
(스냅샷이 무려 3개!)
0. 배경
올해 목표 중 하나가 DB 엔진 1개 완전히 이해하기였다.
그래서 내 눈에 들어온 게 현재 회사에서 사용하고 있는 PostgreSQL이다.
커피챗에서 들은 방식대로 PostgreSQL의 주축을 이루는 개념을 1개씩 톺아볼 예정이다.
오늘은 그중 MVCC에 관해 다룬다.

1. transaction
정의
트랜잭션은 데이터베이스와 상호작용하는 논리적 단위를 뜻한다.
예를 들어 SELECT * FROM users;와 같은 것들을 포함한다.
그런데 중요한 것은, 예시와 같이 쿼리 1개 단위로만 트랜잭션이 구성되지 않는다.
트랜잭션은 2개 이상의 쿼리를 포함할 수 있다는 것을 명심하자.
(이따가 이 개념을 써먹어야 한다)
목적
트랜잭션은 데이터베이스의 integrity를 보장할 수 있어야 한다.
예를 들어볼까?
판매자와 구매자가 강남역에서 만나 당근하는 모습이다.
무슨 물건인지는 모르겠으나 값을 치르기 위해 500$를 토스로 보내야 한다.
즉, 구매자의 잔고가 500 달러가 줄어듦과 동시에 판매자의 잔고는 500 달러 늘어야 한다.
그리고 이 과정은 정확하게 지켜져야 한다.
구매자는 500 달러를 보냈지만, 판매자 잔고가 늘어나지 않는다면
거래가 제대로 이뤄지지 않고 대신 싸움이 벌어질지도 모른다.
ACID
데이터베이스의 트랜잭션이 안정적으로 실행될 수 있도록 하는 4가지 원칙을 뜻한다.
하단에 4가지 원칙을 하나씩 간단하게 다루겠다.
-
atomicity (원자성)
트랜잭션이 완전히 성공하거나, 아예 실패해야 한다는 것을 뜻한다.
위 예시에서처럼 구매자의 잔고가 줄어들기만 하고 트랜잭션이 끝나면 토스 서버 개발자가 많이 바빠질 것이다... -
consistency (일관성)
데이터의 일관성을 뜻한다.
방금 본 잔고가 500 달러였는데 지금은 아무 이유없이 350 달러라면 일관성이 부족한 상태라고 할 수 있겠다. -
isolation (격리성)
여러 트랜잭션이 동시에 실행되더라도, 트랜잭션 간의 독립성이 보장되어야 한다.
격리성은yes/no가 아닌 상대적인 개념으로, 3번 항목인transaction isolation에서 다루도록 하겠다. -
durability (지속성)
데이터는 시간이 지나도 영원히 데이터베이스 파일 시스템에 저장되어 있어야 한다.
메이플스토리 만렙 찍어놓고 자고 일어나니 계삭되어 있다면 지속성이 부족한 시스템이라고 할 수 있겠다.
2. MVCC
정의
MVCC는 Multi-Version Concurrency Control의 준말이다.
즉, 여러 버전이 동시에 존재할 때 이를 적절히 제어할 수 있는 기술을 뜻한다.
어떻게?
각 SQL문은 독립적으로 데이터에 대한 스냅샷(DB 버전)을 가진다.
참고로 DB 버전은 타임스탬프 혹은 트랜잭션 ID를 기준으로 생성된다.
해당 트랜잭션을 수행하는 과정에서 다른 동시 트랜잭션이 데이터를 수정하더라도 스냅샷은 변하지 않는다.
따라서 각 트랜잭션은 일관성 있는 데이터를 보게 되고, 이러한 것을 transaction isolation이라고 한다.
뭐가 다른데?
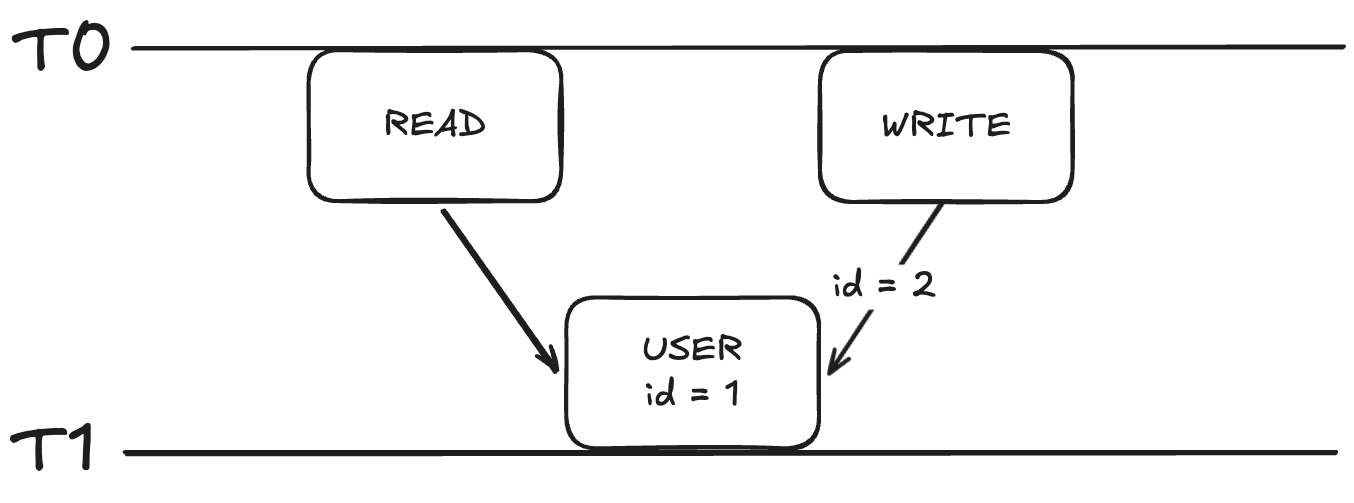
우선 이 그림을 보자.
T0라는 시점에 읽기와 쓰기 작업이 동시에 일어나고 있다.
쓰기 작업은 id를 2로 변경하려고 하는데,
이때문에 읽기 작업은 id를 1로 읽을 수도, 2로 읽을 수도 있다.
이러한 슈뢰딩거의 고양이 같은 상황을 방지하고자 쓰기 작업이 lock을 획득하고 읽기 작업은 이를 기다린다.
그리고 이를 read-write lock이라고 한다.
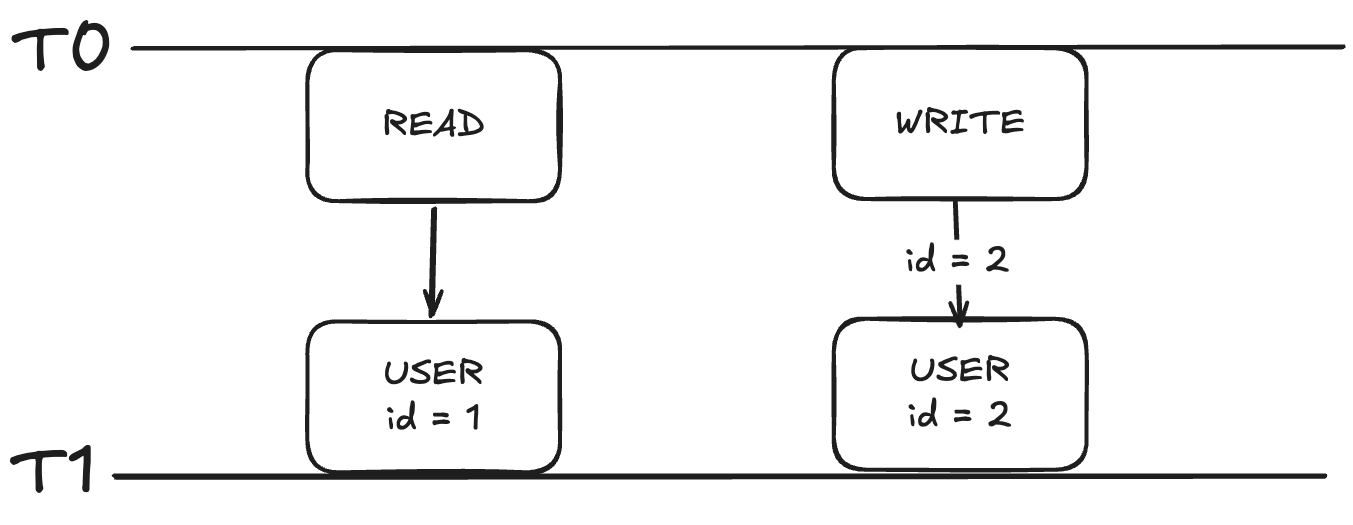
이젠 그림이 달라졌다.
읽기 작업은 그 나름의 스냅샷을 갖게 되었다.
따라서, 동시에 발생한 쓰기 작업의 결과와 T0 시점의 스냅샷을 가지고
독립적으로 읽기 작업을 진행할 수 있게 되었다.
그래서 이와 같이 read-write lock에 대한 필요치 않은 것이 MVCC의 장점이다.
3. transaction isolation 4단계
갑자기?
위의 ACID 원칙 중 isolation에서 트랜잭션 간 격리성이 보장되어야 한다고 밝힌 바 있다.
그리고 격리성은 이분법적이지 않고 상대적으로 나뉜다고도 했다.
그래서 이를 4 levels of transaction isolation이라고 4단계로 나누는데,
SQL 표준을 먼저 보고 PostgreSQL에서 어떻게 구현했는지 톺아보자.
SQL 표준
1) read uncommitted
이 단계에서는, 읽기 트랜잭션 x가 아직 커밋되지 않은 트랜잭션 y의 변경사항을 읽을 수 있다.
다시 한번, 예를 들어보자.
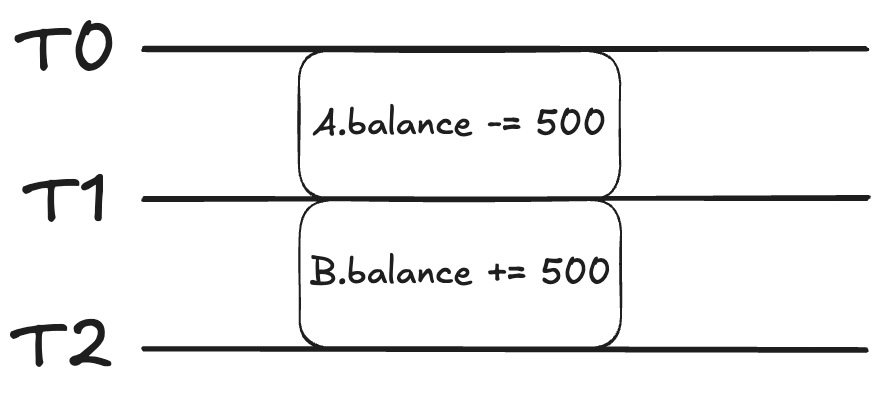
T0에서 시작되는 트랜잭션 y는 A가 B에 송금을 한다.
즉, A의 잔고가 500 줄어들고 그 뒤에 B의 잔고는 그만큼 늘어난다.
그런데 A의 잔고를 읽는 트랜잭션 x가 T1에서 시작했다고 가정하자.
그렇다면 A의 값은 얼마로 보일까?
답은 -500 된 채 보일 것이다.
아직 y가 커밋되지 않았다고 하더라도 x는 y의 변경사항을 읽을 수 있다.
여기까지는 그렇게 이상하게 보이지 않을 것이다.
이 시점에 차감되어 있는 것이니 그렇게 보이는 게 정상일 수도 있지 않겠는가?
그러나 트랜잭션 y가 롤백한다면?
예를 들어, 은행 점검 시간 같은 게 걸려서 송금에 실패한다면?
차감된 금액으로 보임과 동시에 송금에는 실패했다고 뜬다면
A는 멘붕에 빠질지도 모른다...
이렇듯 롤백으로 인해 데이터 정합성에 문제가 생기는 상황을
dirty read라고 하고, read uncommitted 단계가 가지고 있는 문제점이다.
2) read committed
이 단계에서는, 전보다 딱 한 단계 나아가서
임의의 트랜잭션 x는 커밋된 트랜잭션 y의 변경사항만 조회할 수 있다.
다시 여기로 돌아와서, 이번엔 읽기 트랜잭션 x와 z가 각각 T0과 T1에 시작했다고 가정하자.
T0와 T1에선 트랜잭션 y가 커밋되기 이전이기 때문에 x와 z는 모두 차감 이전의 스냅샷을 가진다.
즉, T2 이전의 읽기 트랜잭션은A.balance에 대해 모두 동일한 값을 가진다.
그런데?!
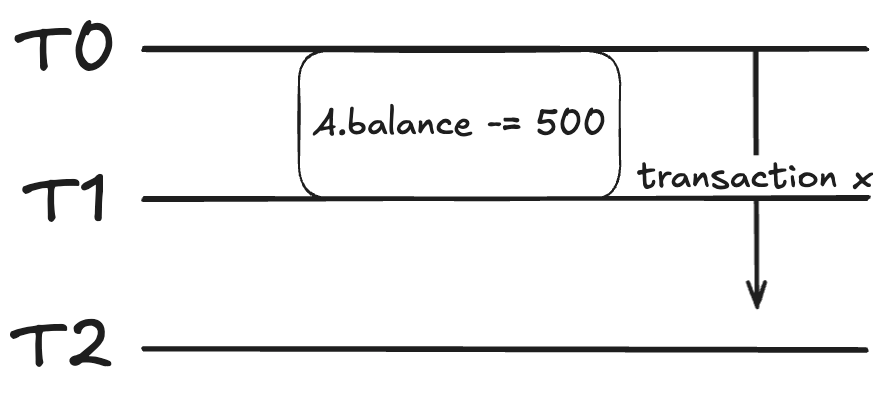
트랜잭션 x는 T0에서 1번, T1에서 1번 A.balance에 대한 읽기 작업을 진행한다.
그리고 A.balance를 차감하는 트랜잭션 y는 T1에서 커밋된다.
그러면 동일한 트랜잭션 x 내에서 발생하는 2개의 연속된 읽기 작업은
각각 차감 전과 차감 후의 서로 다른 값을 읽게 된다.
그래서 내 잔고가 1000 달러인지,
500 달러인지 알 수 없는 상황이 된다...

이처럼 하나의 트랜잭션 안에서 연속된 읽기 작업을 하는 와중에
다른 트랜잭션이 수정 작업을 커밋하면서 값이 달라져버리는 상황을
non-repeatable read라고 한다.
3) repeatable read
이 단계에서도, 전보다 한 단계 나아가서
임의의 트랜잭션 x 안의 연속된 읽기 작업은 모두 동일한 값을 읽도록 보장한다.
쉽게 말해 트랜잭션 x가 T0와 T1에서 각각 읽기 작업을 수행하더라도,
두 읽기 작업은 모두 차감 이전의 값을 조회하게 된다.

나: 아직...
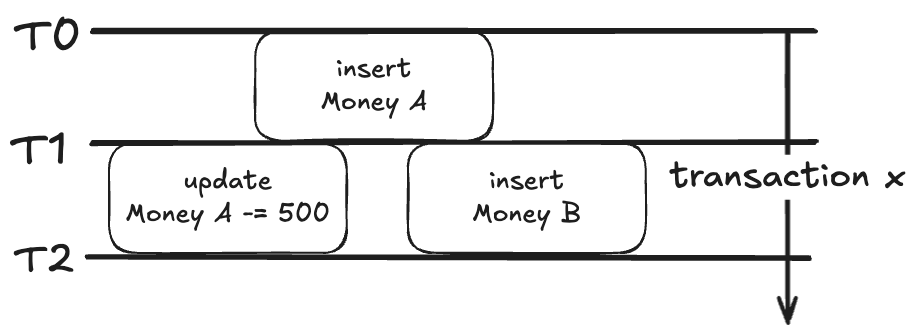
이번에도 예외 상황이 발생한다...
이번에는 내 계좌에 T0와 T1에서 각각 1번씩 입금하는 트랜잭션을 가정하자.
추가로, T1에서 거래 A의 금액을 500 줄인다.
그리고 트랜잭션 x는 T1과 T2에서 각각 내 거래 내역을 조회한다.
T1에서 시작한 트랜잭션 내의 조회 결과는 당연하게도 A가 될 것이다.
그러면 T2에서는?
일단 A에 대한 것은 동일 레코드에 대한 수정 트랜잭션이기 때문에 반영되지 않을 것이다.
그러나 B는 새로운 레코드가 추가된 것이기 때문에 WHERE user = 나라는 조건에 걸려 조회된다.
이처럼 동일 트랜잭션 내에서 연속적인 읽기 작업이 발생할 때,
그 사이에 레코드가 추가 및 삭제된 내용이 조건문에 걸려 조회 결과가 달라지는 것을
phantom read라고 한다.
4) serializable
serializable 단계는 동시에 발생한 트랜잭션들 내의 모든 연산들이 마치 열을 이뤄
하나씩 순서대로 처리되는 것을 보장한다.
🤔
이 말을 들었을 땐 이런 생각이 떠올랐다.
그러면 애초에 concurrent라는 말이 왜 있는 거지?
모든 트랜잭션을 순서대로 하나씩 나열해서 처리하면 되는 거 아닌가?
그렇게 하는 게 사실 맞았다!
다만, lock을 통해 순서대로 실행할 수 있게 된다.
read-write lock을 통해
{A 조회 -> A 조회},{A 수정}트랜잭션이 동시에 발생하면,
{A 수정}이 lock을 획득한 후 나머지 하나가 커밋할 때까지 기다려야 한다.

그렇지만 이 방법만 있는 건 아니다.
위 방식은 pessimistic lock, 즉 비관적인 방식이고,

optimistic lock, 긍정적인 방식도 있다.
PostgreSQL에서도 이 optimistic 방식을 활용하는데,
이 방식은 명시적인 lock을 사용하지 않는다.
다만, 연속 조회 트랜잭션과 수정 트랜잭션이 동시에 발생하면
하나만 받아들이고 연속 조회 트랜잭션을 롤백시킨다.
postgresql 버전
이제부터는 이 4단계의 transaction isolation을 postgresq에서 어떻게 구현했는지 톺아본다.
다만, 여기서부턴 필자도 완벽하게 이해하진 못했으며 글도 길기 때문에 재미없을 예정이다.
따라서 본인이 효율충이거나 도파민 중독자라면 이쯤에서 끊고 나갈 것을 강력하게 추천한다.
1) read committed
엥?! 첫 단계는 read uncommitted가 아니었던가?!
사실 postgresql에서는 read uncommitted 단계를 지원하지 않는다.
MVCC에서 언급했듯 postgresql에서는 스냅샷을 사용한다.
트랜잭션 시작 전에 스냅샷을 떠서 이용하기 때문에
- 커밋되지 않은 트랜잭션
- 쿼리 실행 중에 커밋된 동시적인 트랜잭션
전부 쿼리 실행에 영향을 주지 않는다.
그러나!!
트랜잭션 내에서 실행하는 쿼리마다 스냅샷을 초기화한다.
따라서, 다른 트랜잭션에서의 수정이 그 이후의 쿼리에 대한 스냅샷에 반영된다.
그래서 트랜잭션이 {A 조회 -> A 수정 -> A 조회}로 구성되어 있다면
두번의 조회 결과가 서로 다를 것이다.
위험성
이 단계에서 특히 수정 트랜잭션이 예상치 못한 결과를 가질 수 있다.
적당한 예를 들어보자.
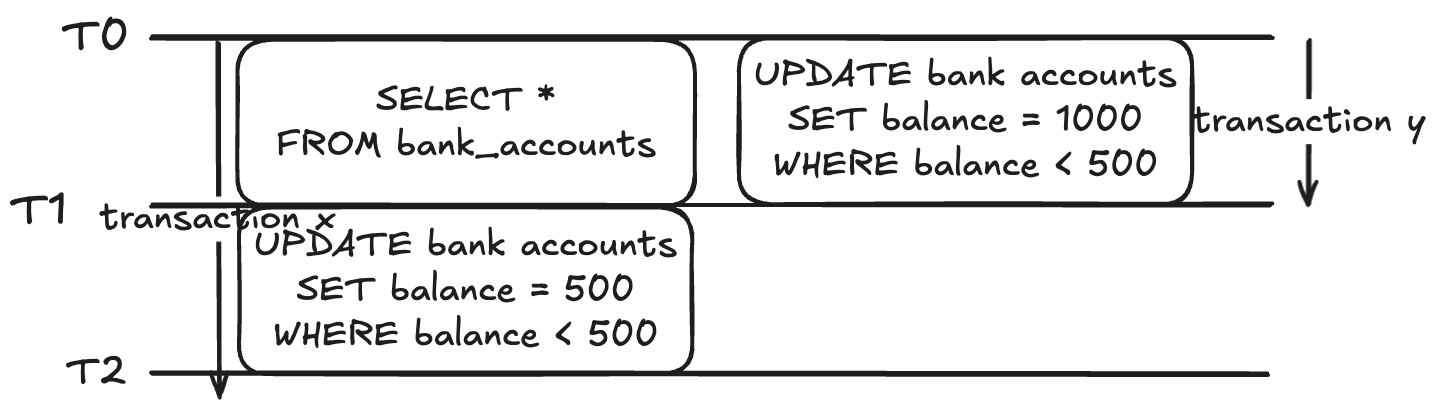
모든 계좌를 조회하고 500 미만의 잔고 값을 가진 계좌들의 잔고를 500으로 설정하는 트랜잭션 x와
500 미만의 잔고 값을 가진 계좌들의 잔고를 1000으로 설정하는 트랜잭션 y가 있다.
트랜잭션 y는 T0에서 시작하여 T1에서 커밋한다.
즉, T1 시점에는 변경된 데이터를 확인할 수 있다.
그리고 이 단계에서는 수정 쿼리의 WHERE 문이 스냅샷과 관계없이 데이터를 조회하기 때문에
결국 트랜잭션 y가 커밋한 결과를 가지고 수정 쿼리를 진행하게 된다.
따라서 예상하지 못한 수정 연산이 발생할 수 있다.
(참고로, 이 예시에서는 트랜잭션 x는 아무것도 수정하지 못하게 된다)
2) repeatable read
repeatable read 단계에서는 트랜잭션 단위로 스냅샷을 초기화한다.
따라서, 커밋되지 않은 트랜잭션 혹은 트랜잭션 실행 중 커밋된 다른 트랜잭션은 스냅샷에 반영되지 않는다.
따라서, 트랜잭션 시작 이후에 레코드가 추가되거나 삭제되는 것도 반영되지 않기 때문에
SQL standard에서와 달리 이 단계에서 phantom read가 허용되지 않는다.
그러나!!
여전히 동일 트랜잭션 내에서의 수정은 스냅샷에 반영된다.
동시성 관리
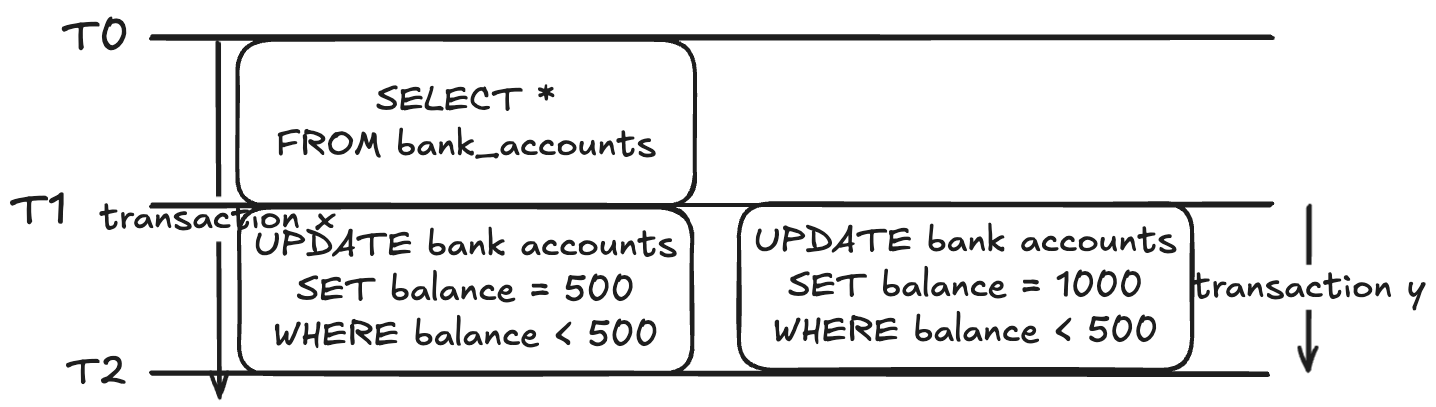
다시 비슷한 예시로 돌아와서,
그림과 같이 수정이 동시에 발생했다고 가정하자.
트랜잭션 y와 x는 수정에 있어 동일한 조건을 가지기 때문에
두 트랜잭션의 타겟 데이터가 동일할 것이다.
이와 같은 경우 repeatable read 단계에서는 조금이라도 먼저 시작한 트랜잭션을
나중의 트랜잭션이 마칠 때까지 기다려준다.
트랜잭션 y가 먼저 시작되었다고 가정하면, 트랜잭션 x는 y가 롤백되거나 커밋할 때까지 기다린다.
그리고 y가 롤백한 경우엔 x는 자연스럽게 수정을 진행할 수 있게 되지만,
y가 커밋한 경우엔 x는 수정 없이 아래와 같은 에러 메시지와 함께 롤백하게 된다.
ERROR: could not serialize access due to concurrent update이는, 이미 트랜잭션이 시작된 시점에서 다른 트랜잭션이 바꿔둔 데이터에
락을 걸거나 수정을 가할 수 없기 때문이다.
따라서, 롤백된 트랜잭션 x는 재시도 해야 한다.
재시도했을 때에는 T2를 기준으로 스냅샷을 뜨기 때문에 문제없이 진행할 수 있게 된다.
3) serializable
serializable 단계에서는 모든 트랜잭션을 마치 순차적으로 진행된 것처럼 시뮬레이션으로 돌려본다.
이 단계는 repeatable read 단계에서와 동일하게 같은 데이터를 동시에 수정할 경우,
즉 동시성 충돌이 발생한 경우 롤백하는 매커니즘을 가진다.
repeatable read와 유일하게 다른 점은,
serializable에서는 동시적인 트랜잭션들을 가능한 모든 순서로 돌려보고
서로 일관적이지 않을 경우 serialization failure을 일으키도록 모니터링한다는 점이다.
serialization failure
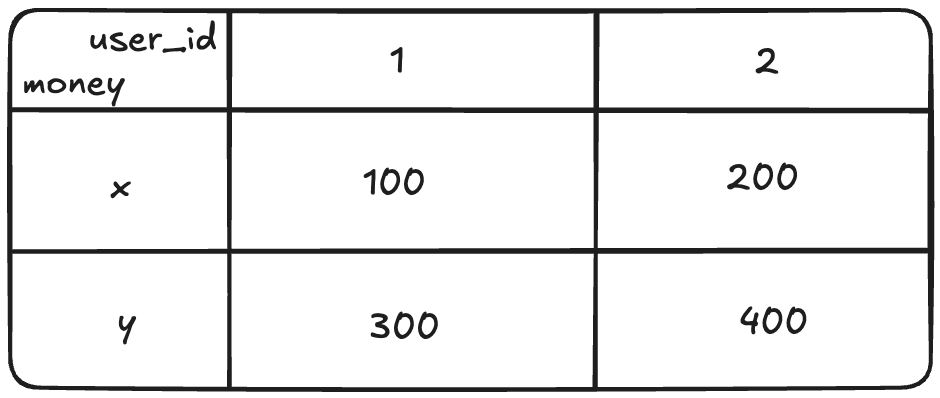
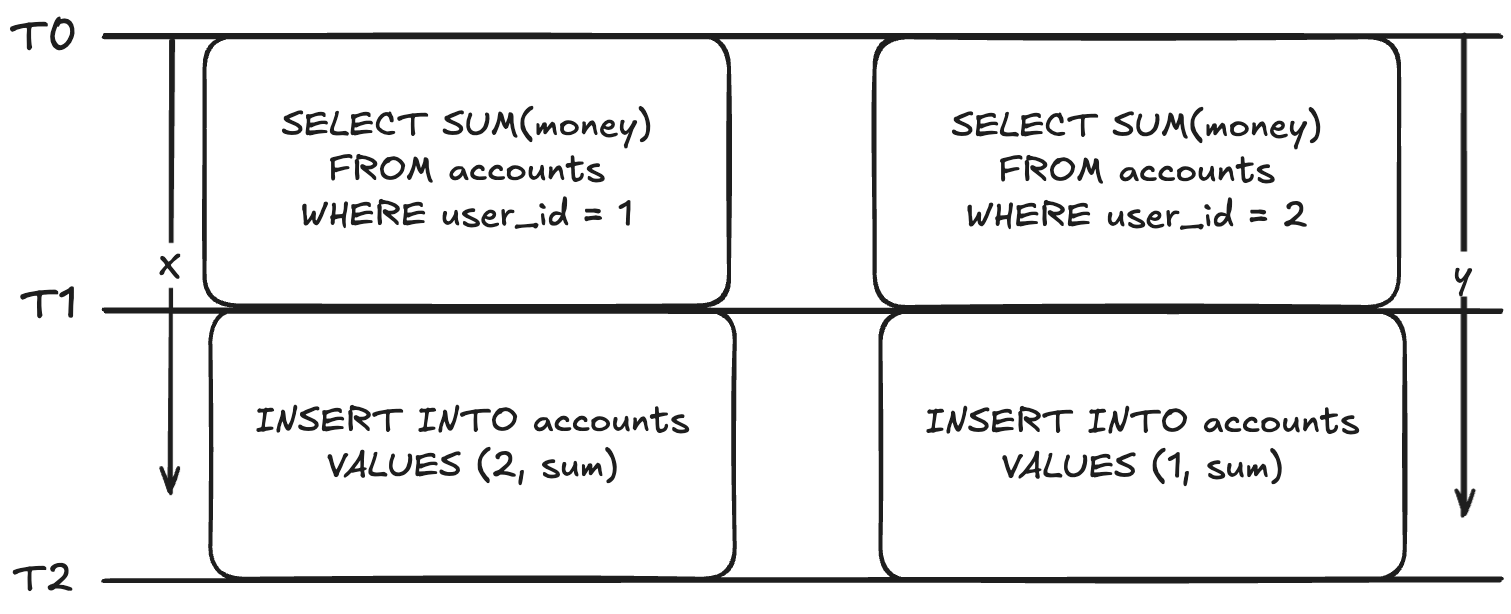
위와 같은 상황을 가정해보자.
트랜잭션 x는 user_id가 1인 모든 돈을 합쳐 user_id가 2인 돈 레코드를 생성한다.
트랜잭션 y는 user_id가 2인 모든 돈을 합쳐 user_id가 1인 돈 레코드를 생성한다.
이러한 상황에서 x->y 순으로 실행한 경우 생성된 레코드는 {400, 1000}이 되지만,
y->x 순으로 실행한 경우엔 {600, 1000}으로 달라진다.
따라서 이처럼 동시적인 트랜잭션 간의 실행 순서에 따라 결과가 달라질 경우
serializable 단계에서는 하나를 받아들이고 나머지를 롤백시킨다.
predicate locking
prediacate locking은 lock을 통해서 읽기 작업과 쓰기 작업이 동시에 발생했을 때,
만약 실제로 일어난 순서의 반대였을 경우 결과가 달라질지 확인하기 위해 사용한다.
그래서 predicate lock은 실제로 레코드나 테이블에 대한 접근을 막는 용도가 아니고,
동시에 발생한 트랜잭션들끼리의 순서와 결과가 독립적인지 아닌지 확인하기 위함이다.
주의점
위에서 언급했듯 serializable 단계에선 serialization failure에 따른 트랜잭션 롤백이 수반되기 때문에
반드시 롤백된 트랜잭션을 재시도하도록 하는 매커니즘을 두어야 한다.
(참고로 40001 SQLSTATE 에러가 발생한다)
그리고 직렬화 시뮬레이션을 위한 모니터링에 따른 비용이 발생한다는 점을 감안하자.
그러나 그만큼 데이터나 테이블에 명시적인 lock이 걸리지 않는다는 점도 고려하자.

(그래서?)
4. 결론
PostgreSQL 내 중요한 개념 중 하나인 MVCC에 대해 알아보았다.
명시적으로 lock을 걸지 않고도 동시성을 제어한다는 부분이 색달랐달까.
그리고 SQL 표준에서와 PostgreSQL 구현에서의 transaction isolation
단계별 디테일이 묘하게 달라서 함께 비교하고 외워가는 맛이 있었다.
참고로 postgresql에 대한 부분은 여기서 참고했는데,
양이 정말로 방대하고 예외적인 상황이 정말 많다...
문단 하나하나 정확하게 곱씹고 넘어가는 것을 추천한다.
혹은 내가 쓴 글만 읽고 넘어가더라도 얼추 면접에서 PostgreSQL 좀 안다는 인상은 줄 수 있지 않을까.
아무튼, 여기까지 읽은 당신! 수고 많았다.
