(planner)
0. 배경
이 글에서도 밝혔듯 올해 목표는 DB 엔진 이해하기다.
(벌써 4번째 밝히는 중!!)
이번에는 내가 특정 도메인을 학습할 때 애용하는 로드맵 웹사이트에서 PostgreSQL 로드맵을 뿌시다가 발견했다.
이번에는 PostgreSQL이 쿼리를 실행하는 과정 중 하나인 query planner/optimizer에 관해 다룬다.
회사에서 처음으로 EXPLAIN 명령어를 다뤄보면서 수없이 사용해왔지만 정작 정확한 원리는 알지 못했다.
나는 항상 어느 줄에서 비용이 급증하는지, 인덱스를 의도대로 탔는지만 확인했었는데,
이번 기회를 통해 EXPLAIN이 말해주는 내용에 대해 더 정확히 알게 되었다.
그러면 이제 PostgreSQL이 쿼리를 실행하기 전까지 어떻게 가공하는지 확인하러 가자!!
1. planner / optimizer
정의
planner와 optimizer는 alias 관계다. postgresql에서 이 둘은 동의어라는 뜻이다.
(따라서, 이하 planner로 지칭한다)
planner는 쿼리 문자열로부터 생성된
query tree를 기반으로
가능한 실행 계획들을 생성하고 비교한 다음 최적의 것을 선정하는 역할을 한다.
이때 여러 실행 계획들을 path라고 칭하고,
최적의 path는 곧 plan tree라는 이진 트리에 저장되어 executor에 전달된다.
2. CBO (cost-based optimization)
정의
위에서 planner는 여러 query plan 중 가장 최적의 것을 선정한다고 했다.
이처럼 쿼리의 비용을 기반으로 쿼리를 최적화하는 것을 CBO(cost-based optimization)라고 한다.
이때 쿼리 비용의 비교는 해당 쿼리를 구성하는 요소들을 파라미터로 하는 함수들과 상수들을 통해 이뤄진다.
(참고로 함수와 상수는 costsize.c 파일에 저장되어 있으며 seq scan에서 다시 다룬다)
vs. RBO (rule-based optimization)
RBO(rule-based optimization)는 말 그대로 미리 작성된 룰을 기반으로 최적화를 진행한다.
그래서 RBO는 해당 테이블 내 데이터 분포 혹은 입력 쿼리의 특성과 같은 동적 특성을 다루지 못한다.
예시를 들어보자.
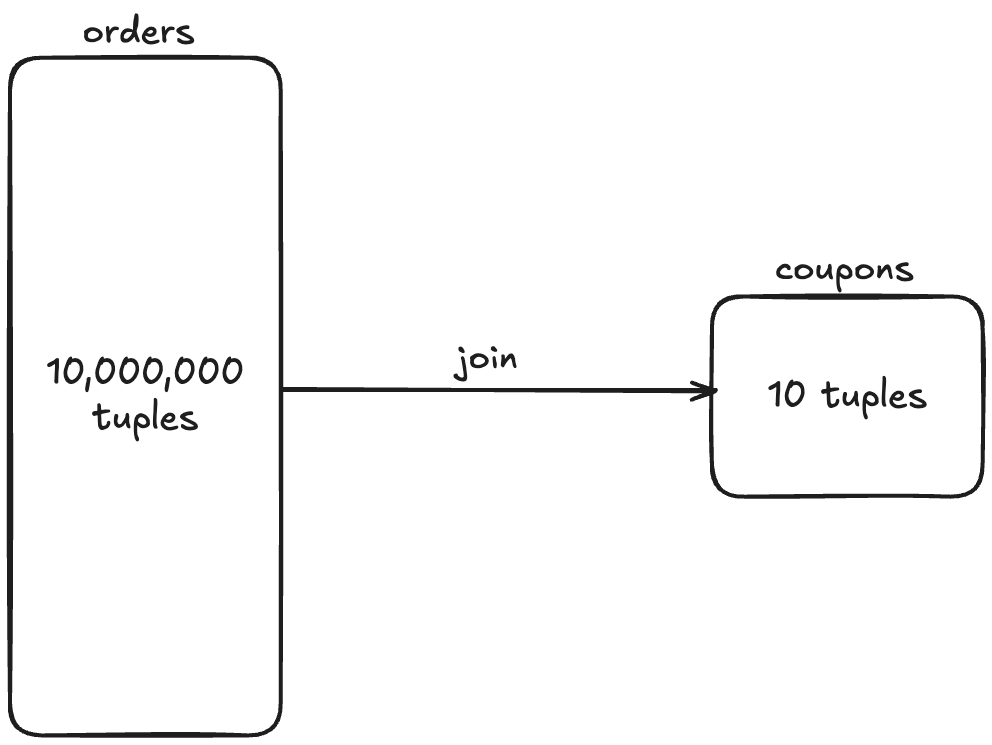
여기 1,000만개 튜플을 가진 orders 테이블과 10개 튜플(레코드)을 가진 coupons 테이블을 조인하고 있다.
그리고 이 조인은 nested loop 방식으로 실행된다고 가정하자.
RBO에선 만약 쿼리에 쓰인 방향대로 조인이 이뤄져야 한다는 규칙이 저장되어 있다면,
1,000만개 튜플 각각에 대해 coupons 테이블을 돌기 때문에 총 1,000만번 루프를 돌아야 한다.
그러나 CBO에서는 이 1,000만번 반복의 비용이 매우 높다는 것을 예측할 수 있기 때문에
조인의 방향을 바꿔 10번만 반복해도 되도록 변경할 수 있다.
3. 실행 계획 (execution plan)
이제 planner의 실행 계획이 어떤 과정을 거쳐 수립되는지 알아보자.
아래 총 세 단계를 거치게 된다.
1) query tree 간소화
어떤 쿼리는 충분히 추론을 통해 간소화할 수 있는 내용을 포함하고 있기도 하다.
예를 들면, WHERE 절에서 NOT(NOT A)를 A로 변경한다든가
A AND (B AND C)를 A AND B AND C로 변경할 수 있다.
2) 최적의 path 결정
쿼리를 실행하는 데는 여러 형태의 path가 존재할 수 있다.
조회 시에는 seq scan, index scan 등 사이에서 access path를 선택해야 하고,
조인 시에는 nested loop join, hash join 등 사이에서 join path를 선택해야 한다.
그리고 그룹화 전략을 결정하는 grouping path도 있다.
해당 쿼리의 로직에 따라 이들 중 일부 path를 조합하여 실행 계획을 결정한다.
(path 내에서의 실행 계획 결정은 하단에서 자세하게 다룬다)
3) path -> 실행 계획 변환
이전 단계에서 정해진 path는 이진 트리 형태의 plan tree에 저장되어 실행 계획으로써 executor에 전달된다.
이때, 트리 내 각 노드는 먼저 실행되어야 하는 것일수록 leaf에 가깝게 위치한다.
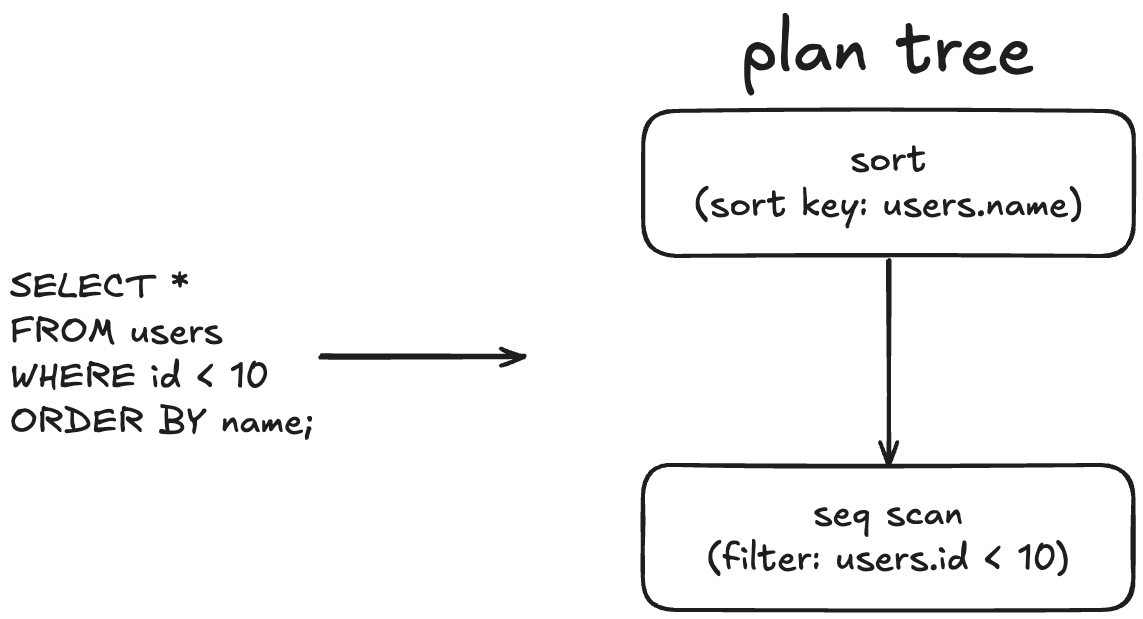
위 예시에서도 마찬가지다.
조건에 맞는 튜플을 모두 찾는 seq scan 이후에 정렬(sort)가 일어난다.

4. path 결정
실행 계획 목차에서 살펴봤던 path 결정에 대한 자세한 내막을 들여다 볼 차례다.
1) access path
seq scan
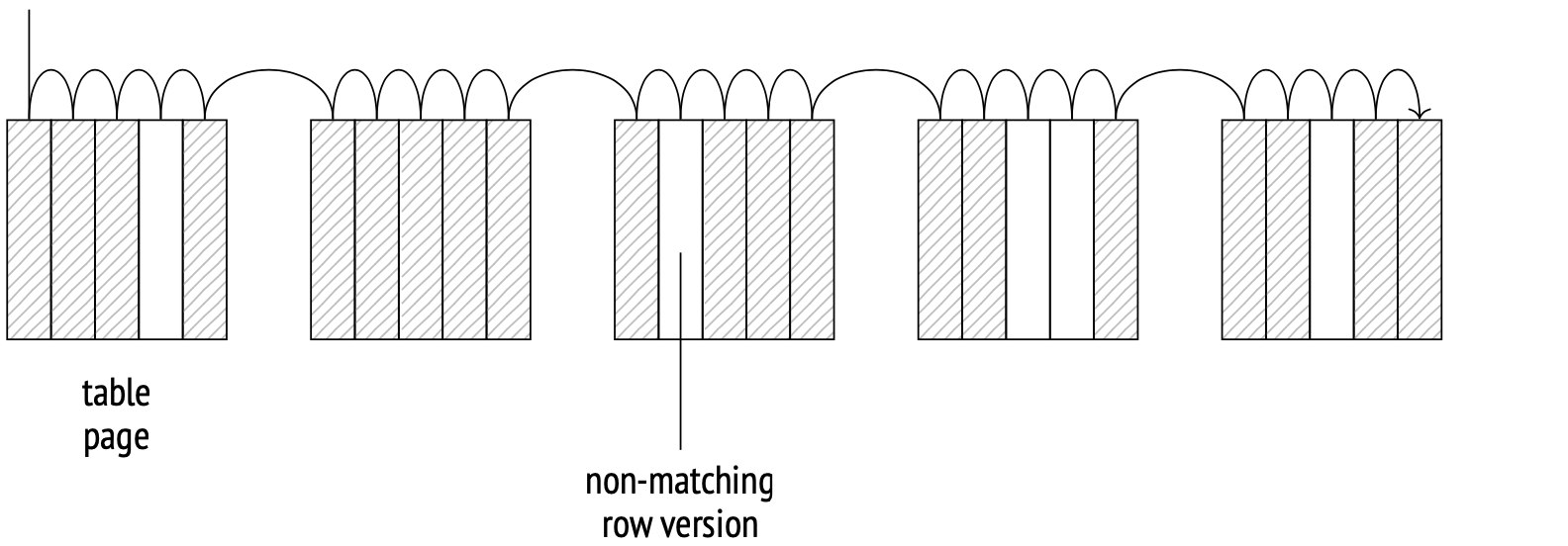
이름과 같이 테이블 전체를 연속적으로 탐색하는 것을 뜻한다. 즉,
O(n)의 복잡도를 가진다.
비용 공식
(rel_tuples * cpu_tuple_cost) + (rel_tuples * cpu_operator_cost) + (relpages * seq_page_cost)
rel_tuples:pg_class시스템 카탈로그에 있는 해당 테이블의 레코드 개수다.- 참고로, 주기적으로 업데이트되는 통계 정보이기 때문에 카운트 쿼리의 값과 일치하지 않을 수 있다.
cpu_tuple_cost: 0.01로,costsize.c파일에 저장된 상수다.- 레코드 1개를 처리하는 데 드는 cpu 비용을 뜻한다.
cpu_operator_cost: 0.0025로,costsize.c파일에 저장된 상수다.- 연산자 1개 실행에 드는 cpu 비용을 뜻한다.
relpages:pg_class시스템 카탈로그에 있는 해당 테이블의 페이지 수다.- 마찬가지로, 정확한 페이지 수와 일치하지 않을 수 있다.
참고: pg_class 🐘
pg_class 시스템 카탈로그의 내용은 자동으로 업데이트되지 않는다.
대신, ANALZYE ${tableName} 혹은 VACUUM 명령어에 의해서만 업데이트된다.
참고: cost 💰
costsize.c의 비용은 각각 1, 0.001과 같은 양의 수로 표현된다.
이때 기준은 seq_page_cost인데, 디스크에서 8KB짜리 페이지 1개를 읽어 오는 비용을 표현한 것이다.
비용 계산 예시
set enable_indexscan = off;
>>> 인덱스 스캔을 하지 못하도록 설정
EXPLAIN
SELECT *
FROM pg_class
WHERE relname = 'pg_class';
>>> 쿼리
QUERY PLAN
-----------------------------------------------------------
Seq Scan on pg_class (cost=0.00..29.19 rows=1 width=265)
Filter: (relname = 'pg_class'::name)테이블 이름이 pg_class인 행을 찾는 간단한 쿼리다.
쿼리 플랜을 보면 29.19의 비용이 출력되었다.
이는 (총 레코드 개수 * 0.01) + (총 레코드 개수 * 0.0025) + (총 페이지 개수 * 1)의 결과다.
(참고로, rel_tuples=742, relpages=20이다)
index scan
B-tree 형태의 자료구조를 통해 데이터의 위치를 저장하고, 해당 데이터의 위치(디스크)로 이동하여 읽는 형태다. B-tree 탐색에는 O(log n)의 복잡도가 할당된다.
(인덱스 스캔에 대한 더 자세한 내용을 알고 싶다면 이 글을 추천한다)
비용 계산 예시
set enable_indexscan = on;
>>> 인덱스 스캔을 허용하도록 설정
EXPLAIN
SELECT *
FROM pg_class
WHERE relname = 'pg_class';
>>> 쿼리
QUERY PLAN
-----------------------------------------------------------
Seq Scan on pg_class (cost=0.28..8.29 rows=1 width=265)
Filter: (relname = 'pg_class'::name)seq scan에서와 동일한 쿼리다.
총 비용은 8.29의 비용이 출력되었다.
결과적으로는 4배 가까이 비용이 축소된 것을 알 수 있다.
index scan 숭배 ✝️ 금지 ☠️
데이터베이스 인덱스 내 각 데이터는 레코드 데이터 전부를 포함하지 않는다.
대신에, 인덱스 컬럼 값 & 해당 레코드를 찾을 수 있는 주소값으로 이뤄져 있다.
itemoffset | htid | convert_from
------------+---------+-----------------------------------
1 | | pg_range
2 | (10,8) | _pg_foreign_data_wrappers
3 | (10,11) | _pg_foreign_servers
4 | (10,5) | _pg_foreign_table_columns
5 | (10,14) | _pg_foreign_tables
6 | (10,17) | _pg_user_mappings
7 | (4,25) | a
8 | (8,19) | administrable_role_authorizations
9 | (8,18) | applicable_roles
10 | (8,21) | attributes위 예시는pg_class_relname_nsp_index 인덱스에 대한 조회 내용이다.
여기서 relname이 _pg_foreign_data_wrappers인 데이터를 조회한다면 위치값인 htid로 (10, 8)을 얻게 된다.
이는 10번째 페이지의 8번째 공간에 해당 레코드가 실제로 위치해 있다는 것을 뜻한다.
그러면 postgresql은 해당 공간으로 디스크 접근을 해야 한다.
그래서 postgresql에서는 costsize.c 파일에 random_page_cost(값은 4) 상수를 따로 정의하여
index scan에 대한 비용을 계산할 때 활용한다.
그런데 위에 등장한 seq_page_cost가 1이기 때문에 이론적으로는 4 미만의 페이지 크기를 가지는 테이블에 대해서는
seq scan이 index scan보다 유리하다.
bitmap heap scan
index scan의 랜덤 접근으로 인한 단점을 극복하기 위해 고안된 스캔 방식이다.
bitmap heap scan은 레코드별로 디스크에 접근을 반복하지 않고, 비트맵 자료구조를 운영하여 디스크 페이지를 한꺼번에 읽어들인다.
예시를 들어보자.
itemoffset | htid | convert_from
------------+---------+-----------------------------------
1 | | pg_range
2 | (10,8) | _pg_foreign_data_wrappers
3 | (10,11) | _pg_foreign_servers
4 | (10,5) | _pg_foreign_table_columns
5 | (10,14) | _pg_foreign_tables
6 | (10,17) | _pg_user_mappings
7 | (4,25) | a
8 | (8,19) | administrable_role_authorizations
9 | (8,18) | applicable_roles
10 | (8,21) | attributes위와 같이 인덱스 전체가 구성되어 있고,
SELECT relname
FROM pg_class;위와 같은 쿼리를 입력했다고 가정하자.
쿼리는 4, 8, 10 총 3개 페이지 안에 모든 데이터를 포함한다.
그러면 bitmap heap scan은 비트맵에 4, 8, 10을 on하고 페이지를 통째로 조회한다.
따라서 index scan에서 9번의 조회가 필요했던 작업이 bitmap heap scan에서는 1번에 이뤄질 수 있다.
그래서 bitmap index scan은 createdAt, auto_increment id의 between 연산과 같이
순차적으로 저장된 다수 데이터에 대한 조회에 유리하다.
2) join methods
nested loop join
driving table->driven table방향으로 각 driving table의 레코드마다 일치하는 driven table의 레코드를 매칭하여 조인하는 방식이다.
hash join
build table(작은 테이블)에 대한 해시 테이블을 생성하고,probe table(큰 테이블)을 순회하면서 해시 테이블과 매칭하여 조인하는 방식이다.
merge join
merge join은 조인 키를 기반으로 두 테이블을 정렬하고 포인터를 통해 매칭하여 조인하는 방식이다.
3) pg_statistic
pg_statistic은 테이블에 대한 통계 정보를 담고 있으며,
이 통계 정보를 기반으로 path를 결정한다.
예를 들어, 전체 레코드가 WHERE 조건에 얼마나 부합하는지를 다루는 selectivity를 가지고
selectivity가 높은 경우 seq scan을, 낮은 경우 index scan을 결정하기도 한다.
pg_statistic은 autovacuum이 설정되어 있는 경우 자동으로 업데이트 된다.
혹은 ANALYZE 명령어를 통해 업데이트 할 수 있다.

5. 결론
이번 시간을 통해 postgresql이 어떻게 쿼리를 실행할지 결정하는지 알 수 있게 되었다.
간단하게 요약하자면,
postgresql은 비용 기반으로 쿼리 실행 방법을 결정한다.
이 비용은 페이지 수, 레코드 수 등의 파라미터를 가지고 각 실행 방법에 대한 함수를 연산하여 산정된다.
