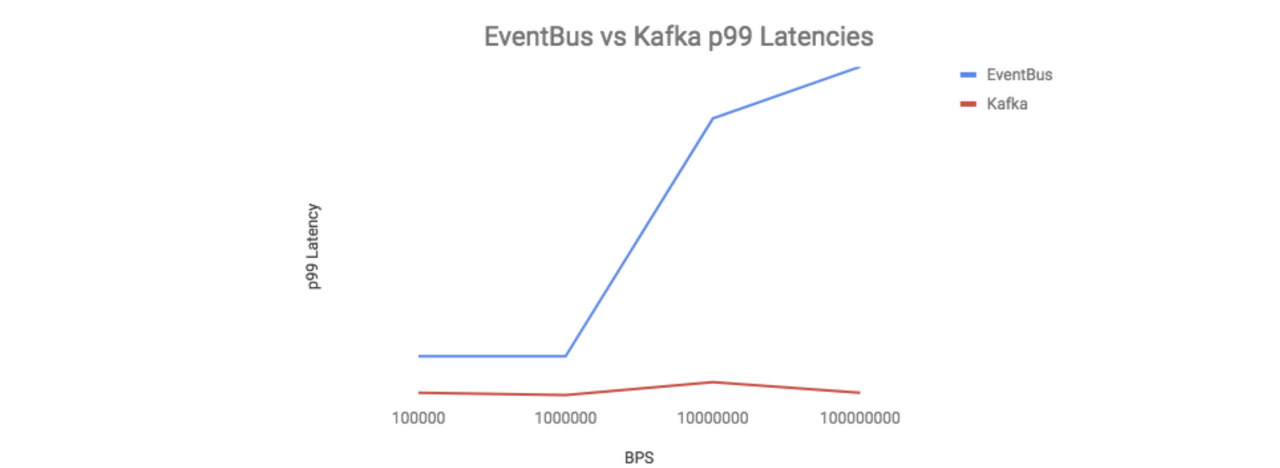
“카프카는 이벤트버스와 달리 BPS와 상관없이 지연이 거의 발생하지 않음을 알 수 있습니다.
이러한 성능 차이를 보이는 이유로,
- 이벤트 버스는 서빙 레이어와 스토리지 레이어가 분리되어 있어 추가적인 홉이 필요하지만 카프카는 하나의 프로세스에서 스토리지와 요청을 모두 처리한다는 차이가 있었습니다.
- 또한 이벤트 버스는 fsync()를 하는 동안 블로킹을 하는 반면, 카프카는 OS에 의존해 백그라운드로 fsync()를 처리하고 제로카피를 사용했습니다.
- 결과적으로 이벤트 버스를 운영하려면 더 많은 하드웨어를 필요로 하는 반면에 카프카는 이벤트 버스 만큼의 많은 하드웨어가 필요치 않았습니다. “
카프카는 서버의 성능 개선을 위해 제로카피 기법을 사용했다.
일반적인 파일 전송
파일 서버나 정적 파일을 서비스하는 웹 애플리케이션은 디스크에서 파일 컨텐츠를 읽어 네트워크 소켓으로 데이터를 전송하는 일을 반복적으로 수행한다. 이 동작에는 컨텍스트 스위칭과 데이터 복사가 수반된다.
byte[] applicationBuffer = new byte[1024];
read(fileFd, applicationBuffer, len);
send(socketFd, applicationBuffer, len);버퍼를 할당 받고 디스크에서 파일을 버퍼로 읽어들여서 다시 소켓으로 전송하는 형태이다. 근본적으로 read() 시스템 콜과 send() 시스템 콜이 반복되는 형태이다.
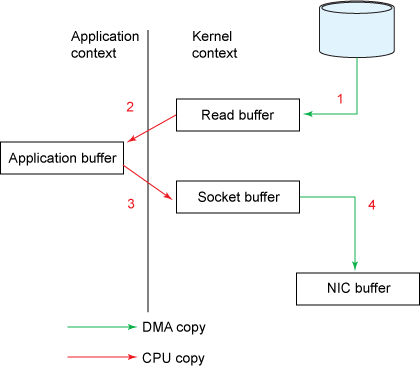
read() 이후 send()를 수행하는 간단한 코드지만, 4번의 컨텍스트 스위칭과 4개의 메모리 복사본이 생기게 된다.
1) 유저가 read() 시스템 콜을 호출해 파일을 읽어달라고 하면 DMA 엔진에 의해 디스크에 존재하는 파일의 내용이 커널 주소 공간에 위치한 Read buffer에 복사된다.
2) 커널 주소공간에 위치한 Read Buffer는 사용자가 접근할 수 없어서 read() 함수 호출시 파라미터로 전달한 Application buffer에 Read Buffer의 내용을 복사한다. 복사가 완료되면 함수 호출에서 리턴한다.
3) 사용자는 ApplicationBuffer로 읽어들인 데이터를 소켓으로 전송하기 위해 send() 함수를 호출한다. send() 함수 호출시 Application Buffer를 파라미터로 전달하면 커널 영역에 위치한 SocketBuffer로 데이터를 복사한다.
4) Socket Buffer에 있는 데이터는 실제 네트워크로 전송하기 위해 네트워크 장비 (NIC)에 있는 버퍼로 다시 복사된다.
위와 같은 작업인 버퍼링은 본래 메모리와 디스크, 메모리와 네트와크 장비 사이의 속도 차이를 만회하고자 만들어진 성능 개선 장치이다. 예를 들어 1KB 정도의 작은 데이터를 파일에서 읽으면 커널을 1KB 이후 데이터까지 한번에 읽어서 페이지 캐시에 로드한다. 이 후 그 다음 데이터를 요청하면 물리적인 I/O를 수행하지 않고 페이지 캐시에서 읽어서 사용자에게 준다. 데이터를 미리 읽어서 성능 개선을 도모한 것
하지만 이런 버퍼링은 성능 저하를 유발하는 병목으로 작용할 수 있다. 사용자가 요청하는 데이터의 크기가 커널이 유지하는 버퍼의 사이즈보다 큰 경우 미리 읽는 성능 개선 효과보다 여러 단계에 걸쳐 데이터를 복사하는 비효율이 더 커진다.
또한 시스템콜을 수행하기 위해 유저모드와 커널모드를 오가는 컨텍스트 스위칭이 발생하게 된다. 컨텍스트 스위칭을 수행 정보들을 백업하는 등의 오버헤드를 수반한다. 파일에서 읽어 소켓으로 전송하는 동작은 read() 함수의 호출과 반환, 소켓으로 데이터를 전송하는 send() 함수의 호출과 반환 등 총 4번의 컨텍스트 스위칭을 발생시킨다.
제로카피는 이런 비효율적인 동작을 개선하기 위해 소개된 기법이다.
제로카피 동작
리눅스 2.2 버전에서 처음 소개된 sendfile() 시스템 콜이 제로카피 동작을 구현했다.
#include<sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t * offset ", size_t" " count" );자바에서는 nio 패키지의 transferTo(), transferFrom() 메소드로 구현되어 있다.
public void transferTo(long position, long count, WritableByteChannel target);
cs자바의 transferTo(), transferFrom() 메소드 역시 sendfile() 시스템 콜을 이용해 구현되었다.
toChannel.transferTo(position, to, toChannel);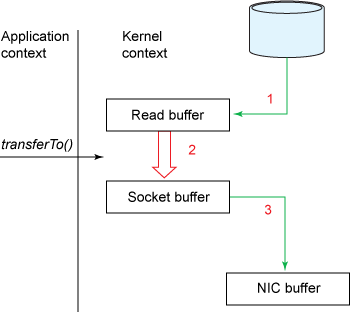
read(), send() 두번의 시스템콜이 transferTo() 한번의 호출로 가능해졌다.
1) 사용자가 transferTo() 메서드를 통해 파일 전송을 요청한다. read()와 send() 함수가 하나로 합쳐진 형태의 시스템 콜이다. read() 시스템콜과 마찬가지로 DMA 엔진이 디스크에서 파일을 읽어 커널 주소 공간에 위치한 Read buffer에 데이터를 복사한다.
2) 커널 모드에서 유저 모드로 컨텍스트 스위칭 하지 않고 바로 Socket buffer로 데이터를 복사한다.
3) Socket buffer에 복사된 데이터를 DMA 엔진을 통해 NIC buffer로 복사되어 진다.
4) 데이터가 전송되고 transferTo() 메소드에서 리턴한다.
이 모든 동작이 transferTo() 메서드 내에서 발생했고 컨텍스트 스위칭이 4번에서 2번으로 줄었다 .
transferTo() 메서드 호출시 커널모드로 한번, 종료시 유저모드로 한번 총 2번의 컨텍스트 스위칭이 발생한다.
또 이 동작들이 유저 주소 공간에 있는 Application Buffer로 복사되어 지지 않기 때문에 데이터의 복사본이 4군데에서 3군데로 줄었다. 따라서 데이터를 복사하는 동작도 한번 줄었다. 컨텍스트 스위칭 회수와 복사본의 개수가 줄어든만큼 CPU 자원의 낭비가 줄어들게 되어 성능이 향상된다.
더 개선된 제로카피
리눅스 커널 2.4 이후부터는 NIC 장비가 “Gather Operation”을 지원할 경우 복사본을 더 줄일 수 있다.
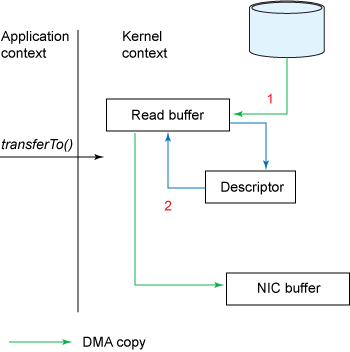
1) 사용자가 transferTo() 메서드를 호출한다. DMA엔진이 디스크에서 파일을 읽어 커널에 위치한 ReadBuffer로 데이터를 복사한다.
2) 데이터가 소켓 버퍼로 복사되어지지는 않는다. 대신 데이터가 저장된 위치와 데이터 사이즈에 대한 정보와 함께 디스크립터가 소켓 버퍼에 추가된다. DMA 엔진은 이 정보를 이용해 ReadBuffer에 있는 데이터를 NIC에 바로 복사하고, 네트워크로 데이터를 전송한다.
이러한 추가적인 최적화는 gather operation과 프로토콜의 checksum 기능이 필요하다. TCP, UDP의 경우 checksum 기능이 구현되어 있다.
성능상 이점
리눅스 2.6 커널 버전에서의 성능 비교
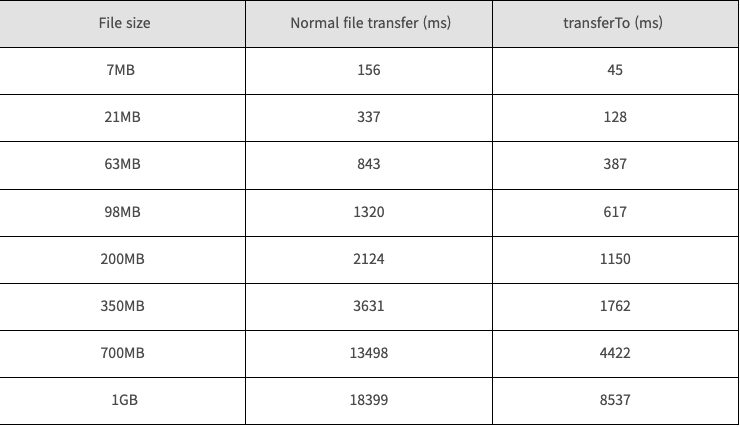
수행시간이 약 65% 줄어든 것을 확인할 수 있다.
요약
디스크에서 파일을 읽은 후 별다른 처리 없이 바로 네트워크로 전송하는 파일 서버나 정적 파일을 전송하는 웹 서버의 경우 제로카피를 사용하면 성능 개선 효과를 얻을 수 잇다. 특히 네트워크 속도가 매우 빨라서 성능상 병목점이 CPU로 몰릴 수 록 불필요한 데이터 복사를 제거해 성능 개선을 얻을 수 있다.
디스크에서 파일을 읽고 네트워크로 전달하는 과정에서 read(), send() 두번의 시스템 콜로 인한 컨텍스트 스위칭과 데이터 복사에 따른 성능 저하를 zero copy의 transferTo() 메서드를 통해 하나의 시스템 콜로 컨텍스트 스위칭과 데이터 복사에 필요한 비용을 줄여 성능 개선을 이룬다.
출처:
