flume 기본
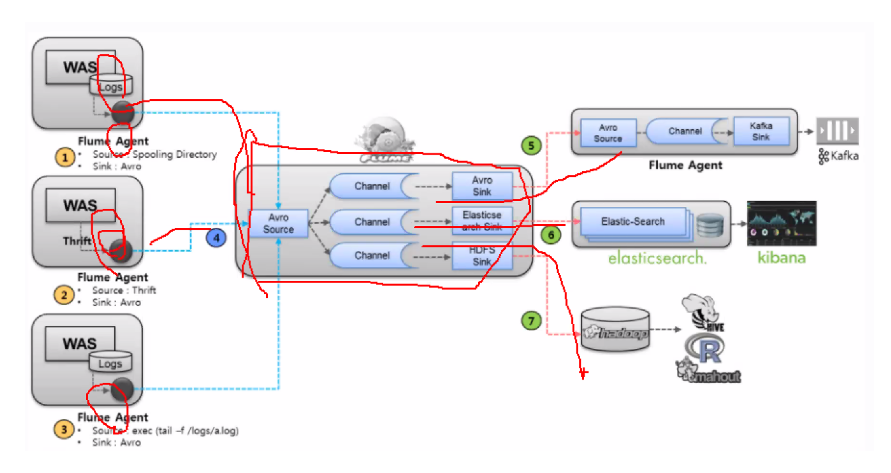
여러 was, pod라고 볼수도 있고, 각 was에 Flume Agent를 배치하고
flume으로 갖고오면
Source -> Channel -> Sink 과정을 거쳐서
1. 또 다른 Flume Agent를 줄 수도 있고,
2. ELK(Elastic-Search, Logstash, Kibana) 줄 수도 있고,
3. 하둡+(하이브,슈마허) 줄 수도 있음.
즉 Message Broker 느낌도 있는듯?
flume이 kafka랑 비슷해보이는데... 그럼 차이는?
Flume:
데이터 수집 및 로그 전송을 위한 분산 시스템입니다.
Flume은 로그 데이터를 수집하고 신뢰성 있는 방식으로 중앙 집중형 데이터 스토리지 또는 분산 시스템으로 전송합니다.
Agent, Source, Channel, Sink 등으로 구성되며, Source는 데이터 소스에서 데이터를 수집하고, Channel은 데이터를 보관하며, Sink는 데이터를 대상 시스템으로 전송합니다.
주로 로그 파일, 디렉토리, 웹서버 로그 등의 데이터를 수집하고, Hadoop HDFS, Apache HBase, Elasticsearch 등과 같은 시스템으로 전송할 때 사용됩니다.Kafka:
분산 스트리밍 플랫폼으로, 대량의 데이터를 실시간으로 처리하는 데 중점을 둡니다.
메시지 큐 시스템으로, 데이터 스트리밍과 이벤트 처리를 지원합니다.
데이터는 Topic으로 구성된다. Producer가 데이터를 Topic에 전송하고, Consumer가 Topic에서 데이터를 읽을 수 있습니다.
데이터는 영속적으로 보관되며, 다양한 Consumer가 동일한 데이터를 읽을 수 있습니다.
스케일 아웃 및 고가용성에 강점을 가지며, 실시간 데이터 처리, 로그 분석, 웹 애플리케이션 모니터링 등에 사용됩니다.
요약하자면, Flume은 데이터 수집과 전송에 중점을 둔 분산 시스템이고, Kafka는 대량의 실시간 데이터 처리와 이벤트 스트리밍을 위한 분산 스트리밍 플랫폼입니다. Flume은 데이터를 수집하여 다른 시스템으로 전송하는 데 사용되며, Kafka는 메시지 큐 시스템으로 데이터를 실시간으로 처리하고 스트림으로 전달하는 데 사용됩니다. 선택은 사용 사례, 요구 사항 및 아키텍처에 따라 달라집니다.
하둡
파일 생성, 삭제, append 만 가능 (즉, 수정 불가)
NO MODIFY!!
