selector로 바로 뽑아 올 수도 있지만 find_all을 이용하여 규칙성을 찾아서 접근하는 방법도 있다.
import urllib.request as req
from bs4 import BeautifulSoup
url = "https://www.naver.com/"
# html = req.urlopen(url) #페이지 저장 객체
html = req.urlopen(url).read().decode("utf-8") #페이지 문자열
bs = BeautifulSoup(html, 'html.parser')
# 범위를 줄여가면서 찾는 방법
# div 태그이면서 클래스 속성이 ~ 인 것을 찾아라
# find(태그, {속성명:값})
div = bs.find("div", {"class":"service_area"})
a = div.find("a")
print(a.text)
import urllib.request as req
from bs4 import BeautifulSoup
url = "https://www.naver.com/"
# html = req.urlopen(url) # 페이지 저장 객체
html = req.urlopen(url).read().decode("utf-8") # 페이지 문자열
bs = BeautifulSoup(html, 'html.parser')
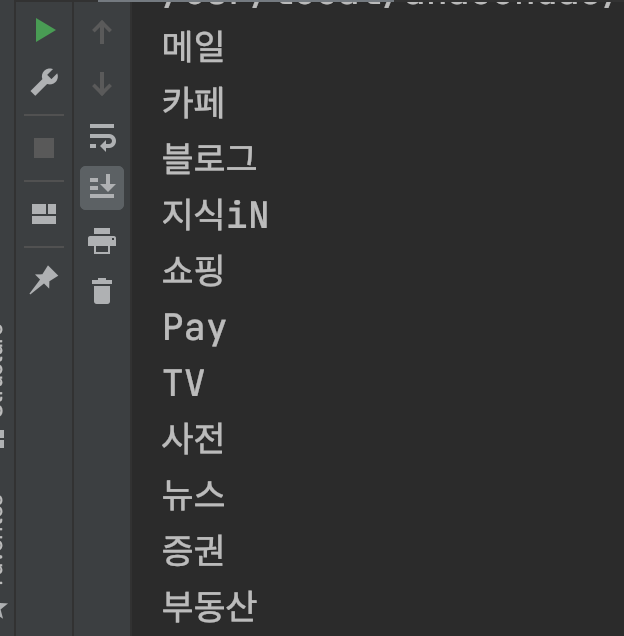
div0 = bs.find("div", {"class":"group_nav"})
lis = div0.find_all("li", {"class":"nav_item"})
for li in lis:
a = li.find("a")
print(a.text)
div0 = bs.find("div", {"class":"group_nav"})
lis = div0.find_all("li", {"class":"nav_item"})
for li in lis:
a = li.find("a")
print(a.text, end=",")
네이버 브라우저를 통해 접근하는 것처럼
import requests
from bs4 import BeautifulSoup
url = "https://news.naver.com/"
# 스크레이핑 App이 아닌 브라우저로 접근하는 것처럼 해주는 헤더설정
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36" }
html = requests.get(url, headers=headers).text
bs = BeautifulSoup(html, 'html.parser')
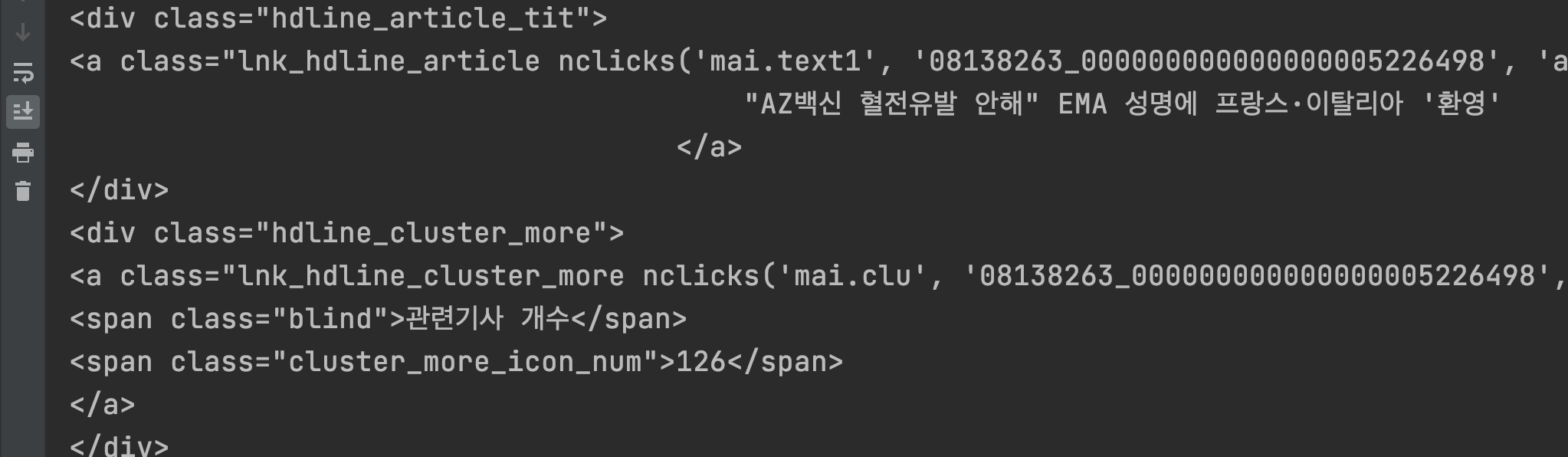
headline = bs.find("ul", {"class":"hdline_article_list"})
print(headline)
import requests
from bs4 import BeautifulSoup
url = "https://news.naver.com/"
# 스크레이핑 App이 아닌 브라우저로 접근하는 것처럼 해주는 헤더설정
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36" }
html = requests.get(url, headers=headers).text
bs = BeautifulSoup(html, 'html.parser')
headline = bs.find("ul", {"class":"hdline_article_list"})
a_news = headline.find_all("a", {"class":"lnk_hdline_article"})
for a in a_news:
print(a.text.strip())
etc_uls = bs.find_all("ul", {"class":"mlist2 no_bg"})
for ul in etc_uls:
news = ul.find_all("strong")
for n in news:
print("news: ", n.text)

