자바에서는 데이터를 저장하고 조작하기 위한 자료구조를 Collection으로 제공합니다. 앞서 살펴봤던 선형구조의 자료구조뿐만 아니라
Set,Map등도 살펴볼 예정입니다.
Java Collection
- 자바에서 자료구조를 편하게 관리 및 조작하기 위해 제공해주는 인터페이스
- 구조 (
-: 연관관계)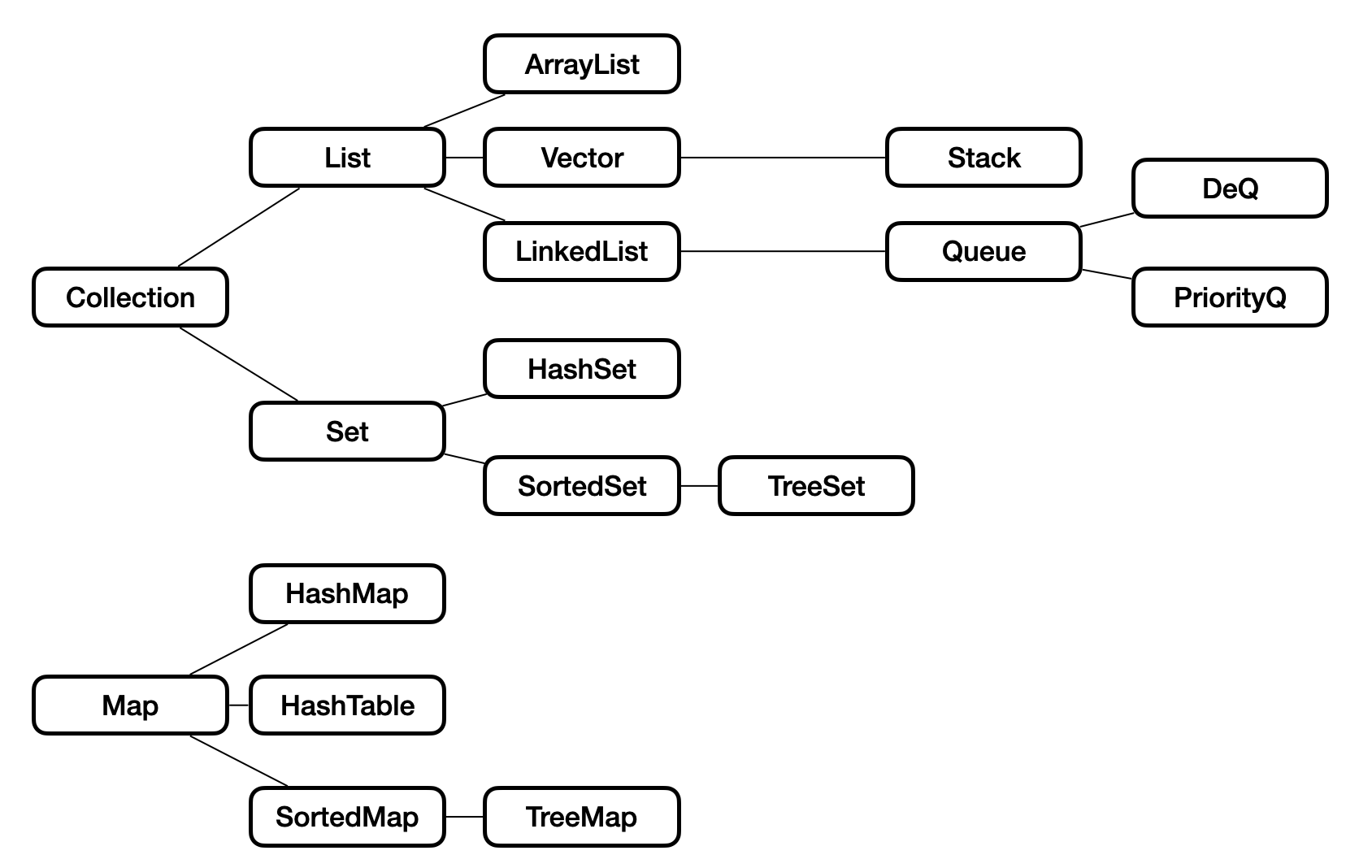
- Collection은
value를 나열하며, Map은key-value쌍으로 이루어져 있습니다. - Collection과 Map 모두 참조 자료형(객체)만 저장하고 이용할 수 있습니다. 기본 자료형의 경우 Wrapper Class를 활용하여 사용합니다.
기본 자료형 (pirmitive type)
- 문자형 :
char - 정수형 :
byte,short,int,long - 실수형 :
float,double - 논리형 :
boolean
Wrapper Class로 기본 자료형을 참조 자료형의 형태로 변환- 문자형 :
Character(특수) - 정수형 :
Byte,Short,Integer(특수),Long - 실수형 :
Float,Double - 논리형 :
Boolean
- 문자형 :
List
- 특징
- 데이터 중복 가능
- 순서 유지
- 인덱스 활용 가능
- 종류
ArrayListVectorLinkedList
ArrayList
- List의 구현 클래스
- 특징
- 인덱스 활용 (객체는 인덱스로 관리)
- 동적 크기 (vs 배열, 크기를 지정하여 생성하기 때문에 고정적)
- 단점 : 시간소요 → 저장공간 부족으로 인해 ArrayList의 용량을 늘리는 경우에 확장된 ArrayList를 새로 생성하고 원래의 값들을 복사한다. 기존 ArrayList는 GC(가비지 컬렉터)에 의해 지워진다.
- 동기화 x (multi-thread 환경에 부적합)
- 예제
import java.util.ArrayList; import java.util.List; public class ListExample { public static void main(String[] args) { List<Integer> list = new ArrayList<>(); ArrayList<Integer> arrayList = new ArrayList<>(); ArrayList<Integer> arrayListFixedSize = new ArrayList<>(5); // 크기 고정(배열) ArrayList<> arrayList1 = new ArrayList<Integer>(); // 오류1 ArrayList<int> arrayList2 = new ArrayList<int>(); // 오류2 } }-
오류1 : 선언시 객체 타입을 명시해야 합니다.
-
오류2 : 기본 자료형을 사용할 수 없습니다.
import java.util.ArrayList; public class ListExample { public static void main(String[] args) { ArrayList<Integer> arrayList = new ArrayList<>(); arrayList.add(1); arrayList.add(3); arrayList.add(2); arrayList.add(4); arrayList.add(1); arrayList.add(5); System.out.println("-------------확장 for문-------------"); for (int data : arrayList) { System.out.println(data); } arrayList.remove((Integer) 4); // 2)방법 arrayList.remove(2); // 1)방법 System.out.println("-------------정수 예제-------------"); for (int index = 0; index < arrayList.size(); index++) { System.out.println("인덱스 [" + index + "]의 값 " + arrayList.get(index)); } System.out.println("-------------String 예제-------------"); ArrayList<String> stringArrayList = new ArrayList<>(); stringArrayList.add("a"); stringArrayList.add("c"); stringArrayList.add("b"); stringArrayList.add("c"); stringArrayList.add("c"); stringArrayList.remove("c"); // 2)방법 stringArrayList.remove(0); // 1)방법 for (int index = 0; index < stringArrayList.size(); index++) { System.out.println("인덱스 [" + index + "]의 값 " + stringArrayList.get(index)); } } }-------------확장 for문------------- 1 3 2 4 1 5 -------------정수 예제------------- 인덱스 [0]의 값 1 인덱스 [1]의 값 3 인덱스 [2]의 값 1 인덱스 [3]의 값 5 -------------String 예제------------- 인덱스 [0]의 값 b 인덱스 [1]의 값 c 인덱스 [2]의 값 c -
확장 for문 : 데이터를 앞에서 부터 순차적으로 탐색합니다.
int,Integer등 기본 자료형, 참조 자료형 모두 사용 가능합니다.
-
remove(): 데이터를 삭제하는 ArrayList 메서드- 1)
index를 활용한 삭제 - 2)
Object값을 활용한 삭제
- 1)
-
Vector
- ArrayList와 동일한 구조이지만, 멀티 쓰레드 환경에서 동기화 문제를 해결한다.
synchronized를 포함한 메서드로 구현되어 있기 때문에 두 개 이상의 쓰레드에서 같은 메서드를 실행할 때, 하나의 쓰레드에서 사용을 마친 뒤 다른 쓰레드에서 사용할 수 있게 된다.
- Stack
- FILO (선입후출, First In Last Out)의 자료구조
- 자바에서는 Vector를 상속받는다.
- 예제
import java.util.Stack; import java.util.Vector; public class VectorExample { public static void main(String[] args) { Stack<Integer> stack = new Stack<>(); Vector<Integer> v = new Stack<>(); stack.add(1); stack.add(2); stack.add(3); stack.add(4); while (!stack.isEmpty()) { System.out.println(stack.pop()); } } }4 3 2 1
LinkedList
- List 구현 클래스
- 구조

- 특징
- 각 인접하는 노드에 의해 관리
- 동적 크기
- 특히, 자바에서는
Queue의 구현에 많이 사용된다.
- 예제
import java.util.LinkedList; import java.util.List; import java.util.Queue; public class LinkedListExample { public static void main(String[] args) { List<Integer> list = new LinkedList<>(); LinkedList<Integer> linkedList = new LinkedList<>(); Queue<Integer> queue = new LinkedList<>(); list.add(1); list.add(2); // list.offer(3); //오류 System.out.println("-------------List-----------"); for (int num : list) { System.out.println(num); } linkedList.add(1); linkedList.add(2); linkedList.offer(3); linkedList.poll(); linkedList.remove(); System.out.println("-------------LinkedList-----------"); for (int num : linkedList) { System.out.println(num); } queue.add(1); queue.add(2); queue.offer(3); queue.poll(); queue.remove(); System.out.println("-------------Queue-----------"); for (int num : queue) { System.out.println(num); } } }-------------List----------- 1 2 -------------LinkedList----------- 3 -------------Queue----------- 3List로 선언시,offer(),poll(),peek()등의 메서드를 사용할 수 없습니다. 즉,LinkedList만의 메서드가 있습니다.<메서드 차이점> : 위의 메서드는
null에 대해서boolean값으로 처리하지만, 기존의add(),remove()는 예외 처리를 합니다.
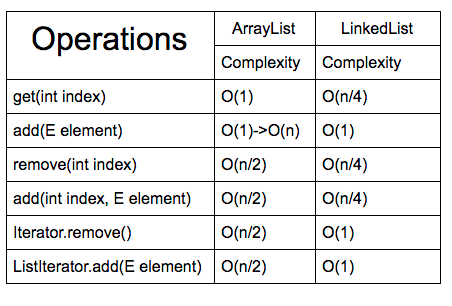
- ArrayList vs LinkedList 의 메서드 시간복잡도
Set
- 특징
- 순서 x
- 중복 x
- 인덱스 x
- 즉, 유일한 값을 갖는 데이터의 집합체
- 종류
HashSetTreeSetLinkedHashSet
HashSet
- 특징
Set의 구현체HashTable에 자료 저장- 성능 우선
- 예제
package set; import java.util.HashSet; import java.util.Iterator; public class HashSetExample { public static void main(String[] args) { HashSet<Integer> hashSet = new HashSet<>(); hashSet.add(0); hashSet.add(4); hashSet.add(5); hashSet.add(5); hashSet.add(2); hashSet.add(1); hashSet.add(3); Iterator<Integer> it = hashSet.iterator(); while (it.hasNext()) { System.out.println(it.next()); } } }0 1 2 3 4 5-
중복된 값을 넣어도 오류는 발생하지 않지만, 하나의 데이터만 저장된 모습을 볼 수 있습니다.
-
iterator를 활용하고hasNext() : boolean과next() : Object를 사용합니다.//... HashSet<String> stringHashSet = new HashSet<>(); stringHashSet.add("a"); stringHashSet.add("b"); if (stringHashSet.contains("a")) { System.out.println("존재"); } if (!stringHashSet.contains("c")) { System.out.println("존재 x"); } //...존재 존재 x -
데이터의 존재 유무를 확인할 때 유용하다. ⇒ 시간복잡도
O(1)
-
TreeSet
- 특징
Set은 순서가 유지가 되지 않지만,TreeSet의 값은 내부 정렬 알고리즘으로 인해 정렬됩니다.red-black tree타입으로 값이 저장 (레드-블랙 트리 참조)
HashSet보다 성능은 좋지 않습니다.
- 예제
import java.util.Iterator; import java.util.TreeSet; public class TreeSetExample { public static void main(String[] args) { TreeSet<String> treeSet = new TreeSet<>(); treeSet.add("a"); //97 treeSet.add("A"); //65 treeSet.add("b"); //98 treeSet.add("c"); //99 treeSet.add("0"); //48 Iterator<String> it = treeSet.iterator(); while (it.hasNext()) { String next = it.next(); System.out.println(next + " " + (int) next.charAt(0)); } } }0 48 A 65 a 97 b 98 c 99
Map
Collection은 데이터를 값(value)으로 표하는 것에 반해,Map은 키-값(key-value)으로 표현됩니다.- 특징
- 키(key) - 중복 x
- 값(value) - 중복 o
- 키, 값 모두 참조 자료형 즉, 객체입니다.
- 종류
HashMapHashTableTreeMap
HashMap
- 특징
Map의 구현체- 순서 x
- 키 중복 x, 값 중복 o
null허용 (HashTable, TreeMap과의 차이점)
- 예제 (
자주 사용하는 메서드 위주로)import java.util.*; public class HashMapExample { public static void main(String[] args) { Map<Integer, String> hm = new HashMap<>(); Map<Integer, String> ht = new Hashtable<>(); hm.put(1, "a"); hm.put(null, "b"); //ht.put(null, "b"); // 1) hm.put(3, "c"); hm.put(4, "d"); hm.put(5, "e"); hm.put(3, "f"); // 2) hm.put(0, "aa"); if (hm.containsKey(1)) { // 3) System.out.println(hm.get(1)); } if (!hm.containsKey(6)) { // 4) System.out.println(hm.get(6)); } System.out.println("-------------hm.keySet()-----------"); for (Integer integer : hm.keySet()) { System.out.println(integer); } System.out.println("-------------hm.values()-----------"); for (String value : hm.values()) { System.out.println(value); } System.out.println("-------------hm.entrySet()-----------"); for (Map.Entry<Integer, String> entry : hm.entrySet()) { System.out.println(entry); } System.out.println("-------------갯수 관련 알고리즘에 자주 사용되는 메서드(getOrDefault())-----------"); HashMap<String, Integer> hmCnt = new HashMap<>(); ArrayList<String> strs = new ArrayList<>(); strs.add("one"); strs.add("two"); strs.add("three"); strs.add("three"); for (String str : strs) { hmCnt.put(str, hmCnt.getOrDefault(str, 0) + 1); } for (Map.Entry<String, Integer> entry : hmCnt.entrySet()) { System.out.println(entry); } } }a null -------------hm.keySet()----------- null 0 1 3 4 5 -------------hm.values()----------- b aa a f d e -------------hm.entrySet()----------- null=b 0=aa 1=a 3=f 4=d 5=e -------------갯수 관련 알고리즘에 자주 사용되는 메서드(getOrDefault())----------- one=1 two=1 three=2- 주석 1)
NullPointerException발생 - 주석 2) 중복된 key 값을 삽입할 때, 최신의 값 (
3 - “c”→3 - "f")로 삽입됩니다. - 주석 3) key가 존재하는 지 확인하는 메서드 :
containsKey(K)- 주석 4) 만약 존재하지 않는다면
null리턴
- 주석 4) 만약 존재하지 않는다면
- 그 외의 것들은 주로 사용되는
HashMap의 정보를 나열하는 메서드입니다.
- 주석 1)
TreeMap은 레드-블랙 트리로 값이 저장됩니다. 또한,TreeMap,HashTable은 null 처리를 못하고 예외가 발생합니다. (따로 예제는 없습니다.)

열심히 해보자9999