Nginx + Django + Postgresql 도커 컴포즈를 통한 EC2에서의 배포 후기
글쓰기에 앞서 준비물
AWS EC2 인스턴스 생성시에 이미지는 free tier 를 사용하여도 좋으나
인스턴스 타입(pc사양) 은 ram 2gb 인 t2.small 이상 사용 권장
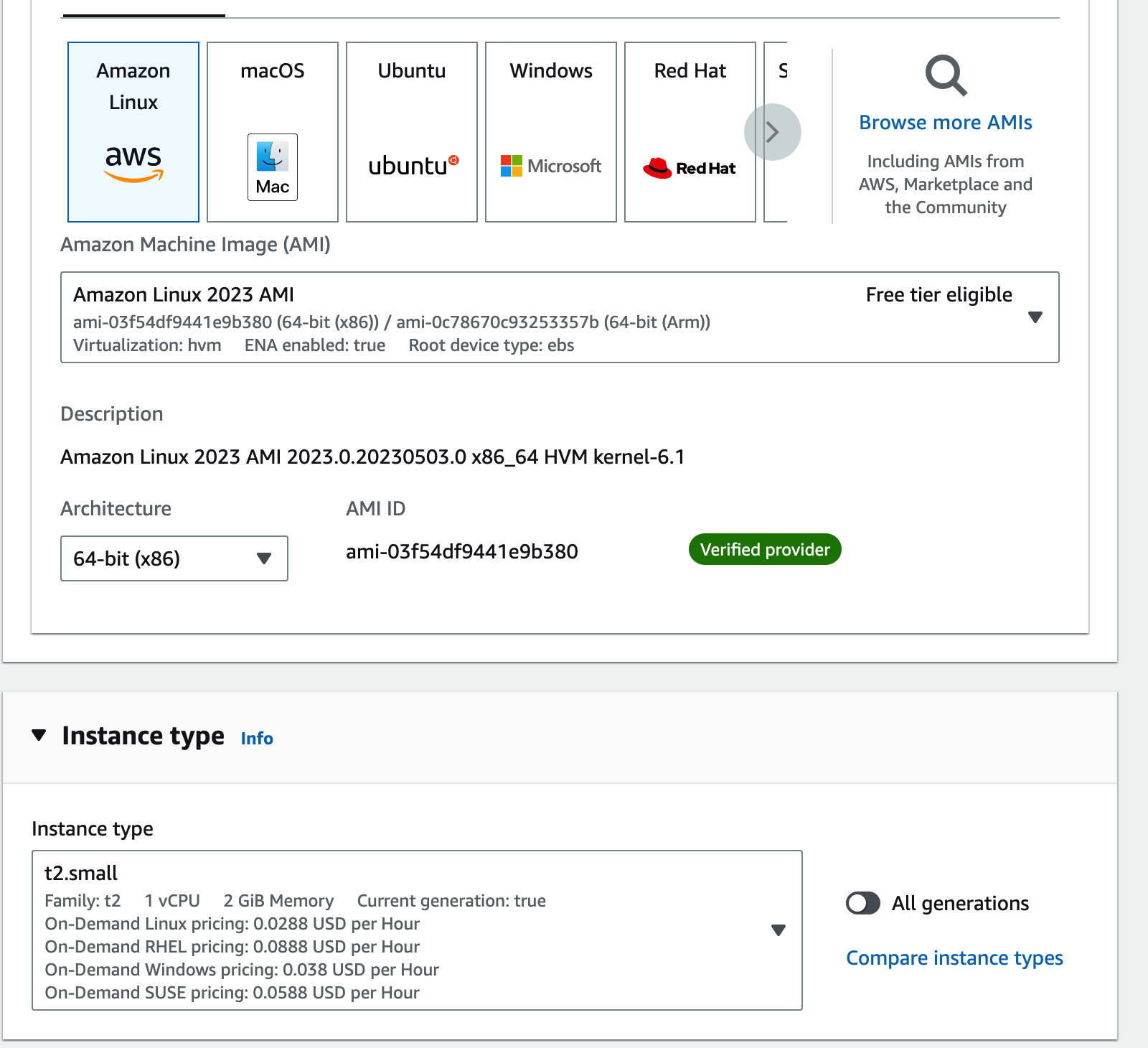
(t2 small, 2gb RAM)
Key Pair를 pem , ppk 로 받을 수 있다.
윈도우로 원격 컴퓨터에 접속시 : putty 사용 -> ppk 필요
MacOS, WSL 에서 CLI 환경에서 접속을할 때 -> pem 필요
pem에 권한이 644 로 되어 있는데, chmod 400 <이름.pem> 으로 바꿔줘야 원격 접속 시에 문제가 안 생긴다.
세자리 숫자가 각각, 소유자/그룹/외부인 으로 해서
User/ Group/ Others
100(4) 000(0) 000(0)
암호키에 대한 읽기 권한을 소유자 빼고는 접근할 수 없게 해놓아야 한다
CLI 로 ssh 프로토콜을 이용하여 원격 서버에 접근하는 커맨드는 다음과 같다
ssh -i /path/<name.pem> 사용자이름@ip_address
CLI 환경에서 접속하면 현재위치(pwd)에서의 상대경로로 적어줘도 되고

원격 서버 접속을 이용하면 pem 파일의 절대경로를 다 적어줘야한다.
맥 터미널에서 새로운 원격 연결은 윈도우에서 따로 설치해준 putty랑 비슷한거다.

현재 해결한 문제:
pem파일 권한 이슈(chmod 400 <name.pem>)
ssh -i 커맨드로 접근할 때 상대경로와 절대경로 개념
ssh -i <암호키> <사용자 @ 서버ip>
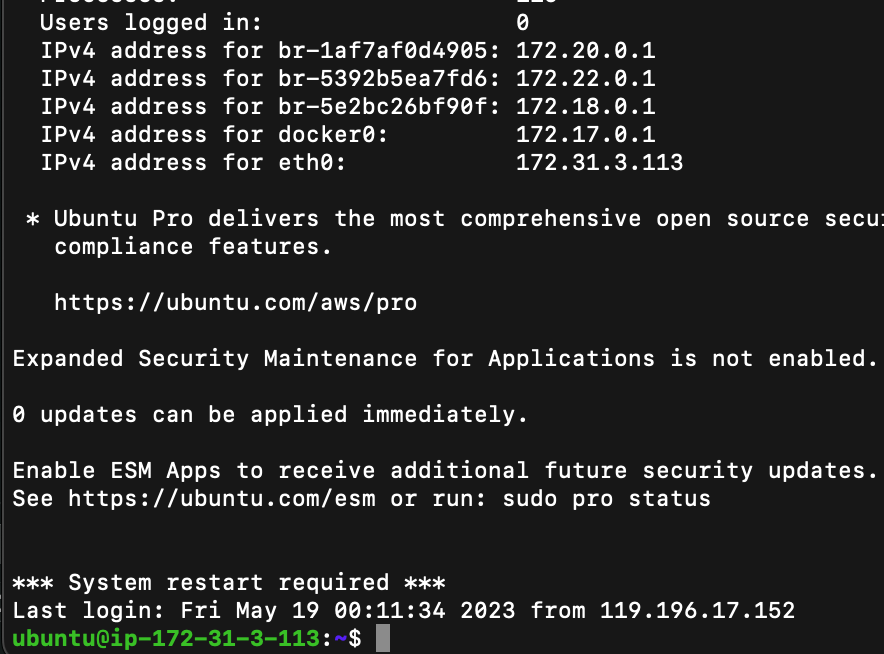
AWS에서 ec2 인스턴스 이미지를 ubuntu 로 만들었으면 ubuntu@ 입니다 ^^
원격 컴퓨터에 들어왔다.!
나는 52.으로 시작되는 ip 에 들어왔는데
172.31.3.113 이다. 왜일까?
공용 ip 와 VPC(가상 사설 클라우드) 에서의 사설 ip이다.
52.으로 시작되는, 강사님이 주신 혹은 인스턴스를 생성할 때 ip v4 퍼블릭 ip로 받았던 주소가"세상에서 접근할 수 있는 주소인 것이다"
172로 시작하는 사설 ip 주소는 생각하면 안방인 것이다
나의 자취방 주소는 도로명 주소를 따라
신림로 11길 55로 시작한다. 172.~~ 으로 시작되는 사설 ip는
신림로 11길 55의 안방, 거실, 화장실 이라고 생각하면 된다.ubuntu@신림로11길55,601호
는 유일하지만
ubuntu@거실
은 전세계에 너무 많을 것이다.
Summary:
" 접속할 때, 웹, 외부에서 접속할 때, 서버 터미널에 떠있는 사설 ip로 접속하면 안된다 "
이제 기본 세팅을 해야 하겠지.
리눅스 환경에서 뭔갈 하기 전엔 항상
sudo 권한에서 apt 혹은 apt-get을 upgrade, update하고 시작한다.
이 둘의 차이는 내 조교가 이와 같이 적어놨다.
Summary:
"apt가 apt-get을 대체하기 위해 등장했지만, apt-get도 여전히 많이 사용된다 ."
이제 첫번째로 해야할 것
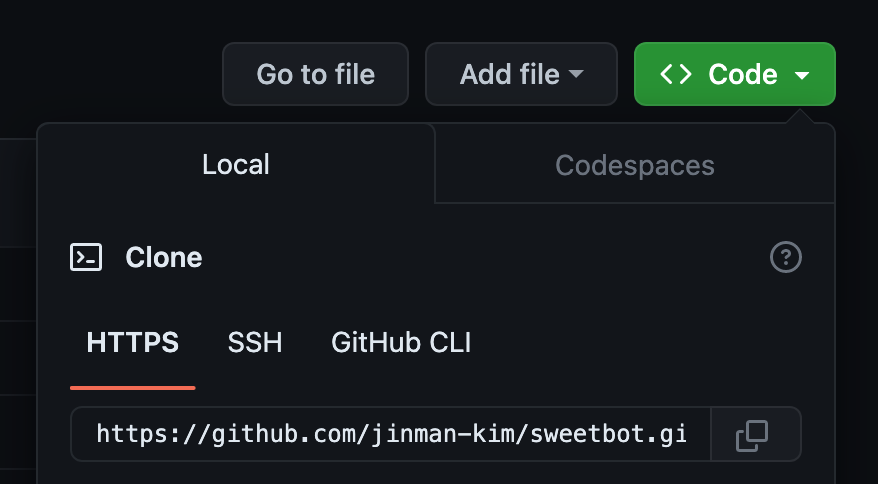
git clone repo_url
배포할 git의 주소를 갖고 클론하면 된다.
종종 git clone 시에
username , password를 요구할 때가 있다.
repository가 private이거나 모종의 이유로.?
근데 여기서 username은
나의 경우 왼쪽의 jinman-kim 이다.
username / repo_name
그럼 password는 git 계정의 비밀번호일까?
-->아니다 !
깃허브에 로그인 한 상태로
https://github.com/settings/tokens
위 url 에 접근하면 generate token 하여 발급 받을 수 있다.
암호가 한번 주어지면 휘발되기 때문에
키체인(암호 지갑) 혹은 본인의 소중한 곳에 알아볼 수 있게 저장해놔야한다.
2021년 8월 이후로 Git 정책이 바껴서 보안이 강해진 것 같다.
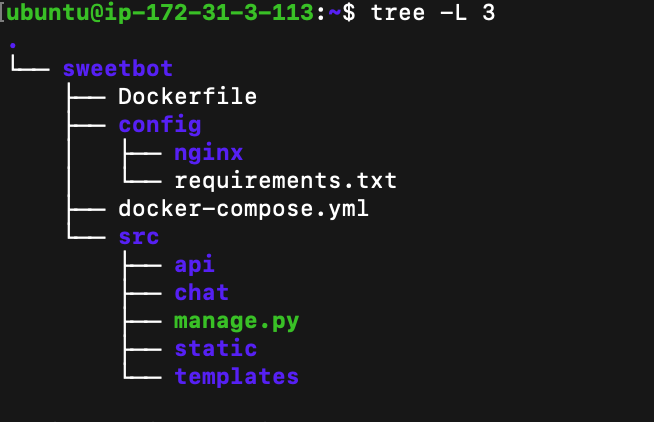
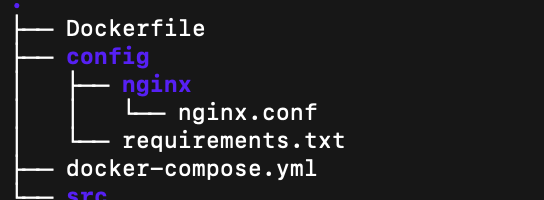
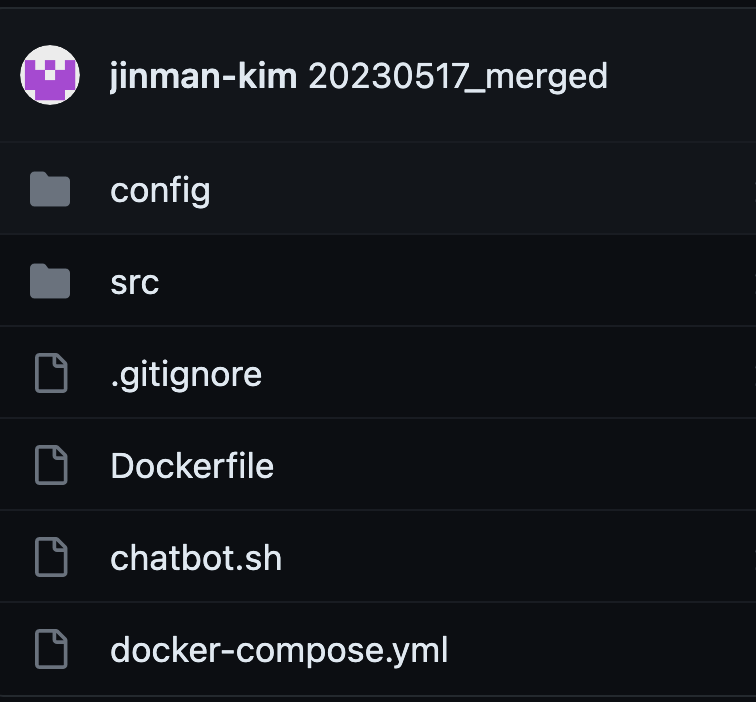
그렇게 클론이 떠지고 나서 나의 프로젝트 구조도이다.
tree 명령어는 리눅스에서
apt install tree
하면 사용할 수 있다
-L 옵션은 레벨이다. 통상 2~4 를 많이 쓰고 전체적으로 보고 싶으면
-R 옵션을 쓰면 끝까지 보인다. ( root/뿌리인가, right/오른쪽 끝까지 인가)sweetbot 프로젝트를 git으로 땡겨오면 루트 단에는
디렉토리: config, src
파일: Dockerfile, docker-compose.yml
2개의 파일과 2개의 폴더로 구성되며,
config에는 nginx 세팅이 들어있는 nginx.conf 파일과
django image 빌드에 사용될 requirements.txt 파일이 들어 있다.
src는 장고 프로젝트의 전체 소스가 들어 있다.도커 컴포즈를 들여다보자
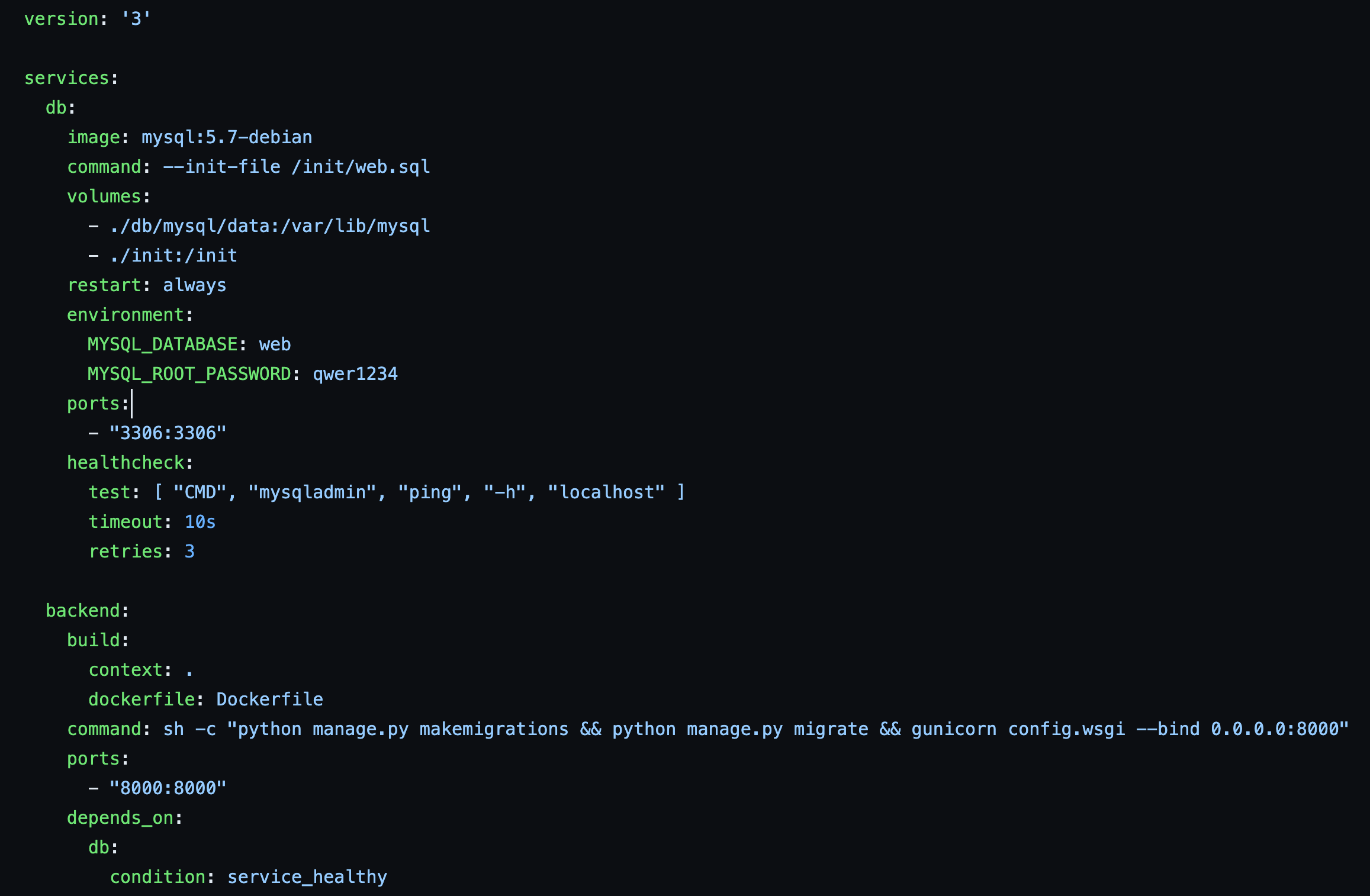
docker-compose.yml
version: "3" services: nginx: image: nginx:1.17.10 container_name: ng01 ports: - "80:80" volumes: - ./src:/src - ./config/nginx/nginx.conf:/etc/nginx/conf.d/default.conf depends_on: - web web: build: . container_name: dg01 command: bash -c " python3 manage.py collectstatic --no-input && python3 manage.py makemigrations && python3 manage.py migrate && gunicorn chat.wsgi:application -b 0:80" depends_on: - db volumes: - ./src:/src db: image: postgres:12.2 container_name: ps01 environment: POSTGRES_DB: db POSTGRES_USER: admin POSTGRES_PASSWORD: admin ports: - "5432:5432"volumes
volumes는 볼륨을 공유하는 것이다. 즉 지금 서버에 실제로 깔려있는 소스코드와 파일들을 토대로 컨테이너에 가상화 함을 의미한다.
왼쪽이 해당 위치의 실제 파일, 오른쪽이 컨테이너에서 가상화할 위치
아래 코드를 다시 같이 보자
: 이 콜론, 땡땡이를 기준으로 왼쪽이 호스트pc의 파일들의 위치이다.
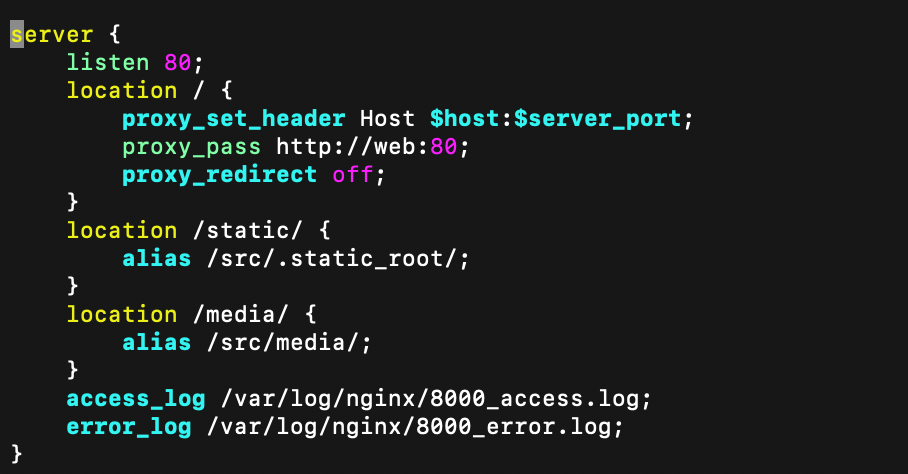
config/nginx/nginx.conf 가 어디 있나???
nginx 세팅에 대한 conf 파일이 바로 여기 있다.
이 파일에 내용을 컨테이너에 etc/nginx/conf.d/default.conf에 가상화한다는 것이다.
왼쪽 즉, 호스트 pc에서의 nginx 설정 파일은 각자 제각각일 것이다.
그런데 오른쪽 컨테이너에 마운트 하는 것이다.
nginx.conf 세팅은 내마음대로 멋대로 해도 된다.
하지만 nginx:1.17.10 이미지를 땡겨와 생성한 컨테이너에 nginx.conf 세팅파일을 마운트 하는 위치는 어느정도 정해져있다../src : /src 는 왜 공유 하는가?
src 는 나의 장고 소스코드를 모아놓은 디렉토리이다. 근데 이걸 왜 nginx 컨테이너가 공유하고, 마운트해서 가져가나??
static, media 등 정적 파일을 효율적으로 서빙하기 위해서이다. 그리고 프록시 밸런싱을 해주기 위해서이다.
proxy 세팅으로 기본적인 로드 밸런싱 역할을 해주며, volumes에서 공유한 src path를 토대로 static과 media 의 location에서 정적 파일을 서빙합니다.
access_log와 error_log는 컨테이너에서 발생했던 접근과 에러 로그 데이터를 저장하는 것 같습니다.
이것이 nginx의 주요 기능이다.
왜냐고 묻지말기 !!
WAS(Web Application Server)는 따로 구현하지 않았습니다. 그렇담 WAS는 뭐냐?
위의 조교의 설명을 읽어주세요 ^^
image : 사용할 nginx의 이미지 버전
container_name: 컨테이너명 ( ng01 )
ports: '80:80' 호스트의 80번 포트를 컨테이너의 80번 포트로
volumes: 호스트파일위치: 컨테이너위치
depends_on: 컨테이너명(해당 컨테이너에 의존성을 두고 해당 컨테이너가 켜져야 켜짐)단 컴퓨터의 입장에서 생각해봤을 때, 의존하는 컨테이너가 켜지고 따라쟁이 컨테이너가 바로 켜지는 게 이상적이지만, db의 경우 테이블 생성하는 데에 시간이 걸릴 수 있다. 우리도 컴퓨터와 휴대폰을 껐다 키면 부팅 시간이 있듯이, 하지만 이 사안에 대해 시간을 걸어서 sleep 10, sleep 20 이렇게 원시적으로 할 것인가?
크롤링 좀 해본 사람들이라면 아는
selenium의 implicitly_wait 메소드를 생각하면 좋다
time.sleep(시간) 과 같이 원시적으로 기다리는 것이 아닌
html에서의 원하는 element가 렌더링 될 때까지 기다리는 implicitly_wait 메소드와 비슷하다.
DB의 건강 상태를 체크 해주는 환경설정을 해주고
WEB에서는 DB의 상태가 건강이면 켜지는 것이다.
이 건강은 TABLE의 생성 여부로 확인할 수 있다.
아래가 레퍼런스하기 좋은 코드이다.
DB 컨테이너의 설정을 크게 볼 게 없다.
Volumes 설정을 아직 안했다.
실제 데이터를 적재할 서비스는 오픈 예정 중에 있다.
현재 서버의 사양만 업그레이드 하면 db도 분리할 필요가 없을 것이다.
유저들의 정적 파일을 수집하게 되면 S3 버킷을 이용할 예정이다.web
web: build: . container_name: dg01 command: bash -c " python3 manage.py collectstatic --no-input && python3 manage.py makemigrations && python3 manage.py migrate && gunicorn chat.wsgi:application -b 0:80" depends_on: - db volumes: - ./src:/src




컨테이너 이름은 django라 dg01 로 설정하였다.
build : .
경로에 있는 Dockerfile을 읽고 이미지로 잘 구워서 장고 이미지를 만들기 위해
command:
collectstatic 명령어는 정적 파일(static) 을 수집하여 nginx에게 전달해 주는 것이다. 그래야 효율적으로 제공하고, 관리상에 문제가 없음. settings.py 에 STATIC_ROOT=BASE_DIR + 'staticfiles' 등으로 본인에 맞게 커스터마이징해서 설정해주셔야 합니다
makemigrations, migrate는 db 최신화를 한번 해주고,
gunicorn은 nginx를 구동하기 위해 사용합니다. chat.wsgi는 통상
프로젝트를 생성하면 wsgi, asgi, settings, urls 있는 경로를 명시해주면 됩니다. 포트를 바인딩 해줍니다.
chat.wsgi:application
이렇게 하면 얼추 끝납니다.
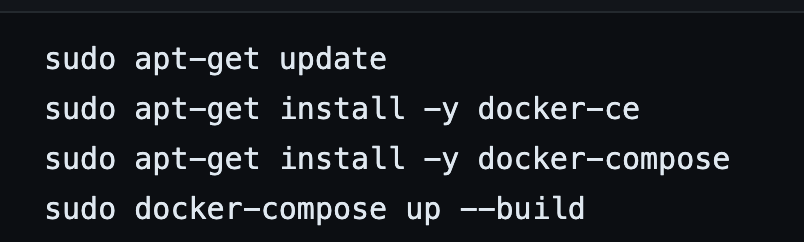
이 모든 과정을 수행하는 게 너무 복잡해서 쉘 스크립트 파일인 .sh 파일을 깃에 같이 올려놨습니다. 아래 과정을 수행하면 끝납니다.
- 서버에 접속
- git clone repo_url
- cd repo_name
- sudo source name.sh
이렇게 하면 개발 환경 구축이 끝나게 해놨습니다.
레포지토리 구성
chatbot.sh
못다한 얘기
1. 시크릿 키 관리
pip install environ .env 파일을 통해 시크릿키 관리를 할 수 있습니다. git에 올리면 절대 안돼요 그래서 .gitingore에 .env 추가 해주세요2. CSRF_TOKEN 문제
배포 환경에서 POST요청에 대해 프론트에 {%csrf_token} 넣어줘도 403 에러가 발생하길래 보니까 Django 4.0이상 버전에서는 settings.py에 아래와 같이 해당 IP와 DNS 설정 추가해줘야함 CSRF_TRUSTED_ORIGINS=['https://127.0.0.1', ~~]3. 인스턴스 생성 시에 보안 그룹 규칙 추가
인바운드 규칙이라고 하는데 80번 8000번 등 0.0.0.0/ 설정 해줘야함 추가적인 공부가 필요하긴 한데 80번으로 열면 다 들어올 수 있음. 근데 처음에 부여받은 서버를 사용해서 배포를 하였고, 도커 컴포즈가 성공하였는데, 외부에서 서버주소로 접속이 안되길래 2시간 헤매면서 ifconfig, ping, netstat, firewall, iptables 와 같이 네트워크 관련 명령어를 모두 사용했는데 안돼서 애를 먹었는데 알고보니 인바운드 규칙에서 외부접속을 허용을 안했었던 것. 인스턴스 생성시에 꼭 고려하고 그 후에도 추가, 제거할 수 있음^^4. 인스턴스를 껐다 켰다할 때 자꾸 ip가 바뀌는거?!
계속 바뀌길래 알아보니까
탄력 ip에서 설정해주면 안바뀜 ! 근데 탄력 ip면 탄력적이어서 바껴야 되는거 아닌가 ㅋ?5. 인스턴스를 꺼놓고 1년뒤에 켜도 데이터가 살아있나?
billing 부담을 줄이려고 인스턴스를 저녁과 주말에는 꺼놓는데, 1년뒤에 켰을 때 데이터가 살아 있으면 결국에 AWS가 계속 컴퓨터에 대한 데이터를 유지해주고 init을 안한다는건데, 과연 그런가요?? 이 부분에 대해서는 정확히 모르겠네요. 아는분께서는 댓글 혹은 gameliker16@naver.com 의견 보내주세요.
추후 고민해야 할 내용
- S3 버킷 연결에 대한 고민,
다이어리 기능의 앱이 있는데 유저들이 POST 하는 이미지 데이터를 현재는 EC2 내부에 담고 있습니다만..
국룰 아키텍처를 따졌을 때, S3 버킷 연결은 필수적이기 때문에 연동을 하겠습니다!- 아키텍처를 추후 어떤 방향으로, 서비스는 어떤 방식으로 구현할 것인지, WAS에 대해서 공부하고, Nginx도 더 공부하고 가야할 길이 많습니다!
- 서비스에 대한 설명은 거의 안드렸습니다만, 현재 Openai의 API를 이용한 챗봇 기능을 서빙하는 간단한 기능의 웹서비스입니다. text-davinci-003 모델을 이용하였고, 세션을 토대로 프롬프트를 주고 받는데, 서버에 직접 통신하는 것이 아닌
Client - 내 서버 - OpeaAI 통신 과정을 겪다보니 느리고, 이용하는 모델의 퀄리티가 이상적이지는 않습니다 ^^. 추후에 추가할 기능은
비회원 사용자들의 채팅을 mongodb에 적재하고 일단위로 00시에 1회 배치로 분석할 예정입니다. 분석 소스코드는 aws 람다를 이용할 예정입니다. 비슷한 서비스로는 GCP의 Function이 있으나 AWS 생태계가 익숙한 저에게 Lambda가 합리적이겠네요. 비용을 따질 규모의 프로젝트도 아니기 때문이지요 ^^- 세션과 쓰레드를 이용한 OpenAI API 와의 통신
현재는 세션과 쓰레드를 이용하여 챗봇을 이용하고 있지만,
안정성이 떨어진다고 느껴집니다.
views 단에서의 채팅 로직을 구성하는 데에 있어서
이해와 실력 부족도 있겠지만요.
비동기 통신을 이용해야겠다라는 생각이 들었습니다.
asgi에 대해 공부해봐야겠습니다. feat.daphne- 장고 관점에서 봤을 때의 views 단의 complexity 해소
views.py 에 챗봇 로직이 다 들어 있습니다.
views.py는 비춰주는 역할을 해야하는데, 서비스 내용이 들어있다면
추후 유지보수 측면에서 불리하고,
새로운 동료가 코드를 확인했을 때에 난잡할 수 있습니다.
services.py 를 앱 단위로 만들어 서비스는 분리해주세요
그리고 호출해주세요.
