(그만 알아보자...)
0. 배경
개발 시작하고 쭉 자바만 써오다가 회사 들어가서 Node.js + typescript를 사용한 지 어언 2달 반...
노드는 싱글스레드 기반으로 실행되며 async / await라는 걸 지원한다는 걸 알기만 했지
실제로 이게 어떻게 돌아가는지 이해도 없이 지금까지 달려왔다.
잠시 한가해진 기념으로 노드의 강력한 특징 중 하나인
non-blocking I/O를 가능케 하는 이벤트 루프에 대해 알아보자.
1. 이벤트 루프란?
가능할 때마다 커널이 필요한 연산을 넘겨 두고 다른 작업을 진행함으로써
Node.js로 하여금 non-blocking I/O를 가능하게 하는 기능
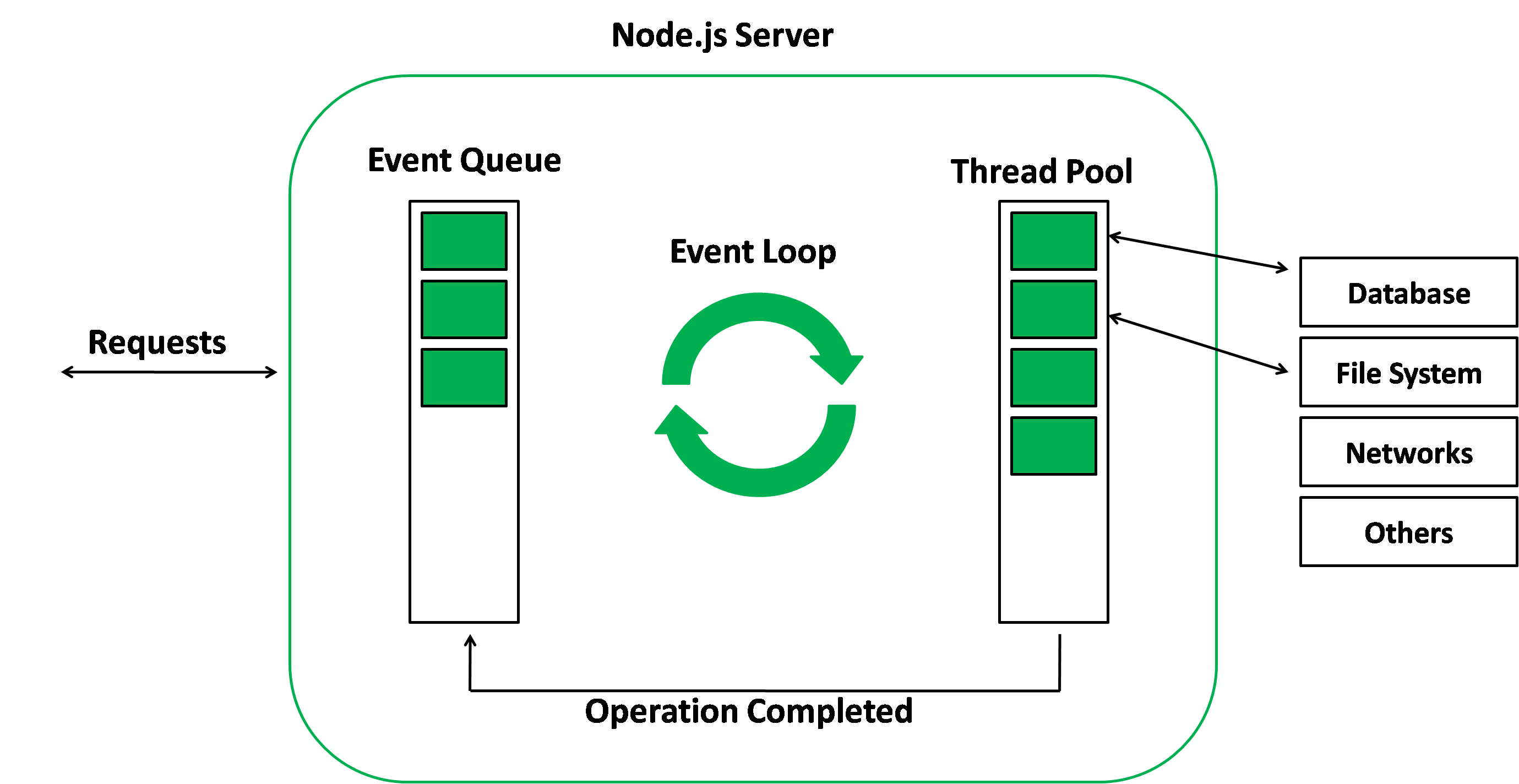
위 사진과 같이 파일 시스템 접근, 네트워크 등과 같이 OS 레벨에서 해야할 일들은 커널 프로세스에서 이뤄진다.
이 작업들이 종료되면 Event Queue(poll queue)에 콜백이 쌓여 이벤트 루프는 잠시 멈췄던 작업을 재개한다.
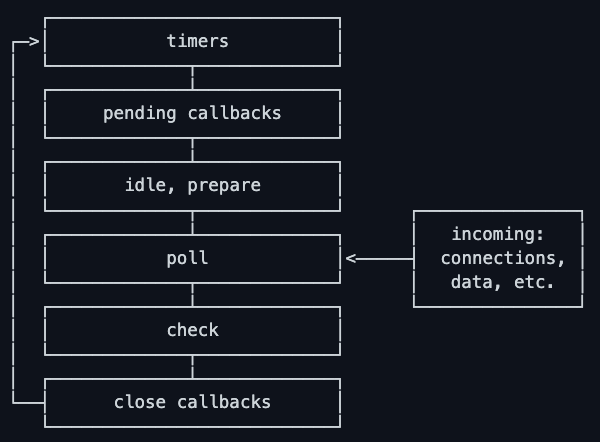
각 박스를 phase라고 칭한다.
각 phase는 콜백 FIFO queue를 가지고 있다.
이벤트 루프는 각 단계에 접어들어 queue에 쌓인 콜백을 처리하기 위한 사전 작업 이후 콜백을 처리한다.
이러한 처리 과정은 큐의 콜백을 모두 소진하거나 정해진 시간을 초과할 때까지 이어진다.
 (이벤트 루프가 콜백을 처리 안해요 😰😰)
(이벤트 루프가 콜백을 처리 안해요 😰😰)
2. phase by phase
timers
timer는 자신의 콜백이 실행될 threshold(임계값)을 설정한다.
그래서 timer는 threshold가 지날 때마다 자신의 콜백을 실행하게 된다.
그러나 커널 작업을 실행하거나 poll queue에 쌓인 콜백을 처리하면서 threshold 값을 넘길 수 있다.
그래서 timer 콜백이 실행되는 주기는 poll phase의 영향을 받을 수 있다.
const fs = require('node:fs');
function someAsyncOperation(callback) {
// 이 작업은 95ms 걸린다고 가정한다.
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`);
}, 100);
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});코드로 살펴보자.
someAsyncOperation()은 파일 경로와 콜백을 인자로 받는 readFile()을 호출한다.
readFile()은 말 그대로 파일을 읽기 때문에 커널의 영역이고, 95ms 걸린다고 가정한다.
setTimeOut()을 호출할 때 두번째 인자로 100ms를 넘김으로써,
100ms의 threshold 값을 가진다.
이때, 이벤트 루프가 poll phase에 진입했다고 가정하자.
그럼 최하단에서 someAsyncOperation()을 호출하는 과정을 거치게 된다.
위에서 살펴보았듯 readFile()을 처리하는 데 95ms가 걸린다.
이때 이벤트 루프는 threshold보다 작은 값이기 때문에 95ms를 기다려준다.
파일을 읽는 커널 작업이 종료되면 poll queue에 콜백이 쌓이게 된다.
이벤트 루프는 이 콜백을 처리하는 데 10ms 걸리기 때문에 결국 105ms가 소모된다.
이제는 threshold를 넘었기 때문에 다시 timers phase로 돌아간다.
즉, setTimeout()에서 기대했던 100ms를 자연스럽게 넘기게 된다.
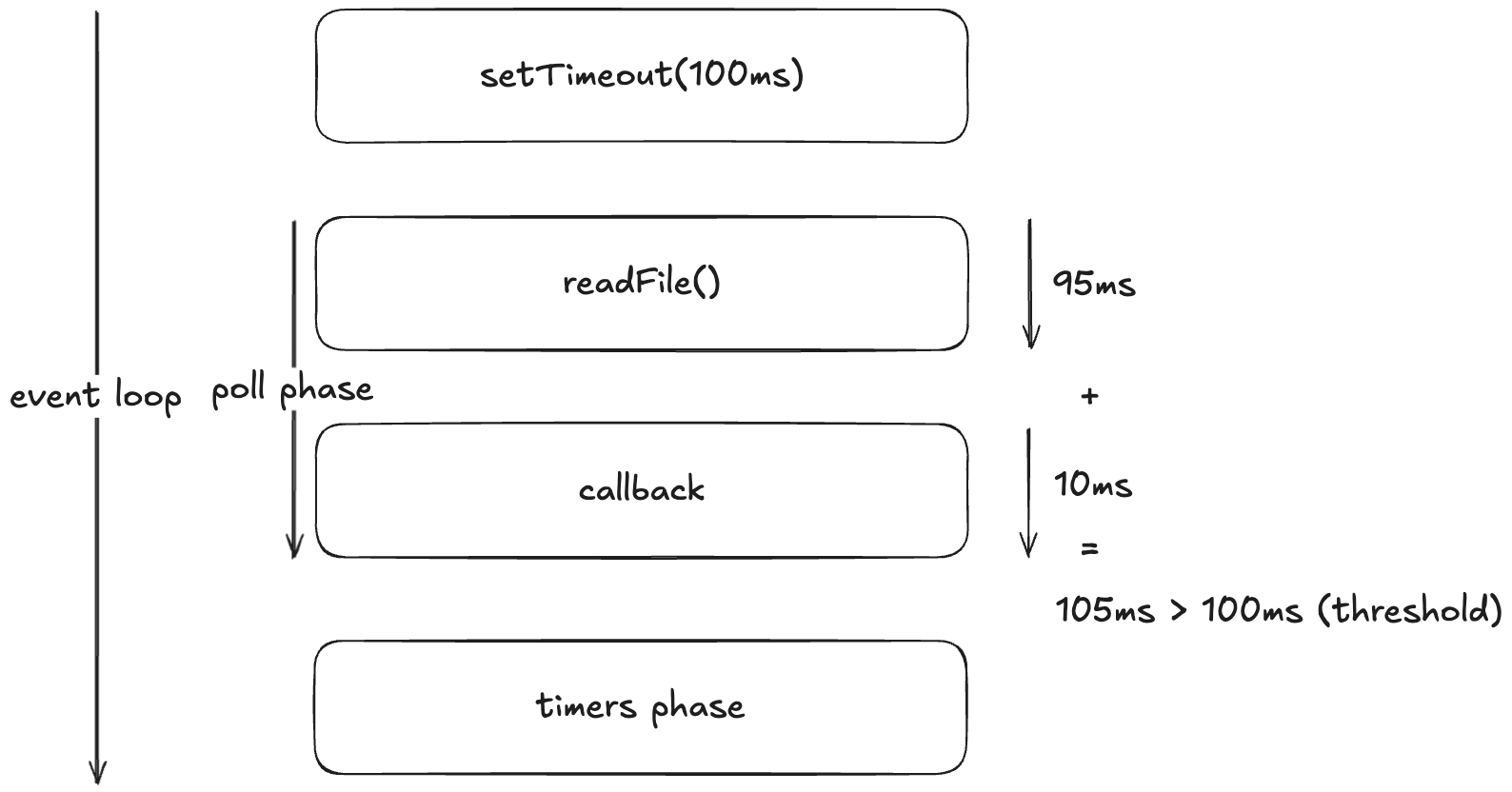
그림으로 표현하면 위와 같다.
pending callbacks
이 phase는 사용자 레벨이 아닌 시스템 레벨의 연산을 처리한다.
예를 들면,
인터넷 연결을 시도하던 중 ECONNREFUSED에 의한 TCP 에러가 발생했다거나
존재하지 않는 경로의 파일을 삭제하려고 시도할 때가 있다.
timers phase처럼 정해진 시간마다 처리해야 하는 것도 아니고
poll phase처럼 I/O 작업과 연관된 콜백 처리가 아니기 때문에 이처럼 독립적인 단계를 가진다.
poll
주요 기능
- 주어진 threshold와 지금까지 지난 시간을 계산하고, 이미 종료된 I/O 작업이 있는지 확인한다.
- poll queue에서 콜백을 꺼내 처리한다.
timer 스케쥴링 없을 때 poll phase
-
poll queue에 콜백이 있다면,
- 이벤트 루프가 queue에서 콜백을 꺼내 동기적으로 하나씩 처리한다.
- queue의 모든 콜백을 소진하거나, 정해진 시간에 도달할 때까지
-
poll queue에 콜백이 없다면,
setImmediate()가 걸려 있다면, poll phase를 마치고 check phase로 드간다.setImmediate()가 없다면, 이벤트 루프는 poll queue에 콜백이 쌓이기를 기다린다.
check
poll phase를 마치자마자 사용자가 정한 콜백을 실행할 수 있게 해준다.
이 콜백은 setImmediate()로 설정할 수 있다.
setImmediate()가 걸려 있으면 위에서 언급했던 것처럼
poll queue에 아무것도 없어 idle한 상태의 이벤트 루프를 다음 phase로 보낼 수 있다.
close callbacks
이벤트 루프가 특정 리소스를 닫는 역할을 한다.
소켓을 예로 들었을 때,
- 만약 소켓이 예기치 못하게 종료되었다면 현재 phase와 관계 없이 즉각 close callbacks phase로 넘어가서 close event가 발생한다.
- 소켓을 정상적으로 종료한다면
process.nextTick()에 의해 현재 phase의 모든 콜백을 처리하고 나서 close event가 발생한다.
3. 심화
setImmediate() vs. setTimeout()
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});위와 같이 아무런 컨텍스트가 없는 상황에서는
두 콜백 중 어느 것이 먼저 호출될 지 알 수 없다.
const fs = require('node:fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});그런데 이 두 콜백 호출이 readFile()이라는 I/O 컨텍스트 안에서 진행된다면,
I/O는 poll phase에서 처리되기 때문에 setImmediate()가 언제나 선행한다고 보장된다.
process.nextTick()
process.nextTick()은 이벤트 루프와 관련이 없다?!
그렇다.
process.nextTick()은 이벤트 루프의 특정 phase에서 처리되는 것이 아니다.
그보다는 이벤트 루프가 어떤 phase에 있는지와 관계없이 현재 작업을 마치고 처리된다.
그렇기 때문에 process.nextTick()을 무분별하게 연속적으로 호출할 경우
이벤트 루프가 poll phase에 진입하지 못해서 I/O를 말라버리게 할 수 있다.
process.nextTick()은 왜 필요한가?
이벤트 루프라는,
말 그대로 정해진 단계를 반복하는 루프를 깨버리는 이 놈을 도대체 왜 만들었단 말인가?
function apiCall(arg, callback) {
if (typeof arg !== 'string')
return process.nextTick(
callback,
new TypeError('argument should be string')
);
}
console.log('hello world')위와 같은 코드가 있다.
apiCall()이 의도하는 바는 arg의 타입이 문자열이 아닌 경우 사용자에게 에러를 전달하는 것이다.
그런데 이 에러 때문에 hello world가 출력되지 않는 상황을 막고 싶다고 가정하자.
이때 process.nextTick()은 현재 pending인 모든 콜백의 처리 이후에
자신의 콜백이 처리되는 것을 보장해준다.
이를 위해 JS call stack을 다 비우고 나서
microtask queue를 통해 process.nextTick()의 콜백이 처리된다.
const EventEmitter = require('node:events');
class MyEmitter extends EventEmitter {
constructor() {
super();
process.nextTick(() => {
this.emit('event');
});
}
}
const myEmitter = new MyEmitter();
myEmitter.on('event', () => {
console.log('an event occurred!');
});또 다른 예시다.
MyEmitter는 생성자에서 emit()을 호출해 이벤트를 일으키고 있다.
그런데 myEmitter.on()을 보면 인스턴스 생성 이후에 이벤트를 설정하고 있다.
그래서 일반적인 상황이라면 이벤트 발생 -> 이벤트 정의라는 어이없는 순서를 가진다.
그렇지만 process.nextTick() 덕분에 .on() 콜백의 처리가 먼저 보장되므로
정상적으로 이벤트가 발생할 수 있게 된다.

(그래서?)
4. 결론
정말 오랜만에 직접 해보지는 않았지만 공부하고 이해한 지식을 공유해봤다.
수많은 async / await를 쓰면서 이 흐름을 완전히 이해하지 못했던 것 같다.
그냥 IDE에서 에러 내니까 추가하거나 빼주는 식이었다.
이벤트 루프도 마찬가지다.
싱글 스레드라 race condition 관리 안해도 되니까 좋겠지~
non-blocking I/O면 좋은 거 아냐?
라고만 생각했다.
마지막으로 (내가 이해한 바로) 요약하면,
이벤트 루프는 커널 작업을 맡겨놓고 다른 작업으로 컨텍스트를 변경해가면서
non-blocking I/O를 구현하고, 커널로부터 poll queue에 콜백을 받아 처리하면서 작업을 이어갈 수 있는 구조를 가진다!
