
Kafka를 파헤치기 전, 메시징 시스템에 대해 알아보자.
✨메시징 시스템
- MSA (MicroService Architecture)의 일반적인 데이터 송수신 방법 => 메시징 시스템
Kafka,RabbitMQ,Active MQ,AWS SQS,Java JMS등- MSA는 시스템 간 호출이 많기 때문에 서비스간 아래와 같은 이점이 있기에 메시징 시스템을 사용한다.
- +결합도를 낮추기 위해
- +비동기 요청
- +성능
- +안정성 등
- 대략적인 메시징 시스템에 대해 알아보자
🕶용어
- MOM (Message Oriented Middleware, 메시지 지향 미들웨어)
- 독립된 애플리케이션 간의 데이터를 주고받을 수 있도록 하는 시스템 디자인(인프라 아키텍쳐)
- 함수 호출, 공유 메모리 등을 사용하지 않고 메시지 교환을 이용하는 중간 계층에 대한 인프라 아키텍쳐
- 분산 컴퓨팅 가능
- 서비스간 결합도 감소
- 비동기 메시지 전달
- Queue, Broadcast, Multicast 등의 방식으로 메시지 전달
- 🎈
Pub/Sub구조- 메시지 발행 : Publisher(Producer)
- 메시지 소비 : Subscriber(Consumer)
- 독립된 애플리케이션 간의 데이터를 주고받을 수 있도록 하는 시스템 디자인(인프라 아키텍쳐)
- Message Broker
- 메시지 처리 or 메시지 수신자에게 메시지를 전달하는 시스템
- 일반적으로
MOM기반 구축
- MQ (Message Queue)
Message Broker와MOM을 구현한 소프트웨어 (RabbitMQ, Active Mq, Kafka 등)MOM은 메시지 전송을 보장 해야하므로AMQP를 구현한다.
- AMQP (Advanced Message Queueing Protocol)
- 메시지를 안정적으로 주고받기 위한 인터넷 프로토콜
- =>
MQ는 "AMQP를 구현한 MOM 시스템이다." 물론, 각 소프트웨어 마다 장단점이 있다.
📪메시징 시스템?
- "문자, 이메일 같은 메시지들을 처리하는 시스템?"
- 위에 국한되지 않고
로그 데이터,이벤트 메시지등 API로 호출할 때 보내는 데이터들을 처리하는 시스템 - 예제) 자동 메일 발송 시스템
- 회원가입 시, 이메일을 발송하는
MemberService - 주문 완료 시, 이메일을 발송하는
OrderService - 메일을 실제 발송하는
MailService - 프로세스
MemberService에서 회원가입,OrderService에서 주문완료 이벤트 발생Messaging Client로 메일 전송에 필요한 데이터를 API로 호출Messaging Client에서MOM을 구현한 소프트웨어(ex) Kafka)로 메시지 생산MailService에서 메시지가 존재하는지 구독하고 있다가 메시지가 존재하면 메시지 소비MailService에서 API 정보들을 통해 User에게 메일 발송
- Publish/Subscribe or Producer/Consumer 구조
- 회원가입 시, 이메일을 발송하는

🎃장/단점
- 장점
- 결합도를 낮춰 비즈니스 로직에 집중할 수 있다.
- 메시지 처리 방식은
Message Broker에게 위임- => 각 서비스는
Message Client를 통해 메시지를 보내고 받기만 함
- => 각 서비스는
- 비동기 방식으로 메시지를 보내기만 하면
Message Broker에서 순서 보장 + 메시지 전송 보장 - 메시징 시스템이 잠깐 다운돼도 각 서비스에는 직접적인 영향을 미치지 않음
- 단점
Message Broker구축- ex) Kafka를 구축하는 데 필요한 비용, 인적자원에 대한 비용
- 비동기의 양면성
- 함수 호출, 공유 메모리 사용방식보다 네트워크 비용 증가 (호출 구간이 늘어남)
🍙Kafka
🍉1. Kafka 아키텍쳐

- Zookeeper
- 클러스터 최신 설정정보 관리, 동기화, 리더 채택 등 클러스터의 서버들이 공유하는 데이터를 관리
- ≒
Broker에 분산 천리된 메시지 큐의 정보들을 관리
- ≒
Zookeeper는 클러스터를 관리하기 때문에Zookeeper가 없다면Kafka구동 불가- 즉,
Kafka서버를 가동하기 위해서Zookeeper를 먼저 가동해야 한다.
- 즉,
- 클러스터 최신 설정정보 관리, 동기화, 리더 채택 등 클러스터의 서버들이 공유하는 데이터를 관리
- Broker
Kafka의 서버- 한 클러스터 내에서 여러
Broker를 띄울 수 있다.
- Topic
- 메시지가 생산되고 소비되는 주체
- ex) 카카오톡 단체방 A, B가 있을 때, A로 보낸 메시지가 B에 노출되면 안된다.
- = A 방에서 생산된 메시지는 A 방에 존재하는 사람들(구독한 사람)에게만 보여야한다.
- ex) 카카오톡 단체방 A, B가 있을 때, A로 보낸 메시지가 B에 노출되면 안된다.
- 주제에 따른 여러 Topic 생산 가능
- ex) email topic, sms topic, push topic
- 메시지가 생산되고 소비되는 주체
- Partition
Topic내, 메시지가 분산되어 저장되는 단위- ex) 한
Topic에Partition이 3개 있다면, 3개의Partition에 대해 메시지가 분산 저장 되어있음을 의미한다. Queue로 저장,Partition내 순서는 보장되지만,Partition끼리는 메시지 순서를 보장하지 않는다.
- ex) 한
- Log
Partition의 한 칸key,value,timestamp로 구성
- Offset
Partition의 메시지 식별값(unique)- 메시지를 소비하는
Consumer가 읽을 차례를 의미. ->Partition마다 별도로 관리 0시작,1씩 증가
☕2. Producer/Consumer Group
-
메시지 생산/소비
-
Producer
Producer는 정해진Topic으로 메시지를 기록Partition이 여러 개일 경우, 기록될Partition의 선택은 기본적으로 Round-Robin 스케줄링 알고리즘 방식을 채택- 여러 개의
Partition은 병렬 처리라는 장점이 있지만, 갯수는 주의해서 설정해야한다.
- 여러 개의
- 각
Partition내에서는 마지막offset뒤에 신규 메시지가 저장되므로,Partition내에서는 순서가 보장되고 기록된다.
-
Consumer Group
Consumer Group은 하나의Topic을 담당- 한
Topic은 여러Consumer Group에 접근 가능 - 한
Consumer Group은 한Topic에 접근 가능
- 한
- 존재 이유
- 가용성
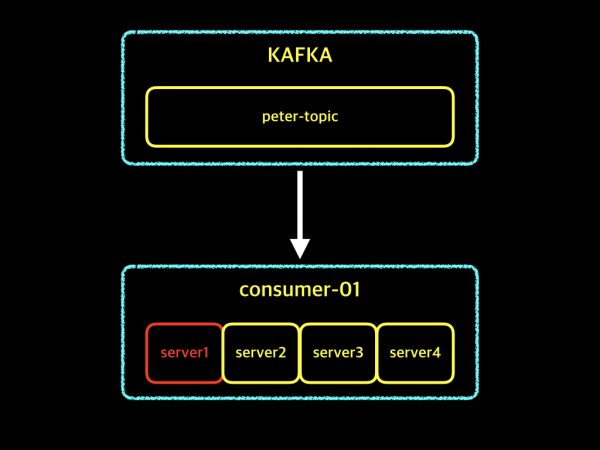
- consumer-01(
Consumer Group)이 perter-topic(Topic) 데이터를 가지고 있을 때, 서버 1개(server1-Consumer Instance)가 장애가 발생해도 나머지 서버들을 통해 계속해서 작업을 이어갈 수 있다.
- consumer-01(
- Consumer Group 구분 및 offset 관리
- 💥문제 상황 ex) 사용자
A,B가 있고, 두 사용자가 동일한topic에 대한 데이터를 가져가고 싶다.Consumer Group은 없다.
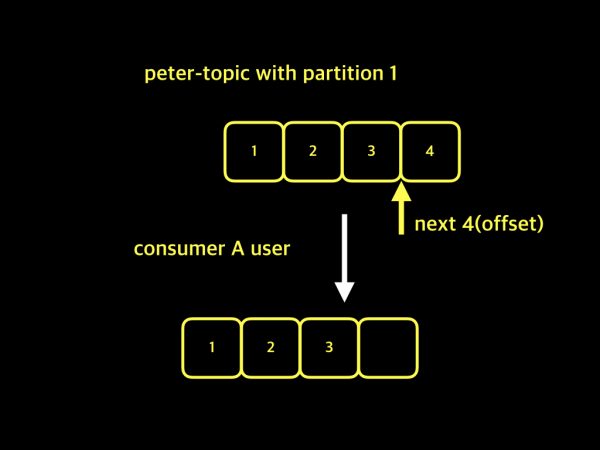
A가 1, 2, 3의 데이터를 가져갔고 next(offset)를 4로 설정- 이 때,
Consumer Group이 없기 때문에Kafka는Consumer가 연결됐을 뿐, 구분을 하지 못한다.
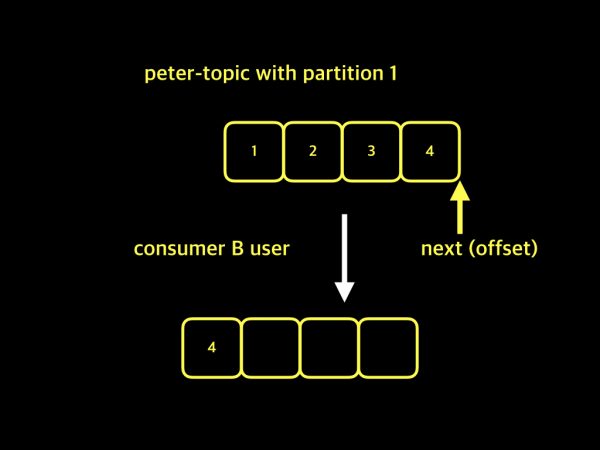
B가 데이터를 가져올 때,A가 저장한offset정보부터 데이터를 가져온다.- +
A가 다음으로 가져오기를 희망한 데이터는 4지만offset이 그 다음으로 설정되었기 때문에 문제가 발생한다.
- ✨해결 상황 :
Kafka에서Consumer Group마다 이름을 지정하여 구분하고, 그룹별로offset을 관리
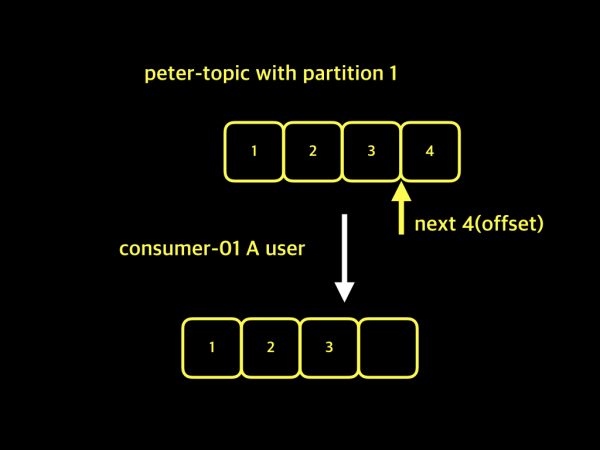
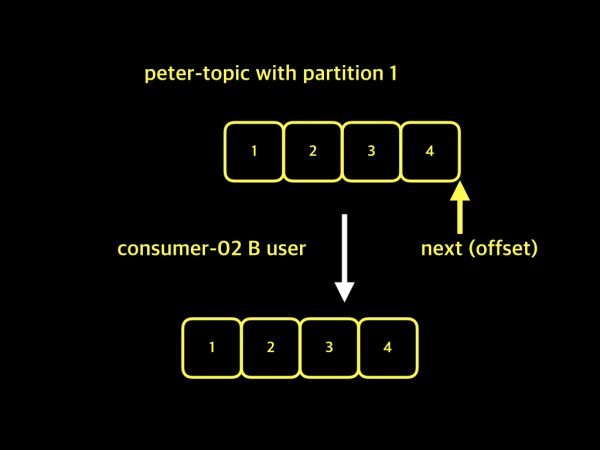
- 각
Consumer Group이Topic에 있는 데이터를 가져올 때, 하나의Topic이지만 그룹별로 각 다른 데이터를 가져오고,offset을 설정한다.
- 각
- 💥문제 상황 ex) 사용자
- 가용성
-
-
Partition(P)과 Consumer(C)의 관계
Kafka의 Consumer Instance 제약사항- 카프카에서는 하나의 파티션에 대해 컨슈머 그룹 내 하나의 컨슈머 인스턴스만 접근 가능하다. 즉,
ordering(순서) 보장하기 위함 (=>Partition갯수 <Consumer Instance, 불가능)
- 카프카에서는 하나의 파티션에 대해 컨슈머 그룹 내 하나의 컨슈머 인스턴스만 접근 가능하다. 즉,
- P 1개 / C 인스턴스 1개
- 대량으로 생산되는 메시지를 처리할 수 있도록 서버(
Consumer Instance)를 늘리자!
- 대량으로 생산되는 메시지를 처리할 수 있도록 서버(
- P 1개 / C 인스턴스 4개
Consumer Instance를 늘렸지만, 1개의 파티션은 1개의 컨슈머 인스턴스만 접근 가능하다. => 소용이 없다.
- P 4개 / C 인스턴스 4개
- 1:1 구성 => 이상적인 상황
- P 4개 / C 인스턴스 3개
- 한 개의
Consumer Instance가 죽었지만Consumer Group에서offset이 공유되기 때문에 이상이 없다.
- 한 개의
- 이후, 메시지가 잘 처리되어
Partition3개로 줄이고자 했지만Partition은 늘리면 줄일 수 없다.

🧨3. Consumer Design (부제: RabbitMQ와 Kafka 비교)
- 같은 분산 큐 시스템이어도 소비자(Consumer)가 메시지를 처리하지 못하면 성능은 느려진다.
Kafka는 Multi Consumer를 염두에 두고 설계됐다.- RabbitMQ
Message Broker가Consumer에게 push- 메시지의 소비 속도보다 생산 속도가 빠르면?
Consumer에게 부하 RabbitMQ는DRAM(buffer)를 사용하지만,DRAM을 다 사용하면디스크에 저장 =>batch같은 큰 작업에서디스크로 메시지를 읽어올 경우 지연된다.
- 메시지의 소비 속도보다 생산 속도가 빠르면?
- Kafka
Consumer가Message Broker에게 pullConsumer가 처리할 수 있을 때! 메시지를 가져온다. => 자원의 효율적 사용Kafka는 메시지를 애초디스크에 저장하고 이미 처리한 과거의offset으로 자유롭게 움직이므로batch와 같은 큰 작업에서 낭비와 지연이 없다.
- trade-off (모순)
- pull 방식의 단점으로 데이터가 없어도 정기적인 polling으로 인한 자원 낭비
- But, 실제 데이터가 도달할 때까지
long poll 대기가 가능한parameter지원
🧦4. Replication
Topic을 생성할 때, 옵션(--replication-factor)을 부여하면 복제본을 생성할 수 있다.Replication:Zookeeper가leader가 되는Partition을 정하고, 해당Partition을 다른Broker로 복제하는 것. 이 때,leader를 복제하는Partition을follower라고 한다.leader: 메시지를 생산하고 소비하는 작업은 모두leader에서 이뤄짐follower:leader를 복제만 함.- 고가용성을 위한 것.
- ex)
leader가 죽으면follower중 하나가leader가 되어야 한다. (follower는leader와 싱크를 맞추고 있다. (= In-Sync Replica, ISR))
- ex)
- 예제) 3대의
Broker, 1개의Topic, 4개의Partition
--replication-factor=2로 설정, => 각Partition들이factor값만큼Broker에 분배됨- Zookeeper가 Partition을 골고루 분배해준다.
- ex) 파티션 1에 메시지를 쓸 때,
leader가 존재하는 브로커 2에서 메시지가 생산된다. 브로커 3에 있는follower가leader를 복제 (ISR)- 만약,
leader가 다운되면,follower가 새로운leader로 선출된다. - 만약,
follower가 여러 개일 경우에는 Zookeeper가 leader를 알아서 선출
- 만약,

🛒5. 그 외
- 메시지 보존 기간
- 클러스터는 쓰여진 메시지를 보존 기간동안 유지
- 옵션
log.retention.hours를 통해 설정,default는 7일 - ex) 2일이면 2일 뒤, 공간 확보를 위해 해당 메시지 폐기
- 데이터 크기에 상관없이 카프카의 성능은 일정하기 때문에 장기간 저장해도 문제는 없습니다.
- 옵션
Consumer가 메시지를 소비한다고 메시지가 없어지는 것이 아니라, 메시지 보존 기간이 끝나야 사라진다.Consumer가 과거의offset에 대한 접근 가능의 이유
- 클러스터는 쓰여진 메시지를 보존 기간동안 유지
- 파티션 갯수와 메시지 순서 보장에 대한 이해는 아래 사이트를 참고해보자

열심히 해보자9999