로그를 찾을 때 정규 표현식이 아주 많이 쓰인다.
# 정규표현식이 왜 필요한지
data = """
park 800905-1049118
kim 700905-1059119
"""
result = []
for line in data.split("\n"):
word_result = []
for word in line.split(" "):
if len(word) == 14 and word[:6].isdigit() and word[7:].isdigit():
word = word[:6] + "-" + "*******"
word_result.append(word)
result.append(" ".join(word_result))
print("\n".join(result))

data = """
park 800905-1049118
kim 700905-1059119
"""
import re
pat = re.compile("(\d{6})[-]\d{7}")
print(pat.sub("\g<1>-*******", data)) # group 1
같은 결과 출력
import re
p = re.compile("[abc]") # a, b, c중에 1글자가 일치하면 찾았다
m = p.search("a")
print(m)
m = p.search("before")
print(m)
m = p.search("dude")
print(m)
m = p.search("ebc")
print(m)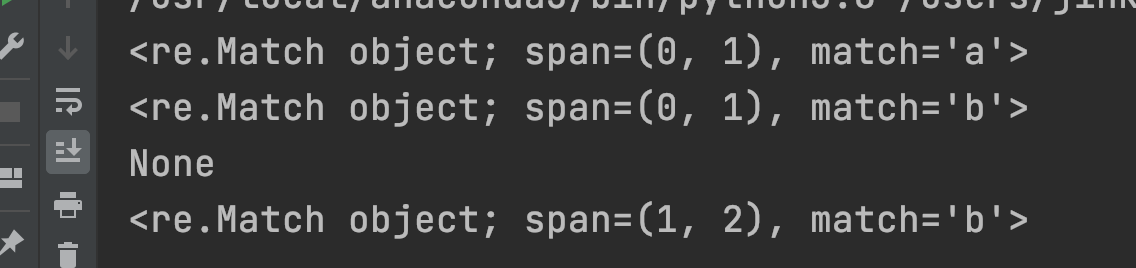
import re
p = re.compile("[a-zA-Z]") # 알파벳 모두 해당하면 찾아라
m = p.search("123abc")
print(m)
p = re.compile("[0-9]") # 숫자 1글자를 찾아라
m = p.search("abc123")
print(m)
p = re.compile("[^0-9]") # 숫자가 아닌 문자를 찾아라
m = p.search("abc123")
print(m)
# import re
# p = re.compile("\d") #[0-9]와 같다
# m = p.search("abc123")
# print(m)
# p = re.compile("\D") #[^0-9]와 같다
# m = p.search("abc123")
# print(m)
# p = re.compile("\s") # whitespace(공백문자), [ \t\n\r\f\v]
# m = p.search("abc 123")
# print(m)
# p = re.compile("\S") # [^ \t\n\r\f\v]
# m = p.search("abc 123")
# print(m)
# p = re.compile("\w") # word (문자+숫자), [a-zA-Z0-9_]
# m = p.search(" abc 123")
# print(m)
# p = re.compile("\W") # [^a-zA-Z0-9_]
# m = p.search("abc!? 123")
# print(m)
# import re
# p = re.compile("a.b") # a+모든문자+b
# m = p.search("123a9b")
# print(m)
# m = p.search("aab")
# print(m)
# m = p.search("a0b")
# print(m)
# m = p.search("abc")
# print(m)
import re
p = re.compile("a[.]b") # a.b을 찾아라
m = p.search("a0b")
print(m)
m = p.search("a.b")
print(m)
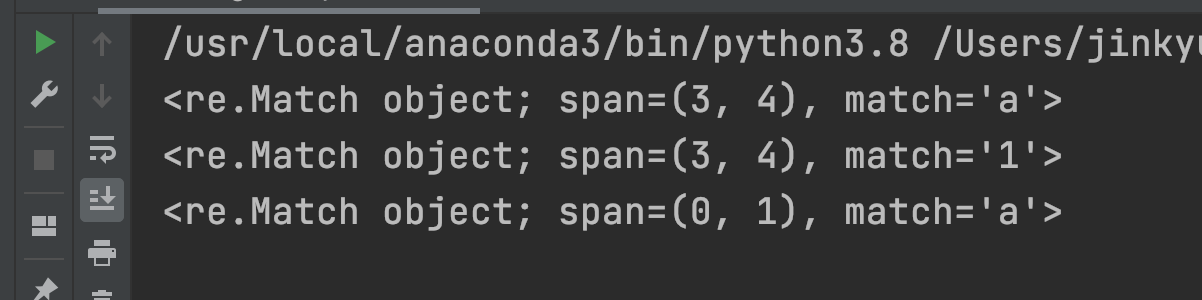
import re
p = re.compile("ca*t") # c와 t사이에 a가 0 ~ 무한대 반복
m = p.search("ct")
print(m)
m = p.search("cat")
print(m)
m = p.search("caaat")
print(m)

import re
p = re.compile("ca+t") # c와 t사이에 a가 1 ~ 무한대 반복
m = p.search("ct")
print(m)
m = p.search("cat")
print(m)
m = p.search("caaat")
print(m)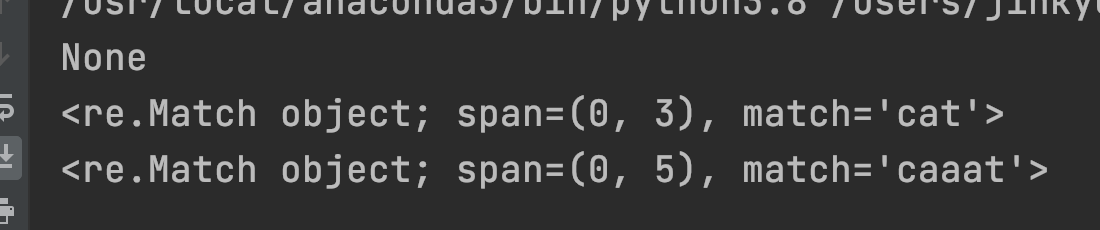
import re
p = re.compile("ca{2}t") # a가 2번 반복
m = p.search("cat")
print(m)
m = p.search("caat")
print(m)
m = p.search("caaaat")
print(m)
import re
p = re.compile("\d{6}[-]\d{7}")
m = p.search("홍길동, 임꺽정, park901010-1089076장길산, 일지매")
print(m)
p = re.compile("[0-9]{6}[-][0-9]{7}")
m = p.search("홍길동, 임꺽정, park901010-1089076장길산, 일지매")
print(m)

import re
p = re.compile("ca{2,5}t") # c와 t사이에 a가 2~5회 반복
m = p.search("cat")
print(m)
m = p.search("caat")
print(m)
m = p.search("caaaaat")
print(m)
m = p.search("caaaaaaaaat")
print(m)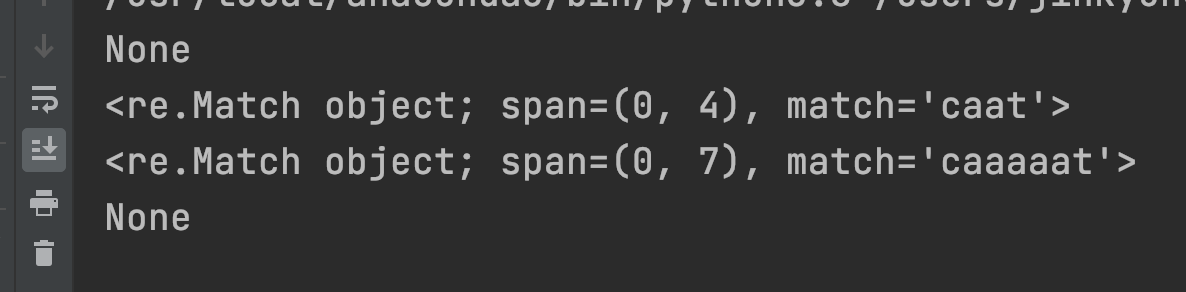
data = """ # 처음에 사실은 개행문자가 들어가있음 (그래서 none 출력)
ab abc ac ad aaa
abbbbbc
bbbaaaccc
abbbbbbbbbb
"""
data1 = "ab abc ac ad aaa"
import re # 정규표현식 모듈 메모리에 로딩
p = re.compile("ab*") # 표현식을 사용할 수 있게 객체 생성
m = p.match(data) # 처음부터 일치하는 여부
print(m)
m = p.match(data1) # 처음부터 일치하는 여부
print(m)
m = p.search(data) # 어디서든 일치하는 여부
print(m)
m = p.search(data1) # 어디서든 일치하는 여부
print(m)
m = p.findall(data) # 일치하는 모든 문자열을 리스트로 반환
print(m)
for d in m:
print(d)
m = p.finditer(data) # 일치하는 모든 문자열을 반복객체로 반환(위치까지)
for d in m:
print(d)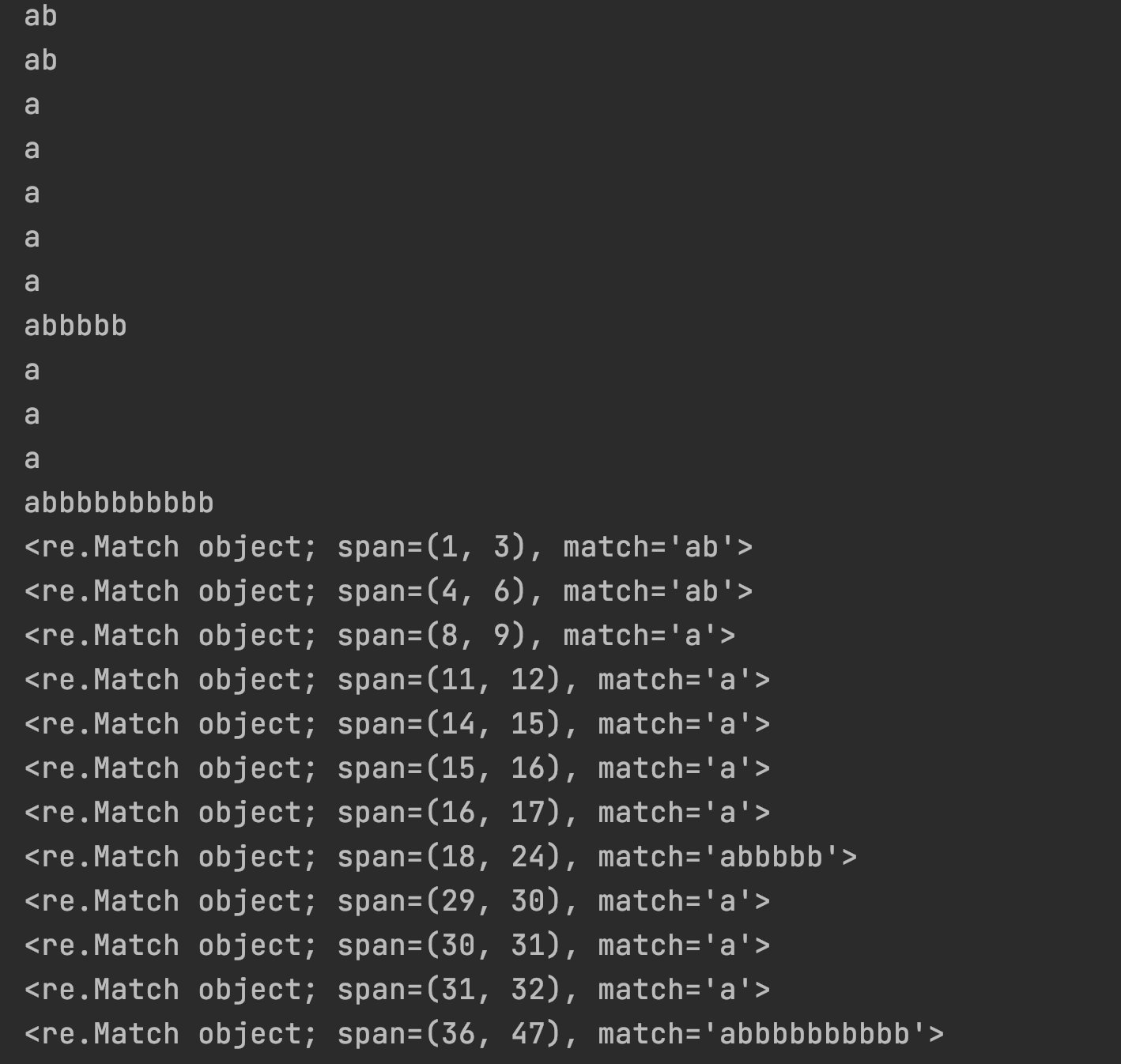
import re
p = re.compile("p[\w]*n") # p와 n사이 여러개의 문자,숫자
m = p.match("python is easy")
print(m)
print(m.group())
print(m.start())
print(m.end())
print(m.span())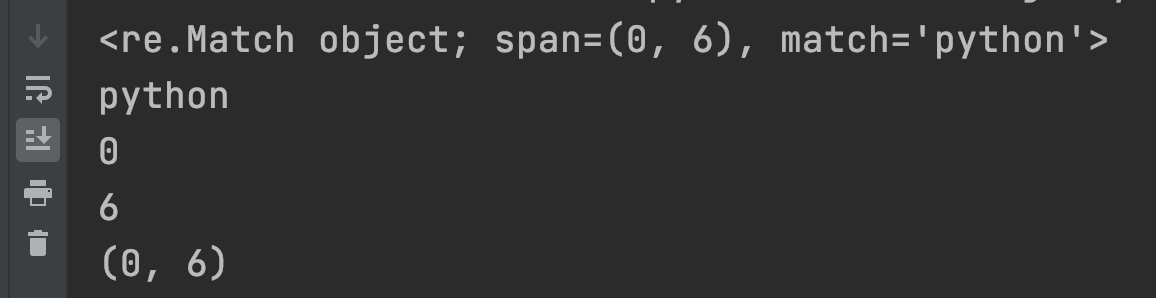
\n : 엔터는 문장을 분리할 때 중요한 역할.
dotall : 엔터도 문자로 쓰겠다. (엔터도 문자로 포함, 여러 줄의 문자열에서 엔터에 상관없이 검색할 때 많이 쓴다.)
import re
p = re.compile("a.b")
m = p.match("a\nb")
print(m)
p = re.compile("a.b", re.DOTALL) # re.S도 같음
m = p.match("a\nb")
print(m)
Ignorecase : 대소문자 구분 없이 무시
import re
p = re.compile("[a-z]", re.IGNORECASE) # re.I 도 같음
# p = re.compile("[a-zA-Z]")
m = p.match("python")
print(m)
m = p.match("Python")
print(m)
m = p.match("PYTHON")
print(m)
# python으로 시작하고, whitespace(공백문자), 숫자or문자가 1개 이상
import re
p = re.compile("^python\s\w+") # [^]에서는 not, ^는 시작
data = """python one
life is too short
python two
you need python
python three"""
m = p.findall(data)
print(m)
multiline : 각 줄
# ^python python으로 시작
# python$ python으로 끝
# 와 re.MULTILINE은 함께 사용된다
import re
p = re.compile("^python\s\w+", re.MULTILINE) # re.M 같은 의미
data = """python one
life is too short
python two
you need python
python three"""
m = p.findall(data)
print(m)

# import re
# p = re.compile("Crow|Servo") # Crow든 Servo든
# m = p.match("CrowHello")
# print(m)
# m = p.match("ServoHello")
# print(m)
# import re
# p = re.compile("^Life") # 시작이 Life
# m = p.match("Life is too short")
# print(m)
# import re
# p = re.compile("short$") # 끝이 short
# m = p.search("Life is too short")
# print(m)
# m = p.search("Life is too short, you need python")
# print(m)
import re
# p = re.compile("ABC+") # AB다음에 C가 1개 이상
p = re.compile("(ABC)+") # ()는 그룹을 만든다, ABC가 1개 이상
m = p.search("ABCABCABC OK?")
print(m)
print(m.group())

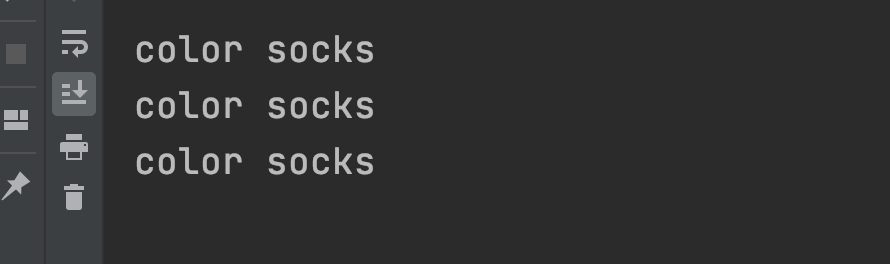
blue나 white나 red를 color로 바꿔라
# 문자열 바꾸기
import re
p = re.compile("(blue|white|red)")
data = """
blue socks
red socks
white socks
"""
print(p.sub('color', data))